 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRS-MOCO: A deep learning-based topology-preserving image registration method for cardiac T1 mapping
Oct 15, 2024



Cardiac T1 mapping can evaluate various clinical symptoms of myocardial tissue. However, there is currently a lack of effective, robust, and efficient methods for motion correction in cardiac T1 mapping. In this paper, we propose a deep learning-based and topology-preserving image registration framework for motion correction in cardiac T1 mapping. Notably, our proposed implicit consistency constraint dubbed BLOC, to some extent preserves the image topology in registration by bidirectional consistency constraint and local anti-folding constraint. To address the contrast variation issue, we introduce a weighted image similarity metric for multimodal registration of cardiac T1-weighted images. Besides, a semi-supervised myocardium segmentation network and a dual-domain attention module are integrated into the framework to further improve the performance of the registration. Numerous comparative experiments, as well as ablation studies, demonstrated the effectiveness and high robustness of our method. The results also indicate that the proposed weighted image similarity metric, specifically crafted for our network, contributes a lot to the enhancement of the motion correction efficacy, while the bidirectional consistency constraint combined with the local anti-folding constraint ensures a more desirable topology-preserving registration mapping.
ViTASD: Robust Vision Transformer Baselines for Autism Spectrum Disorder Facial Diagnosis
Oct 30, 2022



Autism spectrum disorder (ASD) is a lifelong neurodevelopmental disorder with very high prevalence around the world. Research progress in the field of ASD facial analysis in pediatric patients has been hindered due to a lack of well-established baselines. In this paper, we propose the use of the Vision Transformer (ViT) for the computational analysis of pediatric ASD. The presented model, known as ViTASD, distills knowledge from large facial expression datasets and offers model structure transferability. Specifically, ViTASD employs a vanilla ViT to extract features from patients' face images and adopts a lightweight decoder with a Gaussian Process layer to enhance the robustness for ASD analysis. Extensive experiments conducted on standard ASD facial analysis benchmarks show that our method outperforms all of the representative approaches in ASD facial analysis, while the ViTASD-L achieves a new state-of-the-art. Our code and pretrained models are available at https://github.com/IrohXu/ViTASD.
AggPose: Deep Aggregation Vision Transformer for Infant Pose Estimation
May 11, 2022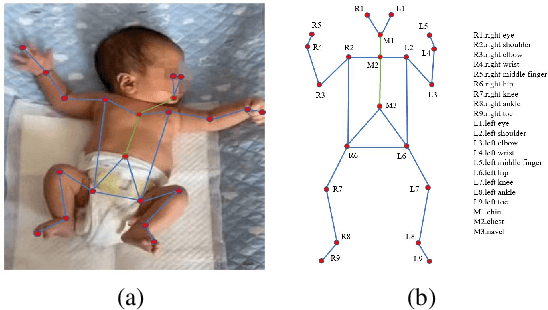

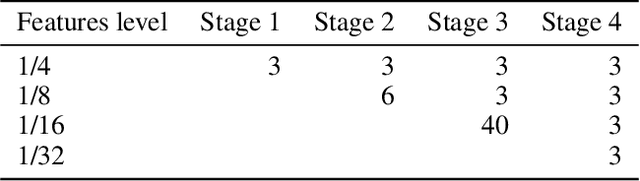

Movement and pose assessment of newborns lets experienced pediatricians predict neurodevelopmental disorders, allowing early intervention for related diseases. However, most of the newest AI approaches for human pose estimation methods focus on adults, lacking publicly benchmark for infant pose estimation. In this paper, we fill this gap by proposing infant pose dataset and Deep Aggregation Vision Transformer for human pose estimation, which introduces a fast trained full transformer framework without using convolution operations to extract features in the early stages. It generalizes Transformer + MLP to high-resolution deep layer aggregation within feature maps, thus enabling information fusion between different vision levels. We pre-train AggPose on COCO pose dataset and apply it on our newly released large-scale infant pose estimation dataset. The results show that AggPose could effectively learn the multi-scale features among different resolutions and significantly improve the performance of infant pose estimation. We show that AggPose outperforms hybrid model HRFormer and TokenPose in the infant pose estimation dataset. Moreover, our AggPose outperforms HRFormer by 0.7% AP on COCO val pose estimation on average. Our code is available at github.com/SZAR-LAB/AggPose.