 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Extensive Cancellation Algorithm and Harmonic Enhanced Heart Rate Estimation based on MMWave Radar
Mar 10, 2025Heart rate (HR) monitoring is crucial for assessing physical fitness, cardiovascular health, and stress management. Millimeter-wave radar offers a promising noncontact solution for long-term monitoring. However, accurate HR estimation remains challenging in low signal-tonoise ratio (SNR) conditions. To deal with both respiration harmonics and intermodulation interference, this paper proposes a cancellation-before-estimation strategy. Firstly, we present the adaptive extensive cancellation algorithm (ECA) to suppress respiratory and its low-order harmonics. Then, we propose an adaptive harmonic enhanced trace (AHET) method to avoid intermodulation interference by refining the HR search region. Various experimental results validate the effectiveness of the proposed methods, demonstrating improvements in accuracy, robustness, and computational efficiency compared to conventional approaches based on the FMCW (Frequency Modulated Continuous Wave) system
Asymmetric Deep Semantic Quantization for Image Retrieval
Mar 29, 2019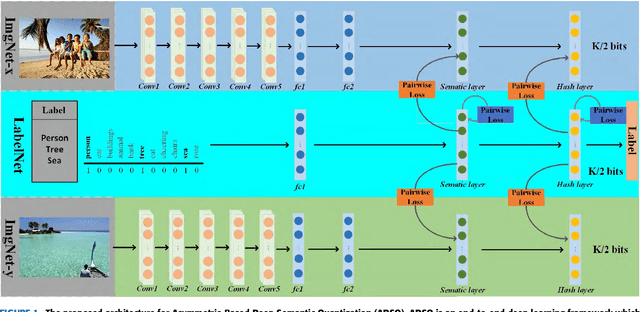
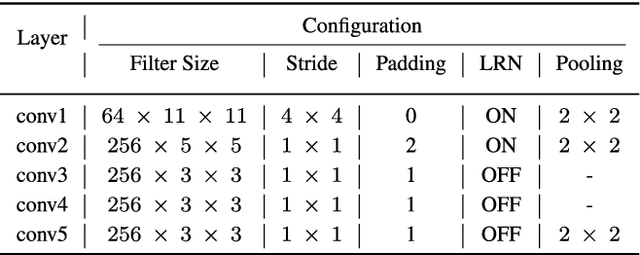

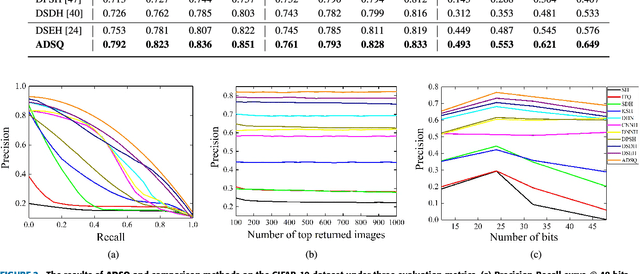
Due to its fast retrieval and storage efficiency capabilities, hashing has been widely used in nearest neighbor retrieval tasks. By using deep learning based techniques, hashing can outperform non-learning based hashing in many applications. However, there are some limitations to previous learning based hashing methods (e.g., the learned hash codes are not discriminative due to the hashing methods being unable to discover rich semantic information and the training strategy having difficulty optimizing the discrete binary codes). In this paper, we propose a novel learning based hashing method, named \textbf{\underline{A}}symmetric \textbf{\underline{D}}eep \textbf{\underline{S}}emantic \textbf{\underline{Q}}uantization (\textbf{ADSQ}). \textbf{ADSQ} is implemented using three stream frameworks, which consists of one \emph{LabelNet} and two \emph{ImgNets}. The \emph{LabelNet} leverages three fully-connected layers, which is used to capture rich semantic information between image pairs. For the two \emph{ImgNets}, they each adopt the same convolutional neural network structure, but with different weights (i.e., asymmetric convolutional neural networks). The two \emph{ImgNets} are used to generate discriminative compact hash codes. Specifically, the function of the \emph{LabelNet} is to capture rich semantic information that is used to guide the two \emph{ImgNets} in minimizing the gap between the real-continuous features and discrete binary codes. By doing this, \textbf{ADSQ} can make full use of the most critical semantic information to guide the feature learning process and consider the consistency of the common semantic space and Hamming space. Results from our experiments demonstrate that \textbf{ADSQ} can generate high discriminative compact hash codes and it outperforms current state-of-the-art methods on three benchmark datasets, CIFAR-10, NUS-WIDE, and ImageNet.
