 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining and Adapting Time for Multilingual Classification via Mixture of Temporal Experts
Feb 12, 2025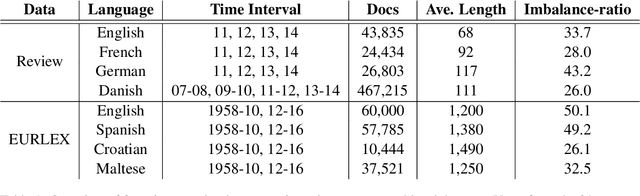
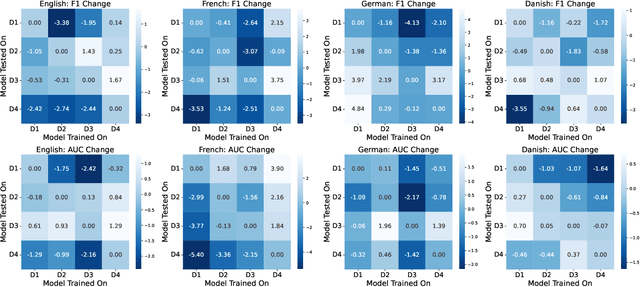
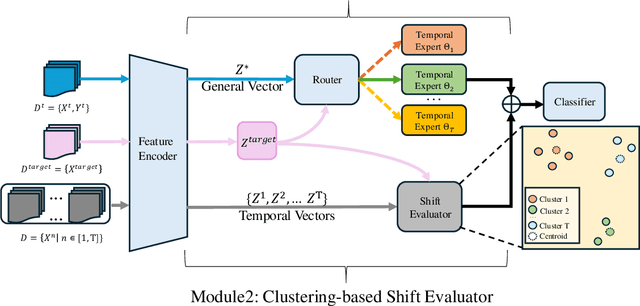
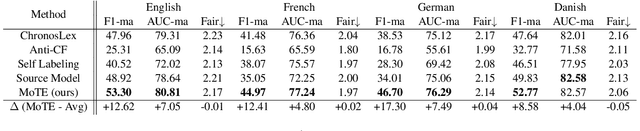
Time is implicitly embedded in classification process: classifiers are usually built on existing data while to be applied on future data whose distributions (e.g., label and token) may change. However, existing state-of-the-art classification models merely consider the temporal variations and primarily focus on English corpora, which leaves temporal studies less explored, let alone under multilingual settings. In this study, we fill the gap by treating time as domains (e.g., 2024 vs. 2025), examining temporal effects, and developing a domain adaptation framework to generalize classifiers over time on multiple languages. Our framework proposes Mixture of Temporal Experts (MoTE) to leverage both semantic and data distributional shifts to learn and adapt temporal trends into classification models. Our analysis shows classification performance varies over time across different languages, and we experimentally demonstrate that MoTE can enhance classifier generalizability over temporal data shifts. Our study provides analytic insights and addresses the need for time-aware models that perform robustly in multilingual scenarios.
Can MLLMs Understand the Deep Implication Behind Chinese Images?
Oct 17, 2024
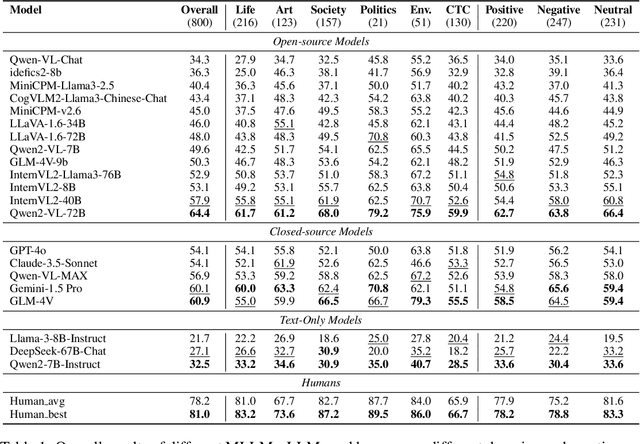
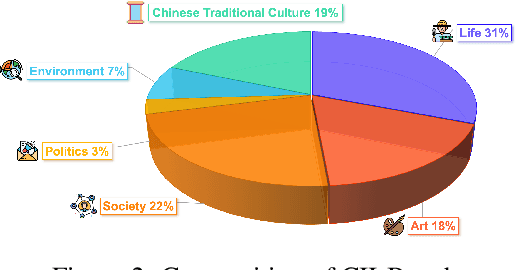
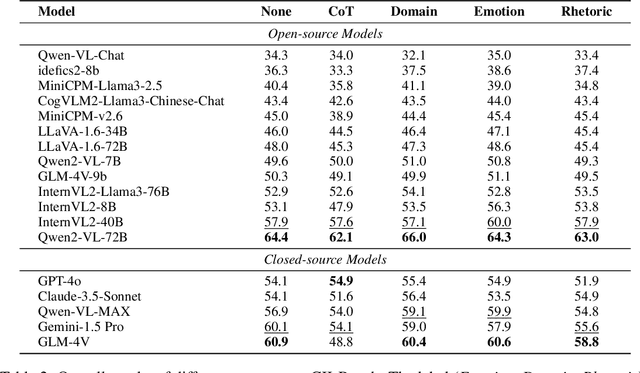
As the capabilities of Multimodal Large Language Models (MLLMs) continue to improve, the need for higher-order capability evaluation of MLLMs is increasing. However, there is a lack of work evaluating MLLM for higher-order perception and understanding of Chinese visual content. To fill the gap, we introduce the **C**hinese **I**mage **I**mplication understanding **Bench**mark, **CII-Bench**, which aims to assess the higher-order perception and understanding capabilities of MLLMs for Chinese images. CII-Bench stands out in several ways compared to existing benchmarks. Firstly, to ensure the authenticity of the Chinese context, images in CII-Bench are sourced from the Chinese Internet and manually reviewed, with corresponding answers also manually crafted. Additionally, CII-Bench incorporates images that represent Chinese traditional culture, such as famous Chinese traditional paintings, which can deeply reflect the model's understanding of Chinese traditional culture. Through extensive experiments on CII-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on CII-Bench. The highest accuracy of MLLMs attains 64.4%, where as human accuracy averages 78.2%, peaking at an impressive 81.0%. Subsequently, MLLMs perform worse on Chinese traditional culture images, suggesting limitations in their ability to understand high-level semantics and lack a deep knowledge base of Chinese traditional culture. Finally, it is observed that most models exhibit enhanced accuracy when image emotion hints are incorporated into the prompts. We believe that CII-Bench will enable MLLMs to gain a better understanding of Chinese semantics and Chinese-specific images, advancing the journey towards expert artificial general intelligence (AGI). Our project is publicly available at https://cii-bench.github.io/.
