 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreativeVR: Diffusion-Prior-Guided Approach for Structure and Motion Restoration in Generative and Real Videos
Dec 12, 2025Modern text-to-video (T2V) diffusion models can synthesize visually compelling clips, yet they remain brittle at fine-scale structure: even state-of-the-art generators often produce distorted faces and hands, warped backgrounds, and temporally inconsistent motion. Such severe structural artifacts also appear in very low-quality real-world videos. Classical video restoration and super-resolution (VR/VSR) methods, in contrast, are tuned for synthetic degradations such as blur and downsampling and tend to stabilize these artifacts rather than repair them, while diffusion-prior restorers are usually trained on photometric noise and offer little control over the trade-off between perceptual quality and fidelity. We introduce CreativeVR, a diffusion-prior-guided video restoration framework for AI-generated (AIGC) and real videos with severe structural and temporal artifacts. Our deep-adapter-based method exposes a single precision knob that controls how strongly the model follows the input, smoothly trading off between precise restoration on standard degradations and stronger structure- and motion-corrective behavior on challenging content. Our key novelty is a temporally coherent degradation module used during training, which applies carefully designed transformations that produce realistic structural failures. To evaluate AIGC-artifact restoration, we propose the AIGC54 benchmark with FIQA, semantic and perceptual metrics, and multi-aspect scoring. CreativeVR achieves state-of-the-art results on videos with severe artifacts and performs competitively on standard video restoration benchmarks, while running at practical throughput (about 13 FPS at 720p on a single 80-GB A100). Project page: https://daveishan.github.io/creativevr-webpage/.
Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization
Aug 12, 2025

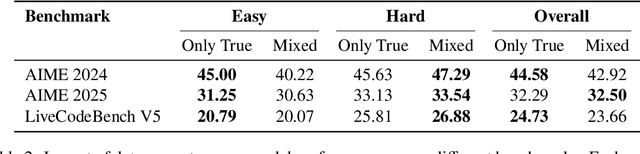

We present Klear-Reasoner, a model with long reasoning capabilities that demonstrates careful deliberation during problem solving, achieving outstanding performance across multiple benchmarks. Although there are already many excellent works related to inference models in the current community, there are still many problems with reproducing high-performance inference models due to incomplete disclosure of training details. This report provides an in-depth analysis of the reasoning model, covering the entire post-training workflow from data preparation and long Chain-of-Thought supervised fine-tuning (long CoT SFT) to reinforcement learning (RL), along with detailed ablation studies for each experimental component. For SFT data, our experiments show that a small number of high-quality data sources are more effective than a large number of diverse data sources, and that difficult samples can achieve better results without accuracy filtering. In addition, we investigate two key issues with current clipping mechanisms in RL: Clipping suppresses critical exploration signals and ignores suboptimal trajectories. To address these challenges, we propose Gradient-Preserving clipping Policy Optimization (GPPO) that gently backpropagates gradients from clipped tokens. GPPO not only enhances the model's exploration capacity but also improves its efficiency in learning from negative samples. Klear-Reasoner exhibits exceptional reasoning abilities in mathematics and programming, scoring 90.5% on AIME 2024, 83.2% on AIME 2025, 66.0% on LiveCodeBench V5 and 58.1% on LiveCodeBench V6.
