 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuSEAgent: A Multimodal Reasoning Agent with Stateful Experiences
Mar 29, 2026Research agents have recently achieved significant progress in information seeking and synthesis across heterogeneous textual and visual sources. In this paper, we introduce MuSEAgent, a multimodal reasoning agent that enhances decision-making by extending the capabilities of research agents to discover and leverage stateful experiences. Rather than relying on trajectory-level retrieval, we propose a stateful experience learning paradigm that abstracts interaction data into atomic decision experiences through hindsight reasoning. These experiences are organized into a quality-filtered experience bank that supports policy-driven experience retrieval at inference time. Specifically, MuSEAgent enables adaptive experience exploitation through complementary wide- and deep-search strategies, allowing the agent to dynamically retrieve multimodal guidance across diverse compositional semantic viewpoints. Extensive experiments demonstrate that MuSEAgent consistently outperforms strong trajectory-level experience retrieval baselines on both fine-grained visual perception and complex multimodal reasoning tasks. These results validate the effectiveness of stateful experience modeling in improving multimodal agent reasoning.
From Physical Degradation Models to Task-Aware All-in-One Image Restoration
Jan 15, 2026All-in-one image restoration aims to adaptively handle multiple restoration tasks with a single trained model. Although existing methods achieve promising results by introducing prompt information or leveraging large models, the added learning modules increase system complexity and hinder real-time applicability. In this paper, we adopt a physical degradation modeling perspective and predict a task-aware inverse degradation operator for efficient all-in-one image restoration. The framework consists of two stages. In the first stage, the predicted inverse operator produces an initial restored image together with an uncertainty perception map that highlights regions difficult to reconstruct, ensuring restoration reliability. In the second stage, the restoration is further refined under the guidance of this uncertainty map. The same inverse operator prediction network is used in both stages, with task-aware parameters introduced after operator prediction to adapt to different degradation tasks. Moreover, by accelerating the convolution of the inverse operator, the proposed method achieves efficient all-in-one image restoration. The resulting tightly integrated architecture, termed OPIR, is extensively validated through experiments, demonstrating superior all-in-one restoration performance while remaining highly competitive on task-aligned restoration.
ScaleLong: A Multi-Timescale Benchmark for Long Video Understanding
May 29, 2025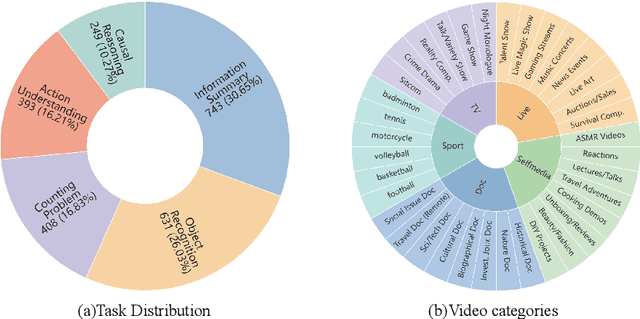



