 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline
Feb 24, 2026Song generation aims to produce full songs with vocals and accompaniment from lyrics and text descriptions, yet end-to-end models remain data- and compute-intensive and provide limited editability. We advocate a compositional alternative that decomposes the task into melody composition, singing voice synthesis, and singing accompaniment generation. Central to our approach is MIDI-informed singing accompaniment generation (MIDI-SAG), which conditions accompaniment on the symbolic vocal-melody MIDI to improve rhythmic and harmonic alignment between singing and instrumentation. Moreover, beyond conventional SAG settings that assume continuously sung vocals, compositional song generation features intermittent vocals; we address this by combining explicit rhythmic/harmonic controls with audio continuation to keep the backing track consistent across vocal and non-vocal regions. With lightweight newly trained components requiring only 2.5k hours of audio on a single RTX 3090, our pipeline approaches the perceptual quality of recent open-source end-to-end baselines in several metrics. We provide audio demos and will open-source our model at https://composerflow.github.io/web/.
ImprovDML: Improved Trade-off in Private Byzantine-Resilient Distributed Machine Learning
Jun 18, 2025Jointly addressing Byzantine attacks and privacy leakage in distributed machine learning (DML) has become an important issue. A common strategy involves integrating Byzantine-resilient aggregation rules with differential privacy mechanisms. However, the incorporation of these techniques often results in a significant degradation in model accuracy. To address this issue, we propose a decentralized DML framework, named ImprovDML, that achieves high model accuracy while simultaneously ensuring privacy preservation and resilience to Byzantine attacks. The framework leverages a kind of resilient vector consensus algorithms that can compute a point within the normal (non-Byzantine) agents' convex hull for resilient aggregation at each iteration. Then, multivariate Gaussian noises are introduced to the gradients for privacy preservation. We provide convergence guarantees and derive asymptotic learning error bounds under non-convex settings, which are tighter than those reported in existing works. For the privacy analysis, we adopt the notion of concentrated geo-privacy, which quantifies privacy preservation based on the Euclidean distance between inputs. We demonstrate that it enables an improved trade-off between privacy preservation and model accuracy compared to differential privacy. Finally, numerical simulations validate our theoretical results.
Adaptive Extensive Cancellation Algorithm and Harmonic Enhanced Heart Rate Estimation based on MMWave Radar
Mar 10, 2025Heart rate (HR) monitoring is crucial for assessing physical fitness, cardiovascular health, and stress management. Millimeter-wave radar offers a promising noncontact solution for long-term monitoring. However, accurate HR estimation remains challenging in low signal-tonoise ratio (SNR) conditions. To deal with both respiration harmonics and intermodulation interference, this paper proposes a cancellation-before-estimation strategy. Firstly, we present the adaptive extensive cancellation algorithm (ECA) to suppress respiratory and its low-order harmonics. Then, we propose an adaptive harmonic enhanced trace (AHET) method to avoid intermodulation interference by refining the HR search region. Various experimental results validate the effectiveness of the proposed methods, demonstrating improvements in accuracy, robustness, and computational efficiency compared to conventional approaches based on the FMCW (Frequency Modulated Continuous Wave) system
On Random Sampling of Diffused Graph Signals with Sparse Inputs on Vertex Domain
Dec 28, 2024



The sampling of graph signals has recently drawn much attention due to the wide applications of graph signal processing. While a lot of efficient methods and interesting results have been reported to the sampling of band-limited or smooth graph signals, few research has been devoted to non-smooth graph signals, especially to sparse graph signals, which are also of importance in many practical applications. This paper addresses the random sampling of non-smooth graph signals generated by diffusion of sparse inputs. We aim to present a solid theoretical analysis on the random sampling of diffused sparse graph signals, which can be parallel to that of band-limited graph signals, and thus present a sufficient condition to the number of samples ensuring the unique recovery for uniform random sampling. Then, we focus on two classes of widely used binary graph models, and give explicit and tighter estimations on the sampling numbers ensuring unique recovery. We also propose an adaptive variable-density sampling strategy to provide a better performance than uniform random sampling. Finally, simulation experiments are presented to validate the effectiveness of the theoretical results.