Towards Understanding Camera Motions in Any Video
Apr 21, 2025
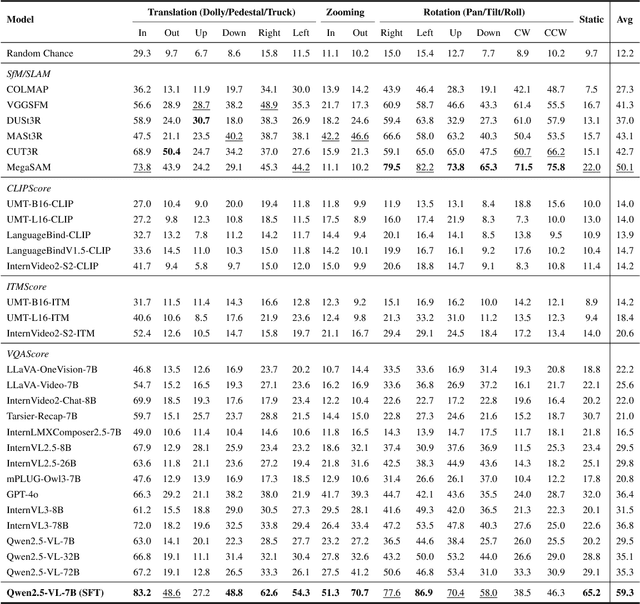
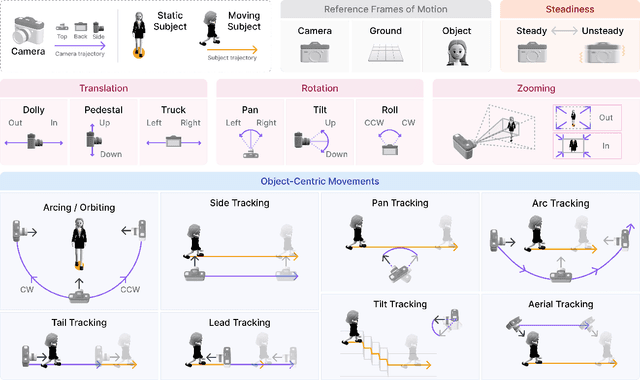
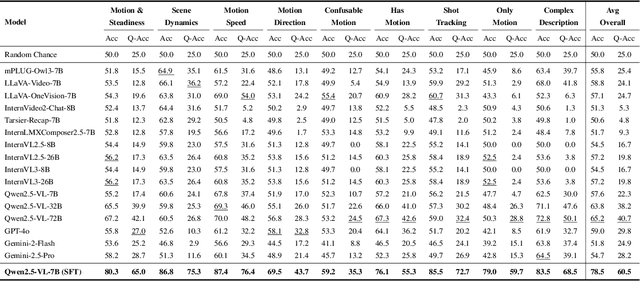
We introduce CameraBench, a large-scale dataset and benchmark designed to assess and improve camera motion understanding. CameraBench consists of ~3,000 diverse internet videos, annotated by experts through a rigorous multi-stage quality control process. One of our contributions is a taxonomy of camera motion primitives, designed in collaboration with cinematographers. We find, for example, that some motions like "follow" (or tracking) require understanding scene content like moving subjects. We conduct a large-scale human study to quantify human annotation performance, revealing that domain expertise and tutorial-based training can significantly enhance accuracy. For example, a novice may confuse zoom-in (a change of intrinsics) with translating forward (a change of extrinsics), but can be trained to differentiate the two. Using CameraBench, we evaluate Structure-from-Motion (SfM) and Video-Language Models (VLMs), finding that SfM models struggle to capture semantic primitives that depend on scene content, while VLMs struggle to capture geometric primitives that require precise estimation of trajectories. We then fine-tune a generative VLM on CameraBench to achieve the best of both worlds and showcase its applications, including motion-augmented captioning, video question answering, and video-text retrieval. We hope our taxonomy, benchmark, and tutorials will drive future efforts towards the ultimate goal of understanding camera motions in any video.
Towards Efficient Real-Time Video Motion Transfer via Generative Time Series Modeling
Apr 07, 2025We propose a deep learning framework designed to significantly optimize bandwidth for motion-transfer-enabled video applications, including video conferencing, virtual reality interactions, health monitoring systems, and vision-based real-time anomaly detection. To capture complex motion effectively, we utilize the First Order Motion Model (FOMM), which encodes dynamic objects by detecting keypoints and their associated local affine transformations. These keypoints are identified using a self-supervised keypoint detector and arranged into a time series corresponding to the successive frames. Forecasting is performed on these keypoints by integrating two advanced generative time series models into the motion transfer pipeline, namely the Variational Recurrent Neural Network (VRNN) and the Gated Recurrent Unit with Normalizing Flow (GRU-NF). The predicted keypoints are subsequently synthesized into realistic video frames using an optical flow estimator paired with a generator network, thereby facilitating accurate video forecasting and enabling efficient, low-frame-rate video transmission. We validate our results across three datasets for video animation and reconstruction using the following metrics: Mean Absolute Error, Joint Embedding Predictive Architecture Embedding Distance, Structural Similarity Index, and Average Pair-wise Displacement. Our results confirm that by utilizing the superior reconstruction property of the Variational Autoencoder, the VRNN integrated FOMM excels in applications involving multi-step ahead forecasts such as video conferencing. On the other hand, by leveraging the Normalizing Flow architecture for exact likelihood estimation, and enabling efficient latent space sampling, the GRU-NF based FOMM exhibits superior capabilities for producing diverse future samples while maintaining high visual quality for tasks like real-time video-based anomaly detection.
