 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Body Parsing and Pose Estimation for Enhancing Infant General Movement Assessment
Oct 14, 2022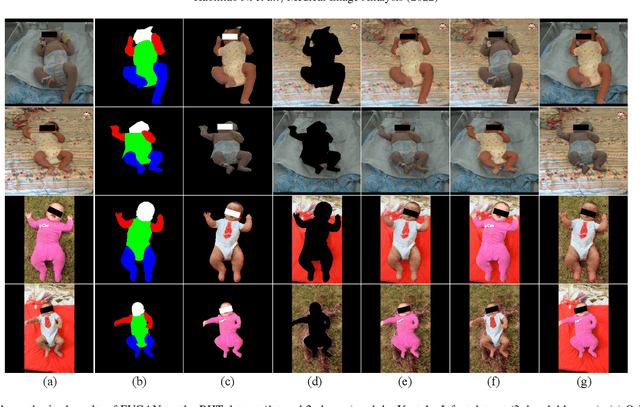
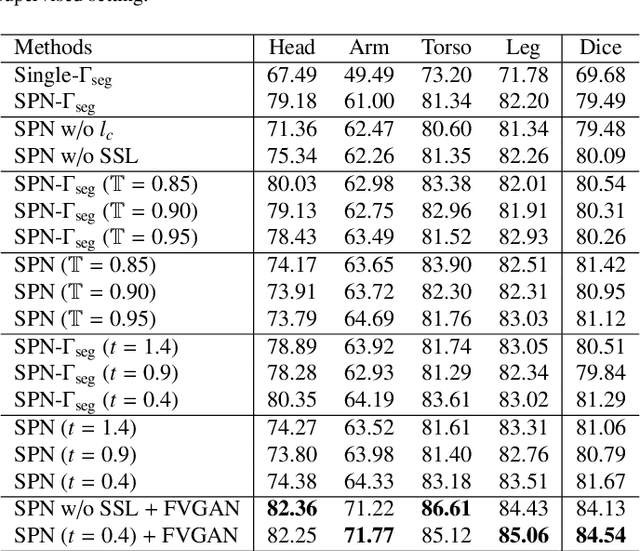
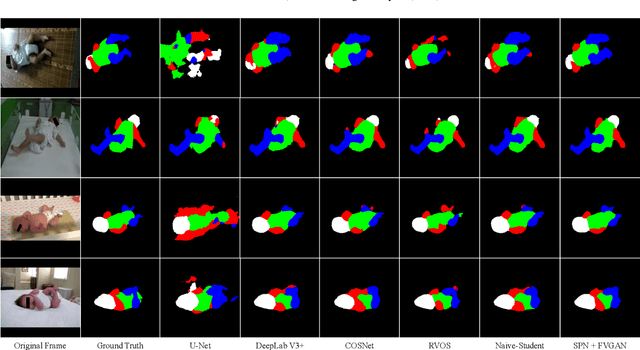
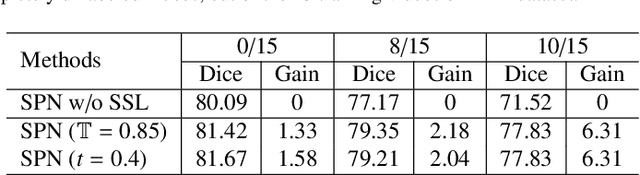
General movement assessment (GMA) of infant movement videos (IMVs) is an effective method for early detection of cerebral palsy (CP) in infants. We demonstrate in this paper that end-to-end trainable neural networks for image sequence recognition can be applied to achieve good results in GMA, and more importantly, augmenting raw video with infant body parsing and pose estimation information can significantly improve performance. To solve the problem of efficiently utilizing partially labeled IMVs for body parsing, we propose a semi-supervised model, termed SiamParseNet (SPN), which consists of two branches, one for intra-frame body parts segmentation and another for inter-frame label propagation. During training, the two branches are jointly trained by alternating between using input pairs of only labeled frames and input of both labeled and unlabeled frames. We also investigate training data augmentation by proposing a factorized video generative adversarial network (FVGAN) to synthesize novel labeled frames for training. When testing, we employ a multi-source inference mechanism, where the final result for a test frame is either obtained via the segmentation branch or via propagation from a nearby key frame. We conduct extensive experiments for body parsing using SPN on two infant movement video datasets, where SPN coupled with FVGAN achieves state-of-the-art performance. We further demonstrate that SPN can be easily adapted to the infant pose estimation task with superior performance. Last but not least, we explore the clinical application of our method for GMA. We collected a new clinical IMV dataset with GMA annotations, and our experiments show that SPN models for body parsing and pose estimation trained on the first two datasets generalize well to the new clinical dataset and their results can significantly boost the CRNN-based GMA prediction performance.
AggPose: Deep Aggregation Vision Transformer for Infant Pose Estimation
May 11, 2022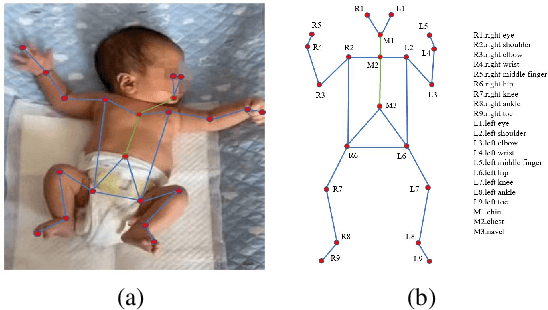


Movement and pose assessment of newborns lets experienced pediatricians predict neurodevelopmental disorders, allowing early intervention for related diseases. However, most of the newest AI approaches for human pose estimation methods focus on adults, lacking publicly benchmark for infant pose estimation. In this paper, we fill this gap by proposing infant pose dataset and Deep Aggregation Vision Transformer for human pose estimation, which introduces a fast trained full transformer framework without using convolution operations to extract features in the early stages. It generalizes Transformer + MLP to high-resolution deep layer aggregation within feature maps, thus enabling information fusion between different vision levels. We pre-train AggPose on COCO pose dataset and apply it on our newly released large-scale infant pose estimation dataset. The results show that AggPose could effectively learn the multi-scale features among different resolutions and significantly improve the performance of infant pose estimation. We show that AggPose outperforms hybrid model HRFormer and TokenPose in the infant pose estimation dataset. Moreover, our AggPose outperforms HRFormer by 0.7% AP on COCO val pose estimation on average. Our code is available at github.com/SZAR-LAB/AggPose.