Lifting Scheme-Based Implicit Disentanglement of Emotion-Related Facial Dynamics in the Wild
Dec 17, 2024



In-the-wild Dynamic facial expression recognition (DFER) encounters a significant challenge in recognizing emotion-related expressions, which are often temporally and spatially diluted by emotion-irrelevant expressions and global context respectively. Most of the prior DFER methods model tightly coupled spatiotemporal representations which may incorporate weakly relevant features, leading to information redundancy and emotion-irrelevant context bias. Several DFER methods have highlighted the significance of dynamic information, but utilize explicit manners to extract dynamic features with overly strong prior knowledge. In this paper, we propose a novel Implicit Facial Dynamics Disentanglement framework (IFDD). Through expanding wavelet lifting scheme to fully learnable framework, IFDD disentangles emotion-related dynamic information from emotion-irrelevant global context in an implicit manner, i.e., without exploit operations and external guidance. The disentanglement process of IFDD contains two stages, i.e., Inter-frame Static-dynamic Splitting Module (ISSM) for rough disentanglement estimation and Lifting-based Aggregation-Disentanglement Module (LADM) for further refinement. Specifically, ISSM explores inter-frame correlation to generate content-aware splitting indexes on-the-fly. We preliminarily utilize these indexes to split frame features into two groups, one with greater global similarity, and the other with more unique dynamic features. Subsequently, LADM first aggregates these two groups of features to obtain fine-grained global context features by an updater, and then disentangles emotion-related facial dynamic features from the global context by a predictor. Extensive experiments on in-the-wild datasets have demonstrated that IFDD outperforms prior supervised DFER methods with higher recognition accuracy and comparable efficiency.
CSL-L2M: Controllable Song-Level Lyric-to-Melody Generation Based on Conditional Transformer with Fine-Grained Lyric and Musical Controls
Dec 13, 2024



Lyric-to-melody generation is a highly challenging task in the field of AI music generation. Due to the difficulty of learning strict yet weak correlations between lyrics and melodies, previous methods have suffered from weak controllability, low-quality and poorly structured generation. To address these challenges, we propose CSL-L2M, a controllable song-level lyric-to-melody generation method based on an in-attention Transformer decoder with fine-grained lyric and musical controls, which is able to generate full-song melodies matched with the given lyrics and user-specified musical attributes. Specifically, we first introduce REMI-Aligned, a novel music representation that incorporates strict syllable- and sentence-level alignments between lyrics and melodies, facilitating precise alignment modeling. Subsequently, sentence-level semantic lyric embeddings independently extracted from a sentence-wise Transformer encoder are combined with word-level part-of-speech embeddings and syllable-level tone embeddings as fine-grained controls to enhance the controllability of lyrics over melody generation. Then we introduce human-labeled musical tags, sentence-level statistical musical attributes, and learned musical features extracted from a pre-trained VQ-VAE as coarse-grained, fine-grained and high-fidelity controls, respectively, to the generation process, thereby enabling user control over melody generation. Finally, an in-attention Transformer decoder technique is leveraged to exert fine-grained control over the full-song melody generation with the aforementioned lyric and musical conditions. Experimental results demonstrate that our proposed CSL-L2M outperforms the state-of-the-art models, generating melodies with higher quality, better controllability and enhanced structure. Demos and source code are available at https://lichaiustc.github.io/CSL-L2M/.
Frequency-Domain Refinement with Multiscale Diffusion for Super Resolution
May 16, 2024



The performance of single image super-resolution depends heavily on how to generate and complement high-frequency details to low-resolution images. Recently, diffusion-based models exhibit great potential in generating high-quality images for super-resolution tasks. However, existing models encounter difficulties in directly predicting high-frequency information of wide bandwidth by solely utilizing the high-resolution ground truth as the target for all sampling timesteps. To tackle this problem and achieve higher-quality super-resolution, we propose a novel Frequency Domain-guided multiscale Diffusion model (FDDiff), which decomposes the high-frequency information complementing process into finer-grained steps. In particular, a wavelet packet-based frequency complement chain is developed to provide multiscale intermediate targets with increasing bandwidth for reverse diffusion process. Then FDDiff guides reverse diffusion process to progressively complement the missing high-frequency details over timesteps. Moreover, we design a multiscale frequency refinement network to predict the required high-frequency components at multiple scales within one unified network. Comprehensive evaluations on popular benchmarks are conducted, and demonstrate that FDDiff outperforms prior generative methods with higher-fidelity super-resolution results.