Dual Residual Network for Accurate Human Activity Recognition
Mar 13, 2019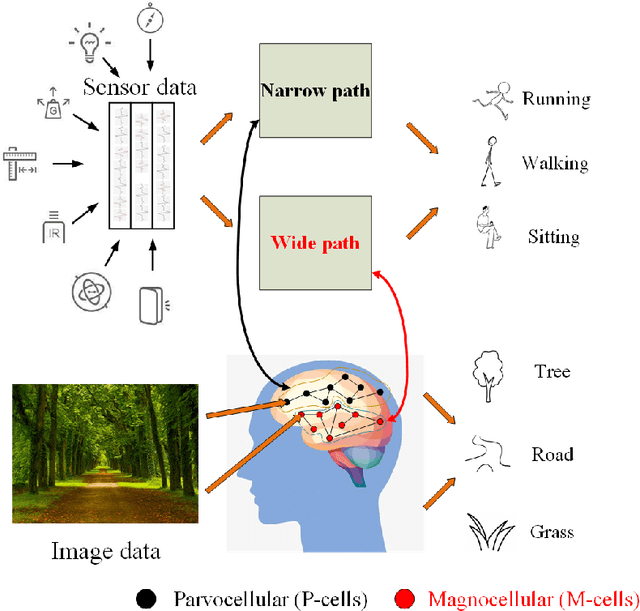

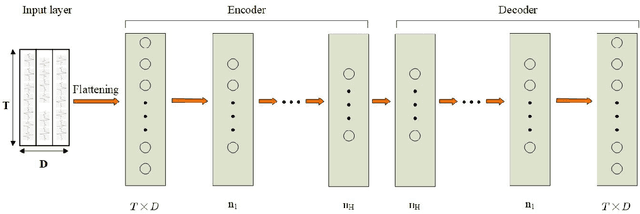
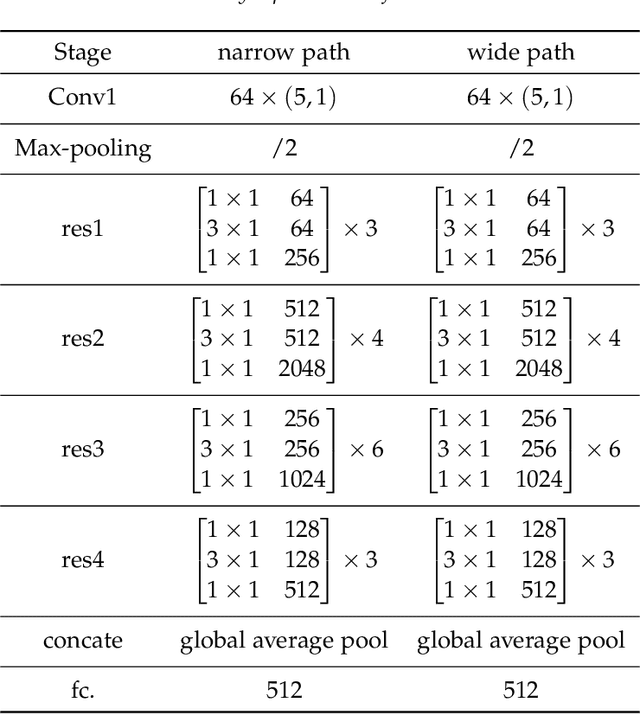
Human Activity Recognition (HAR) using deep neural network has become a hot topic in human-computer interaction. Machine can effectively identify human naturalistic activities by learning from a large collection of sensor data. Activity recognition is not only an interesting research problem, but also has many real-world practical applications. Based on the success of residual networks in achieving a high level of aesthetic representation of the automatic learning, we propose a novel \textbf{D}ual \textbf{R}esidual \textbf{N}etwork, named DRN. DRN is implemented using two identical path frameworks consisting of (1) a short time window, which is used to capture spatial features, and (2) a long time window, which is used to capture fine temporal features. The long time window path can be made very lightweight by reducing its channel capacity, yet still being able to learn useful temporal representations for activity recognition. In this paper, we mainly focus on proposing a new model to improve the accuracy of HAR. In order to demonstrate the effectiveness of DRN model, we carried out extensive experiments and compared with conventional recognition methods (HC, CBH, CBS) and learning-based methods (AE, MLP, CNN, LSTM, Hybrid, ResNet). The benchmark datasets (OPPORTUNITY, UniMiB-SHAR) were adopted by our experiments. Results from our experiments show that our model is effective in recognizing human activities via wearable datasets. We discuss the influence of networks parameters on performance to provide insights about its optimization.
