 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSerialized Multi-Layer Multi-Head Attention for Neural Speaker Embedding
Jul 14, 2021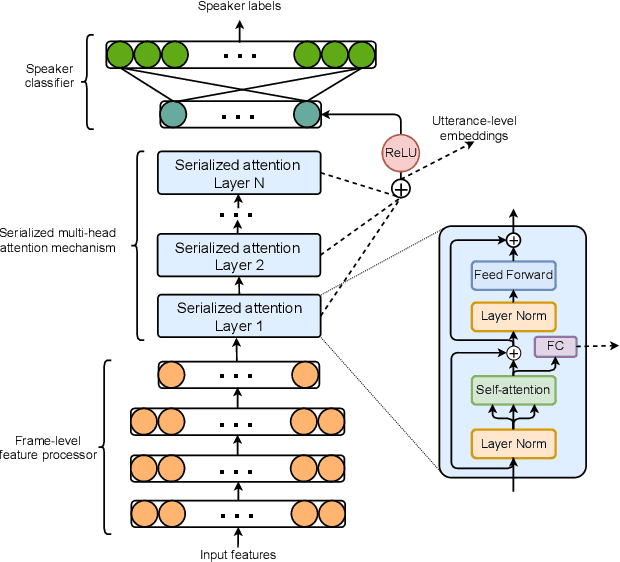

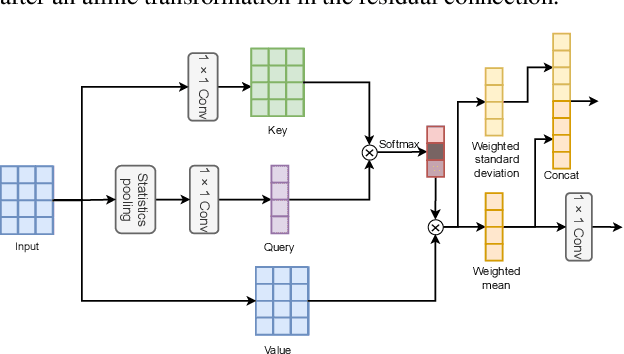
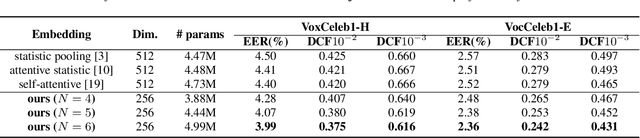
This paper proposes a serialized multi-layer multi-head attention for neural speaker embedding in text-independent speaker verification. In prior works, frame-level features from one layer are aggregated to form an utterance-level representation. Inspired by the Transformer network, our proposed method utilizes the hierarchical architecture of stacked self-attention mechanisms to derive refined features that are more correlated with speakers. Serialized attention mechanism contains a stack of self-attention modules to create fixed-dimensional representations of speakers. Instead of utilizing multi-head attention in parallel, the proposed serialized multi-layer multi-head attention is designed to aggregate and propagate attentive statistics from one layer to the next in a serialized manner. In addition, we employ an input-aware query for each utterance with the statistics pooling. With more layers stacked, the neural network can learn more discriminative speaker embeddings. Experiment results on VoxCeleb1 dataset and SITW dataset show that our proposed method outperforms other baseline methods, including x-vectors and other x-vectors + conventional attentive pooling approaches by 9.7% in EER and 8.1% in DCF0.01.
A Two-Stage Approach to Device-Robust Acoustic Scene Classification
Nov 03, 2020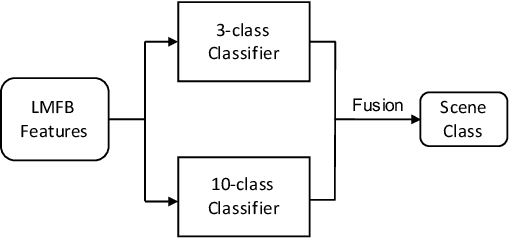

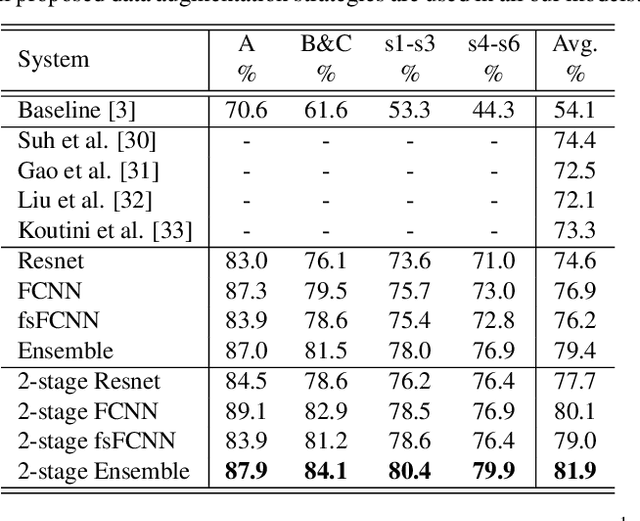
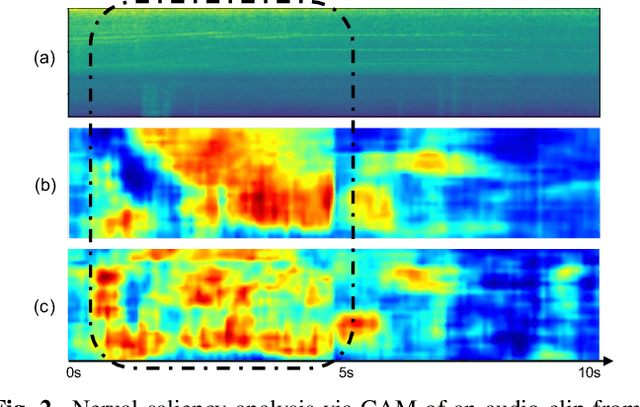
To improve device robustness, a highly desirable key feature of a competitive data-driven acoustic scene classification (ASC) system, a novel two-stage system based on fully convolutional neural networks (CNNs) is proposed. Our two-stage system leverages on an ad-hoc score combination based on two CNN classifiers: (i) the first CNN classifies acoustic inputs into one of three broad classes, and (ii) the second CNN classifies the same inputs into one of ten finer-grained classes. Three different CNN architectures are explored to implement