WCCNet: Wavelet-integrated CNN with Crossmodal Rearranging Fusion for Fast Multispectral Pedestrian Detection
Aug 02, 2023



Multispectral pedestrian detection achieves better visibility in challenging conditions and thus has a broad application in various tasks, for which both the accuracy and computational cost are of paramount importance. Most existing approaches treat RGB and infrared modalities equally, typically adopting two symmetrical CNN backbones for multimodal feature extraction, which ignores the substantial differences between modalities and brings great difficulty for the reduction of the computational cost as well as effective crossmodal fusion. In this work, we propose a novel and efficient framework named WCCNet that is able to differentially extract rich features of different spectra with lower computational complexity and semantically rearranges these features for effective crossmodal fusion. Specifically, the discrete wavelet transform (DWT) allowing fast inference and training speed is embedded to construct a dual-stream backbone for efficient feature extraction. The DWT layers of WCCNet extract frequency components for infrared modality, while the CNN layers extract spatial-domain features for RGB modality. This methodology not only significantly reduces the computational complexity, but also improves the extraction of infrared features to facilitate the subsequent crossmodal fusion. Based on the well extracted features, we elaborately design the crossmodal rearranging fusion module (CMRF), which can mitigate spatial misalignment and merge semantically complementary features of spatially-related local regions to amplify the crossmodal complementary information. We conduct comprehensive evaluations on KAIST and FLIR benchmarks, in which WCCNet outperforms state-of-the-art methods with considerable computational efficiency and competitive accuracy. We also perform the ablation study and analyze thoroughly the impact of different components on the performance of WCCNet.
Optimization of Directional Landmark Deployment for Visual Observer on SE(3)
Mar 28, 2022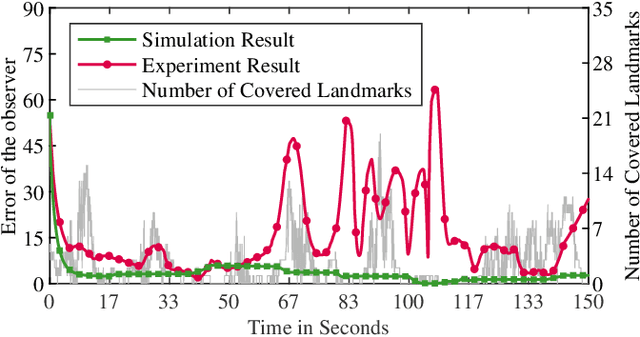
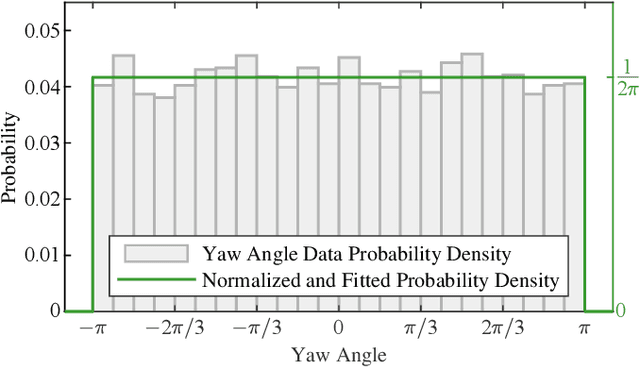
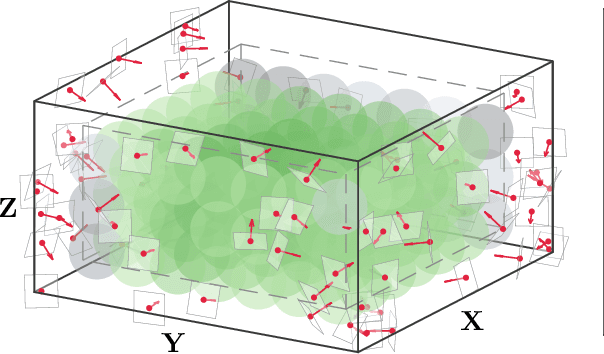

An optimization method is proposed in this paper for novel deployment of given number of directional landmarks (location and pose) within a given region in the 3-D task space. This new deployment technique is built on the geometric models of both landmarks and the monocular camera. In particular, a new concept of Multiple Coverage Probability (MCP) is defined to characterize the probability of at least n landmarks being covered simultaneously by a camera at a fixed position. The optimization is conducted with respect to the position and pose of the given number of landmarks to maximize MCP through globally exploration of the given 3-D space. By adopting the elimination genetic algorithm, the global optimal solutions can be obtained, which are then applied to improve the convergent performance of the visual observer on SE(3) as a demonstration example. Both simulation and experimental results are presented to validate the effectiveness of the proposed landmark deployment optimization method.