Although long-video understanding demands that models capture hierarchical temporal information -- from clip (seconds) and shot (tens of seconds) to event (minutes) and story (hours) -- existing benchmarks either neglect this multi-scale design or scatter scale-specific questions across different videos, preventing direct comparison of model performance across timescales on the same content. To address this, we introduce ScaleLong, the first benchmark to disentangle these factors by embedding questions targeting four hierarchical timescales -- clip (seconds), shot (tens of seconds), event (minutes), and story (hours) -- all within the same video content. This within-content multi-timescale questioning design enables direct comparison of model performance across timescales on identical videos. ScaleLong features 269 long videos (avg.\ 86\,min) from 5 main categories and 36 sub-categories, with 4--8 carefully designed questions, including at least one question for each timescale. Evaluating 23 MLLMs reveals a U-shaped performance curve, with higher accuracy at the shortest and longest timescales and a dip at intermediate levels. Furthermore, ablation studies show that increased visual token capacity consistently enhances reasoning across all timescales. ScaleLong offers a fine-grained, multi-timescale benchmark for advancing MLLM capabilities in long-video understanding. The code and dataset are available https://github.com/multimodal-art-projection/ScaleLong.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025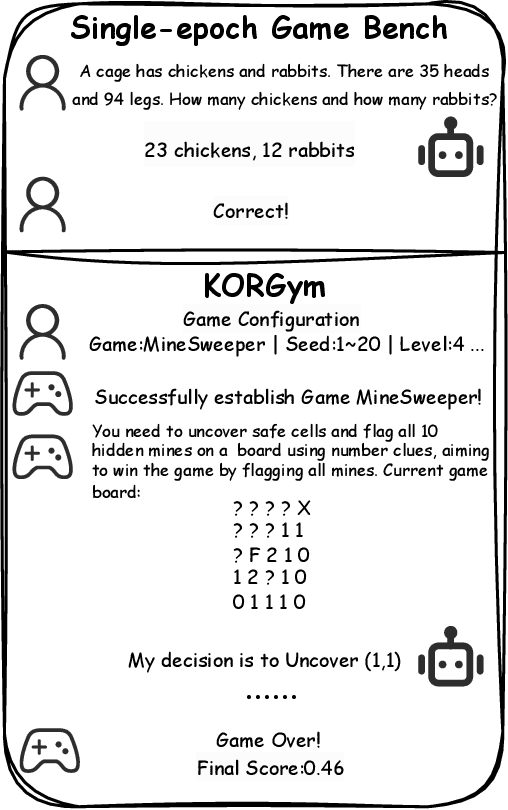
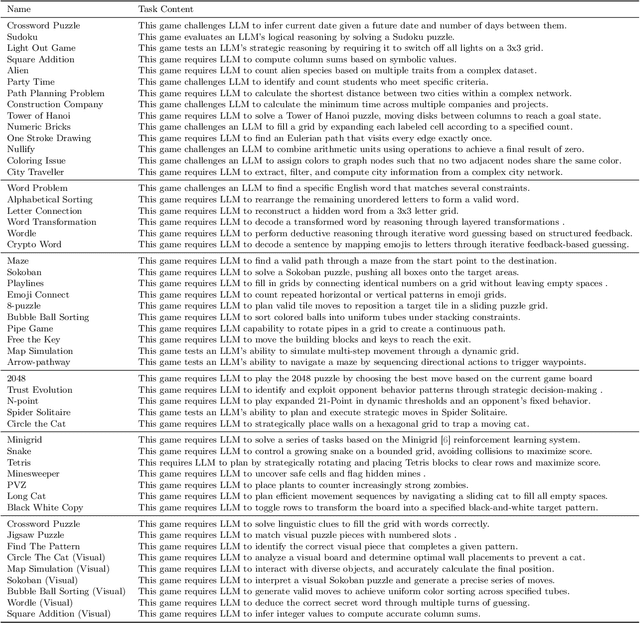
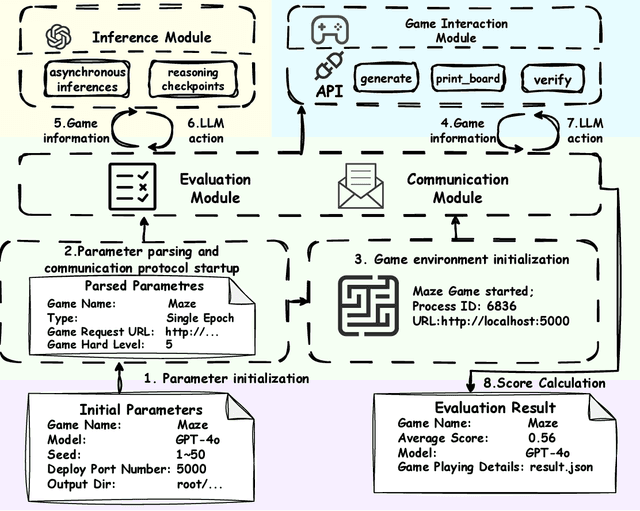

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
Lifting Scheme-Based Implicit Disentanglement of Emotion-Related Facial Dynamics in the Wild
Dec 17, 2024



In-the-wild Dynamic facial expression recognition (DFER) encounters a significant challenge in recognizing emotion-related expressions, which are often temporally and spatially diluted by emotion-irrelevant expressions and global context respectively. Most of the prior DFER methods model tightly coupled spatiotemporal representations which may incorporate weakly relevant features, leading to information redundancy and emotion-irrelevant context bias. Several DFER methods have highlighted the significance of dynamic information, but utilize explicit manners to extract dynamic features with overly strong prior knowledge. In this paper, we propose a novel Implicit Facial Dynamics Disentanglement framework (IFDD). Through expanding wavelet lifting scheme to fully learnable framework, IFDD disentangles emotion-related dynamic information from emotion-irrelevant global context in an implicit manner, i.e., without exploit operations and external guidance. The disentanglement process of IFDD contains two stages, i.e., Inter-frame Static-dynamic Splitting Module (ISSM) for rough disentanglement estimation and Lifting-based Aggregation-Disentanglement Module (LADM) for further refinement. Specifically, ISSM explores inter-frame correlation to generate content-aware splitting indexes on-the-fly. We preliminarily utilize these indexes to split frame features into two groups, one with greater global similarity, and the other with more unique dynamic features. Subsequently, LADM first aggregates these two groups of features to obtain fine-grained global context features by an updater, and then disentangles emotion-related facial dynamic features from the global context by a predictor. Extensive experiments on in-the-wild datasets have demonstrated that IFDD outperforms prior supervised DFER methods with higher recognition accuracy and comparable efficiency.
Frequency-Domain Refinement with Multiscale Diffusion for Super Resolution
May 16, 2024