MaskMoE: Boosting Token-Level Learning via Routing Mask in Mixture-of-Experts
Jul 13, 2024Scaling model capacity enhances its capabilities but significantly increases computation. Mixture-of-Experts models (MoEs) address this by allowing model capacity to scale without substantially increasing training or inference costs. Despite their promising results, MoE models encounter several challenges. Primarily, the dispersion of training tokens across multiple experts can lead to underfitting, particularly for infrequent tokens. Additionally, while fixed routing mechanisms can mitigate this issue, they compromise on the diversity of representations. In this paper, we propose MaskMoE, a method designed to enhance token-level learning by employing a routing masking technique within the Mixture-of-Experts model. MaskMoE is capable of maintaining representation diversity while achieving more comprehensive training. Experimental results demonstrate that our method outperforms previous dominant Mixture-of-Experts models in both perplexity (PPL) and downstream tasks.
Enhancing Bandwidth Efficiency for Video Motion Transfer Applications using Deep Learning Based Keypoint Prediction
Mar 17, 2024We propose a deep learning based novel prediction framework for enhanced bandwidth reduction in motion transfer enabled video applications such as video conferencing, virtual reality gaming and privacy preservation for patient health monitoring. To model complex motion, we use the First Order Motion Model (FOMM) that represents dynamic objects using learned keypoints along with their local affine transformations. Keypoints are extracted by a self-supervised keypoint detector and organized in a time series corresponding to the video frames. Prediction of keypoints, to enable transmission using lower frames per second on the source device, is performed using a Variational Recurrent Neural Network (VRNN). The predicted keypoints are then synthesized to video frames using an optical flow estimator and a generator network. This efficacy of leveraging keypoint based representations in conjunction with VRNN based prediction for both video animation and reconstruction is demonstrated on three diverse datasets. For real-time applications, our results show the effectiveness of our proposed architecture by enabling up to 2x additional bandwidth reduction over existing keypoint based video motion transfer frameworks without significantly compromising video quality.
InfoEntropy Loss to Mitigate Bias of Learning Difficulties for Generative Language Models
Nov 01, 2023



Generative language models are usually pretrained on large text corpus via predicting the next token (i.e., sub-word/word/phrase) given the previous ones. Recent works have demonstrated the impressive performance of large generative language models on downstream tasks. However, existing generative language models generally neglect an inherent challenge in text corpus during training, i.e., the imbalance between frequent tokens and infrequent ones. It can lead a language model to be dominated by common and easy-to-learn tokens, thereby overlooking the infrequent and difficult-to-learn ones. To alleviate that, we propose an Information Entropy Loss (InfoEntropy Loss) function. During training, it can dynamically assess the learning difficulty of a to-be-learned token, according to the information entropy of the corresponding predicted probability distribution over the vocabulary. Then it scales the training loss adaptively, trying to lead the model to focus more on the difficult-to-learn tokens. On the Pile dataset, we train generative language models at different scales of 436M, 1.1B, and 6.7B parameters. Experiments reveal that models incorporating the proposed InfoEntropy Loss can gain consistent performance improvement on downstream benchmarks.
Gated Driver Attention Predictor
Aug 01, 2023Driver attention prediction implies the intention understanding of where the driver intends to go and what object the driver concerned about, which commonly provides a driving task-guided traffic scene understanding. Some recent works explore driver attention prediction in critical or accident scenarios and find a positive role in helping accident prediction, while the promotion ability is constrained by the prediction accuracy of driver attention maps. In this work, we explore the network connection gating mechanism for driver attention prediction (Gate-DAP). Gate-DAP aims to learn the importance of different spatial, temporal, and modality information in driving scenarios with various road types, occasions, and light and weather conditions. The network connection gating in Gate-DAP consists of a spatial encoding network gating, long-short-term memory network gating, and information type gating modules. Each connection gating operation is plug-and-play and can be flexibly assembled, which makes the architecture of Gate-DAP transparent for evaluating different spatial, temporal, and information types for driver attention prediction. Evaluations on DADA-2000 and BDDA datasets verify the superiority of the proposed method with the comparison with state-of-the-art approaches. The code is available on https://github.com/JWFangit/Gate-DAP.