DFTerNet: Towards 2-bit Dynamic Fusion Networks for Accurate Human Activity Recognition
Sep 29, 2018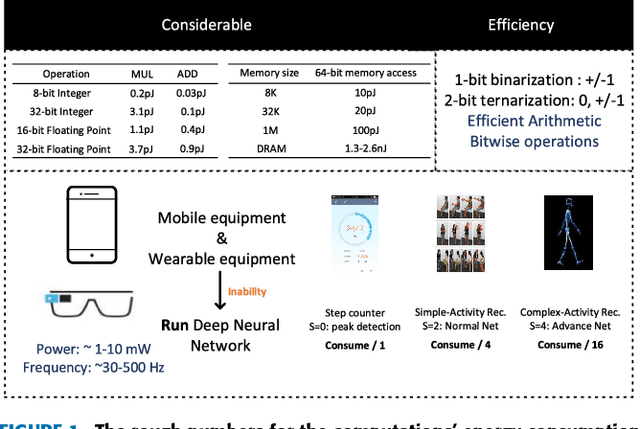
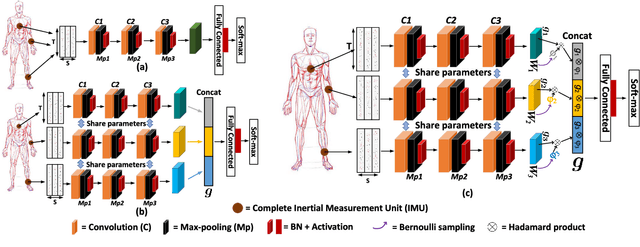
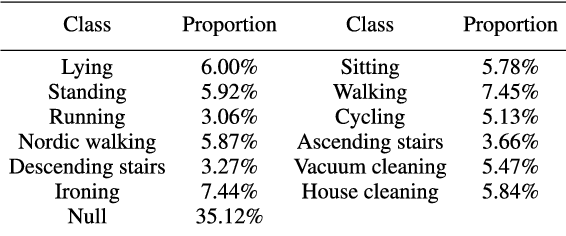
Deep Convolutional Neural Networks (DCNNs) are currently popular in human activity recognition applications. However, in the face of modern artificial intelligence sensor-based games, many research achievements cannot be practically applied on portable devices. DCNNs are typically resource-intensive and too large to be deployed on portable devices, thus this limits the practical application of complex activity detection. In addition, since portable devices do not possess high-performance Graphic Processing Units (GPUs), there is hardly any improvement in Action Game (ACT) experience. Besides, in order to deal with multi-sensor collaboration, all previous human activity recognition models typically treated the representations from different sensor signal sources equally. However, distinct types of activities should adopt different fusion strategies. In this paper, a novel scheme is proposed. This scheme is used to train 2-bit Convolutional Neural Networks with weights and activations constrained to {-0.5,0,0.5}. It takes into account the correlation between different sensor signal sources and the activity types. This model, which we refer to as DFTerNet, aims at producing a more reliable inference and better trade-offs for practical applications. Our basic idea is to exploit quantization of weights and activations directly in pre-trained filter banks and adopt dynamic fusion strategies for different activity types. Experiments demonstrate that by using dynamic fusion strategy can exceed the baseline model performance by up to ~5% on activity recognition like OPPORTUNITY and PAMAP2 datasets. Using the quantization method proposed, we were able to achieve performances closer to that of full-precision counterpart. These results were also verified using the UniMiB-SHAR dataset. In addition, the proposed method can achieve ~9x acceleration on CPUs and ~11x memory saving.