the two-stage classifiers, and a frequency sub-sampling scheme is investigated. Moreover, novel data augmentation schemes for ASC are also investigated. Evaluated on DCASE 2020 Task 1a, our results show that the proposed ASC system attains a state-of-the-art accuracy on the development set, where our best system, a two-stage fusion of CNN ensembles, delivers a 81.9% average accuracy among multi-device test data, and it obtains a significant improvement on unseen devices. Finally, neural saliency analysis with class activation mapping (CAM) gives new insights on the patterns learnt by our models.
Device-Robust Acoustic Scene Classification Based on Two-Stage Categorization and Data Augmentation
Aug 27, 2020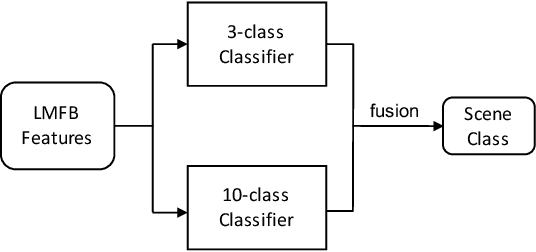
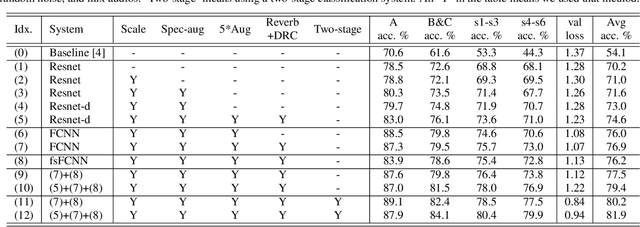
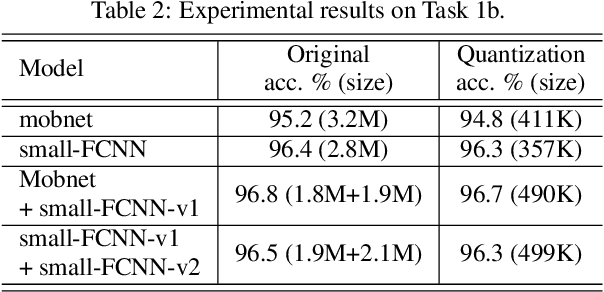
In this technical report, we present a joint effort of four groups, namely GT, USTC, Tencent, and UKE, to tackle Task 1 - Acoustic Scene Classification (ASC) in the DCASE 2020 Challenge. Task 1 comprises two different sub-tasks: (i) Task 1a focuses on ASC of audio signals recorded with multiple (real and simulated) devices into ten different fine-grained classes, and (ii) Task 1b concerns with classification of data into three higher-level classes using low-complexity solutions. For Task 1a, we propose a novel two-stage ASC system leveraging upon ad-hoc score combination of two convolutional neural networks (CNNs), classifying the acoustic input according to three classes, and then ten classes, respectively. Four different CNN-based architectures are explored to implement the two-stage classifiers, and several data augmentation techniques are also investigated. For Task 1b, we leverage upon a quantization method to reduce the complexity of two of our top-accuracy three-classes CNN-based architectures. On Task 1a development data set, an ASC accuracy of 76.9\% is attained using our best single classifier and data augmentation. An accuracy of 81.9\% is then attained by a final model fusion of our two-stage ASC classifiers. On Task 1b development data set, we achieve an accuracy of 96.7\% with a model size smaller than 500KB. Code is available: https://github.com/MihawkHu/DCASE2020_task1.