Coverage Optimization of Camera Network for Continuous Deformable Object
Mar 16, 2022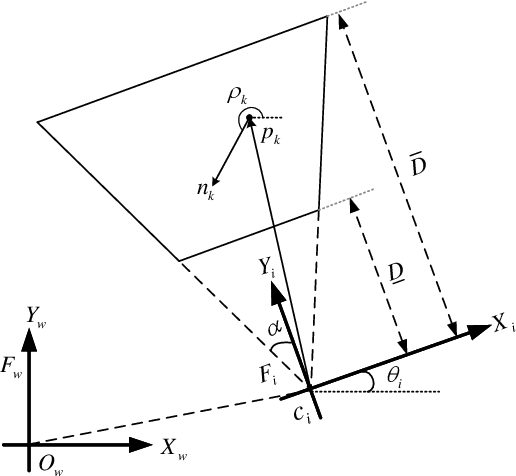
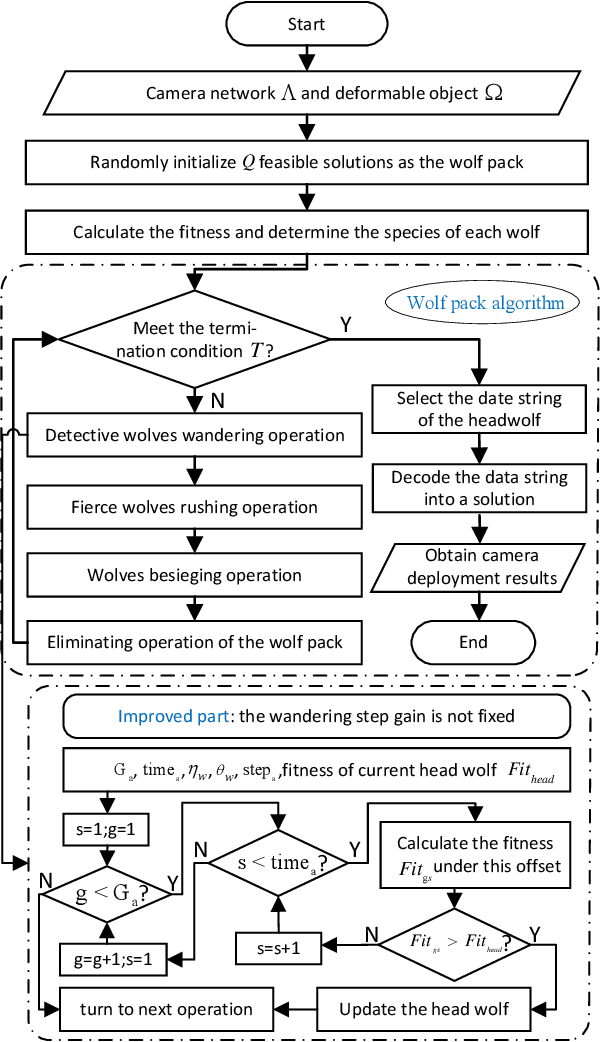
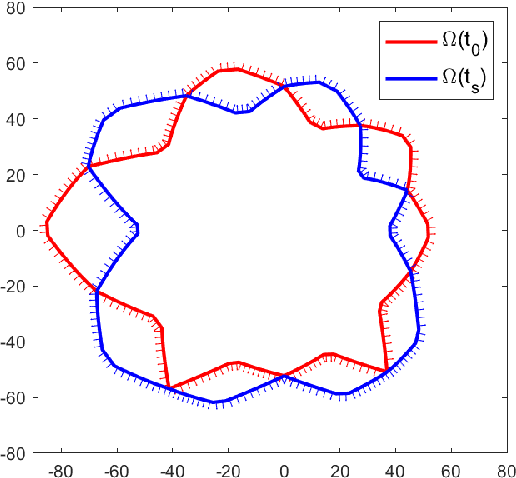
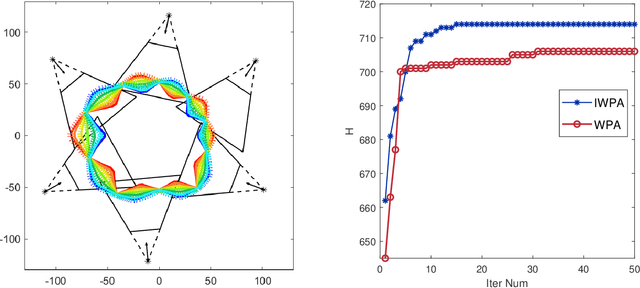
In this paper, a deformable object is considered for cameras deployment with the aim of visual coverage. The object contour is discretized into sampled points as meshes, and the deformation is represented as continuous trajectories for the sampled points. To reduce the computational complexity, some feature points are carefully selected representing the continuous deformation process, and the visual coverage for the deformable object is transferred to cover the specific feature points. In particular, the vertexes of a rectangle that can contain the entire deformation trajectory of every sampled point on the object contour are chosen as the feature points. An improved wolf pack algorithm is then proposed to solve the optimization problem. Finally, simulation results are given to demonstrate the effectiveness of the proposed deployment method of camera network.