 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleLong: A Multi-Timescale Benchmark for Long Video Understanding
May 29, 2025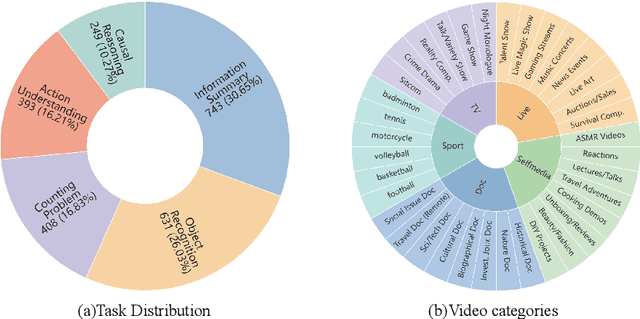



Although long-video understanding demands that models capture hierarchical temporal information -- from clip (seconds) and shot (tens of seconds) to event (minutes) and story (hours) -- existing benchmarks either neglect this multi-scale design or scatter scale-specific questions across different videos, preventing direct comparison of model performance across timescales on the same content. To address this, we introduce ScaleLong, the first benchmark to disentangle these factors by embedding questions targeting four hierarchical timescales -- clip (seconds), shot (tens of seconds), event (minutes), and story (hours) -- all within the same video content. This within-content multi-timescale questioning design enables direct comparison of model performance across timescales on identical videos. ScaleLong features 269 long videos (avg.\ 86\,min) from 5 main categories and 36 sub-categories, with 4--8 carefully designed questions, including at least one question for each timescale. Evaluating 23 MLLMs reveals a U-shaped performance curve, with higher accuracy at the shortest and longest timescales and a dip at intermediate levels. Furthermore, ablation studies show that increased visual token capacity consistently enhances reasoning across all timescales. ScaleLong offers a fine-grained, multi-timescale benchmark for advancing MLLM capabilities in long-video understanding. The code and dataset are available https://github.com/multimodal-art-projection/ScaleLong.
IV-Bench: A Benchmark for Image-Grounded Video Perception and Reasoning in Multimodal LLMs
Apr 21, 2025Existing evaluation frameworks for Multimodal Large Language Models (MLLMs) primarily focus on image reasoning or general video understanding tasks, largely overlooking the significant role of image context in video comprehension. To bridge this gap, we propose IV-Bench, the first comprehensive benchmark for evaluating Image-Grounded Video Perception and Reasoning. IV-Bench consists of 967 videos paired with 2,585 meticulously annotated image-text queries across 13 tasks (7 perception and 6 reasoning tasks) and 5 representative categories. Extensive evaluations of state-of-the-art open-source (e.g., InternVL2.5, Qwen2.5-VL) and closed-source (e.g., GPT-4o, Gemini2-Flash and Gemini2-Pro) MLLMs demonstrate that current models substantially underperform in image-grounded video Perception and Reasoning, merely achieving at most 28.9% accuracy. Further analysis reveals key factors influencing model performance on IV-Bench, including inference pattern, frame number, and resolution. Additionally, through a simple data synthesis approach, we demonstratethe challenges of IV- Bench extend beyond merely aligning the data format in the training proecss. These findings collectively provide valuable insights for future research. Our codes and data are released in https://github.com/multimodal-art-projection/IV-Bench.
AutoKaggle: A Multi-Agent Framework for Autonomous Data Science Competitions
Oct 29, 2024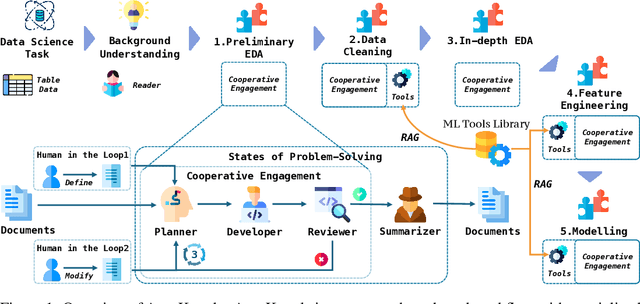
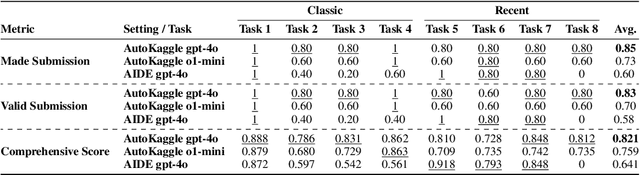
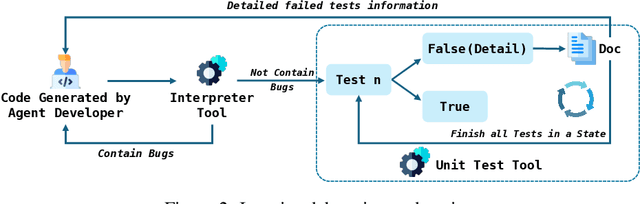
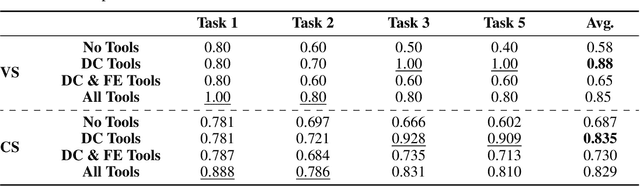
Data science tasks involving tabular data present complex challenges that require sophisticated problem-solving approaches. We propose AutoKaggle, a powerful and user-centric framework that assists data scientists in completing daily data pipelines through a collaborative multi-agent system. AutoKaggle implements an iterative development process that combines code execution, debugging, and comprehensive unit testing to ensure code correctness and logic consistency. The framework offers highly customizable workflows, allowing users to intervene at each phase, thus integrating automated intelligence with human expertise. Our universal data science toolkit, comprising validated functions for data cleaning, feature engineering, and modeling, forms the foundation of this solution, enhancing productivity by streamlining common tasks. We selected 8 Kaggle competitions to simulate data processing workflows in real-world application scenarios. Evaluation results demonstrate that AutoKaggle achieves a validation submission rate of 0.85 and a comprehensive score of 0.82 in typical data science pipelines, fully proving its effectiveness and practicality in handling complex data science tasks.
Balancing Effect of Training Dataset Distribution of Multiple Styles for Multi-Style Text Transfer
May 24, 2023Text style transfer is an exciting task within the field of natural language generation that is often plagued by the need for high-quality paired datasets. Furthermore, training a model for multi-attribute text style transfer requires datasets with sufficient support across all combinations of the considered stylistic attributes, adding to the challenges of training a style transfer model. This paper explores the impact of training data input diversity on the quality of the generated text from the multi-style transfer model. We construct a pseudo-parallel dataset by devising heuristics to adjust the style distribution in the training samples. We balance our training dataset using marginal and joint distributions to train our style transfer models. We observe that a balanced dataset produces more effective control effects over multiple styles than an imbalanced or skewed one. Through quantitative analysis, we explore the impact of multiple style distributions in training data on style-transferred output. These findings will better inform the design of style-transfer datasets.