The performance of single image super-resolution depends heavily on how to generate and complement high-frequency details to low-resolution images. Recently, diffusion-based models exhibit great potential in generating high-quality images for super-resolution tasks. However, existing models encounter difficulties in directly predicting high-frequency information of wide bandwidth by solely utilizing the high-resolution ground truth as the target for all sampling timesteps. To tackle this problem and achieve higher-quality super-resolution, we propose a novel Frequency Domain-guided multiscale Diffusion model (FDDiff), which decomposes the high-frequency information complementing process into finer-grained steps. In particular, a wavelet packet-based frequency complement chain is developed to provide multiscale intermediate targets with increasing bandwidth for reverse diffusion process. Then FDDiff guides reverse diffusion process to progressively complement the missing high-frequency details over timesteps. Moreover, we design a multiscale frequency refinement network to predict the required high-frequency components at multiple scales within one unified network. Comprehensive evaluations on popular benchmarks are conducted, and demonstrate that FDDiff outperforms prior generative methods with higher-fidelity super-resolution results.
Integrated and Lightweight Design of Electro-hydraulic Ankle Prosthesis
Dec 12, 2023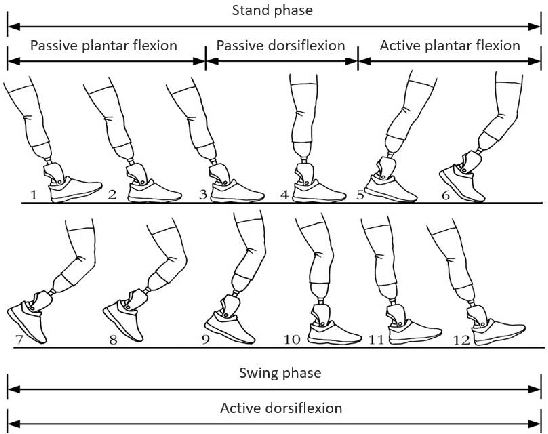
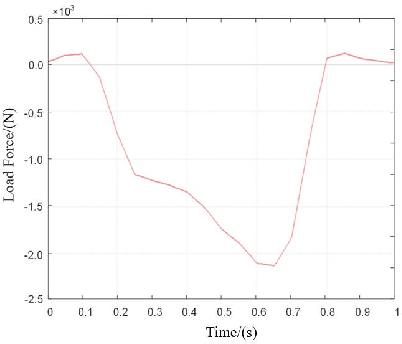
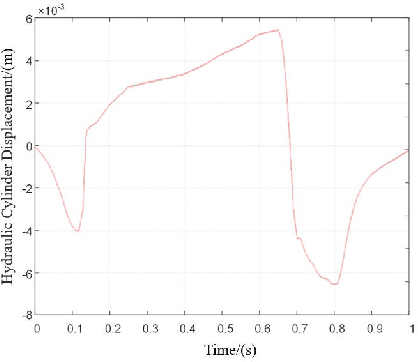
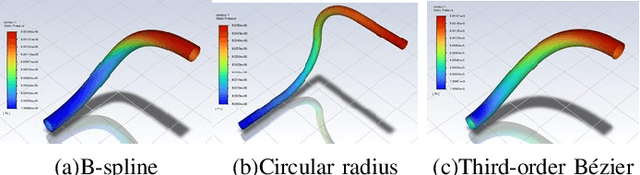
For lower limb amputees, an active ankle joint prosthesis can provide basic mobility functions. This study focuses on an ankle joint prosthesis system based on the principle of electric-hydraulic actuation. By analyzing the characteristics of human gait cycles and the mechanics of ankle joint movement, a lightweight and integrated ankle joint prosthesis is designed, considering the requirements for normal ankle joint kinematics and dynamics. The components of the prosthesis are optimized through simulation and iterative improvements, while ensuring tight integration within minimal space. The design and simulation verification of the integrated lightweight prosthesis components are achieved. This research addresses the contradiction between the high output capability and the constraints on volume and weight in prosthetic devices.
WCCNet: Wavelet-integrated CNN with Crossmodal Rearranging Fusion for Fast Multispectral Pedestrian Detection
Aug 02, 2023



Multispectral pedestrian detection achieves better visibility in challenging conditions and thus has a broad application in various tasks, for which both the accuracy and computational cost are of paramount importance. Most existing approaches treat RGB and infrared modalities equally, typically adopting two symmetrical CNN backbones for multimodal feature extraction, which ignores the substantial differences between modalities and brings great difficulty for the reduction of the computational cost as well as effective crossmodal fusion. In this work, we propose a novel and efficient framework named WCCNet that is able to differentially extract rich features of different spectra with lower computational complexity and semantically rearranges these features for effective crossmodal fusion. Specifically, the discrete wavelet transform (DWT) allowing fast inference and training speed is embedded to construct a dual-stream backbone for efficient feature extraction. The DWT layers of WCCNet extract frequency components for infrared modality, while the CNN layers extract spatial-domain features for RGB modality. This methodology not only significantly reduces the computational complexity, but also improves the extraction of infrared features to facilitate the subsequent crossmodal fusion. Based on the well extracted features, we elaborately design the crossmodal rearranging fusion module (CMRF), which can mitigate spatial misalignment and merge semantically complementary features of spatially-related local regions to amplify the crossmodal complementary information. We conduct comprehensive evaluations on KAIST and FLIR benchmarks, in which WCCNet outperforms state-of-the-art methods with considerable computational efficiency and competitive accuracy. We also perform the ablation study and analyze thoroughly the impact of different components on the performance of WCCNet.