Length-Aware Multi-Kernel Transformer for Long Document Classification
May 11, 2024Lengthy documents pose a unique challenge to neural language models due to substantial memory consumption. While existing state-of-the-art (SOTA) models segment long texts into equal-length snippets (e.g., 128 tokens per snippet) or deploy sparse attention networks, these methods have new challenges of context fragmentation and generalizability due to sentence boundaries and varying text lengths. For example, our empirical analysis has shown that SOTA models consistently overfit one set of lengthy documents (e.g., 2000 tokens) while performing worse on texts with other lengths (e.g., 1000 or 4000). In this study, we propose a Length-Aware Multi-Kernel Transformer (LAMKIT) to address the new challenges for the long document classification. LAMKIT encodes lengthy documents by diverse transformer-based kernels for bridging context boundaries and vectorizes text length by the kernels to promote model robustness over varying document lengths. Experiments on five standard benchmarks from health and law domains show LAMKIT outperforms SOTA models up to an absolute 10.9% improvement. We conduct extensive ablation analyses to examine model robustness and effectiveness over varying document lengths.
Chain-of-Interaction: Enhancing Large Language Models for Psychiatric Behavior Understanding by Dyadic Contexts
Mar 23, 2024
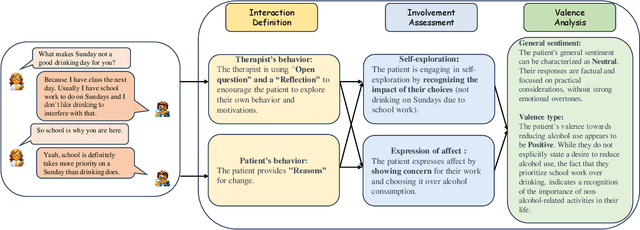


Automatic coding patient behaviors is essential to support decision making for psychotherapists during the motivational interviewing (MI), a collaborative communication intervention approach to address psychiatric issues, such as alcohol and drug addiction. While the behavior coding task has rapidly adapted machine learning to predict patient states during the MI sessions, lacking of domain-specific knowledge and overlooking patient-therapist interactions are major challenges in developing and deploying those models in real practice. To encounter those challenges, we introduce the Chain-of-Interaction (CoI) prompting method aiming to contextualize large language models (LLMs) for psychiatric decision support by the dyadic interactions. The CoI prompting approach systematically breaks down the coding task into three key reasoning steps, extract patient engagement, learn therapist question strategies, and integrates dyadic interactions between patients and therapists. This approach enables large language models to leverage the coding scheme, patient state, and domain knowledge for patient behavioral coding. Experiments on real-world datasets can prove the effectiveness and flexibility of our prompting method with multiple state-of-the-art LLMs over existing prompting baselines. We have conducted extensive ablation analysis and demonstrate the critical role of dyadic interactions in applying LLMs for psychotherapy behavior understanding.