ViTASD: Robust Vision Transformer Baselines for Autism Spectrum Disorder Facial Diagnosis
Oct 30, 2022



Autism spectrum disorder (ASD) is a lifelong neurodevelopmental disorder with very high prevalence around the world. Research progress in the field of ASD facial analysis in pediatric patients has been hindered due to a lack of well-established baselines. In this paper, we propose the use of the Vision Transformer (ViT) for the computational analysis of pediatric ASD. The presented model, known as ViTASD, distills knowledge from large facial expression datasets and offers model structure transferability. Specifically, ViTASD employs a vanilla ViT to extract features from patients' face images and adopts a lightweight decoder with a Gaussian Process layer to enhance the robustness for ASD analysis. Extensive experiments conducted on standard ASD facial analysis benchmarks show that our method outperforms all of the representative approaches in ASD facial analysis, while the ViTASD-L achieves a new state-of-the-art. Our code and pretrained models are available at https://github.com/IrohXu/ViTASD.
A Two-Stage Approach to Device-Robust Acoustic Scene Classification
Nov 03, 2020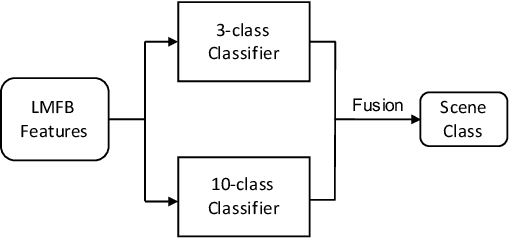

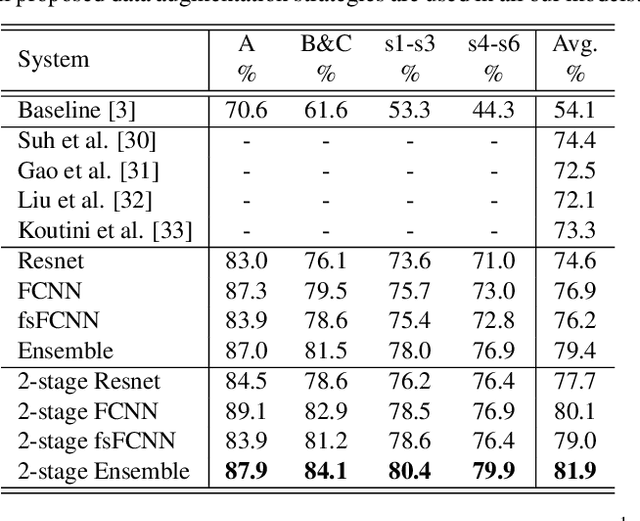
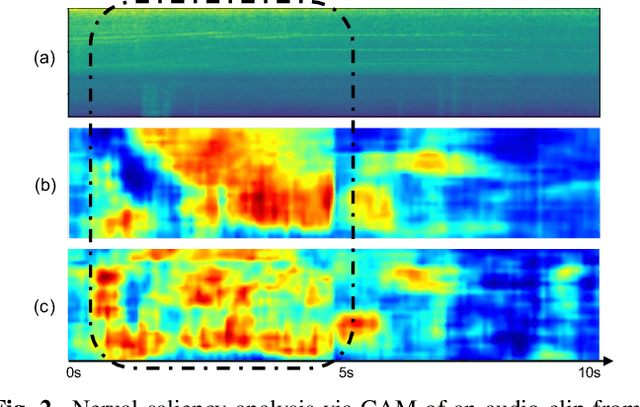
To improve device robustness, a highly desirable key feature of a competitive data-driven acoustic scene classification (ASC) system, a novel two-stage system based on fully convolutional neural networks (CNNs) is proposed. Our two-stage system leverages on an ad-hoc score combination based on two CNN classifiers: (i) the first CNN classifies acoustic inputs into one of three broad classes, and (ii) the second CNN classifies the same inputs into one of ten finer-grained classes. Three different CNN architectures are explored to implement the two-stage classifiers, and a frequency sub-sampling scheme is investigated. Moreover, novel data augmentation schemes for ASC are also investigated. Evaluated on DCASE 2020 Task 1a, our results show that the proposed ASC system attains a state-of-the-art accuracy on the development set, where our best system, a two-stage fusion of CNN ensembles, delivers a 81.9% average accuracy among multi-device test data, and it obtains a significant improvement on unseen devices. Finally, neural saliency analysis with class activation mapping (CAM) gives new insights on the patterns learnt by our models.