 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAmmoTH-VL: Eliciting Multimodal Reasoning with Instruction Tuning at Scale
Dec 06, 2024



Open-source multimodal large language models (MLLMs) have shown significant potential in a broad range of multimodal tasks. However, their reasoning capabilities remain constrained by existing instruction-tuning datasets, which were predominately repurposed from academic datasets such as VQA, AI2D, and ChartQA. These datasets target simplistic tasks, and only provide phrase-level answers without any intermediate rationales. To address these challenges, we introduce a scalable and cost-effective method to construct a large-scale multimodal instruction-tuning dataset with rich intermediate rationales designed to elicit CoT reasoning. Using only open models, we create a dataset containing 12M instruction-response pairs to cover diverse, reasoning-intensive tasks with detailed and faithful rationales. Experiments demonstrate that training MLLMs on this dataset significantly improves reasoning capabilities, achieving state-of-the-art performance on benchmarks such as MathVerse (+8.1%), MMMU-Pro (+7%), and MuirBench (+13.3%). Additionally, the model demonstrates notable improvements of up to 4% on non-reasoning-based benchmarks. Ablation studies further highlight the importance of key components, such as rewriting and self-filtering, in the dataset construction process.
AutoKaggle: A Multi-Agent Framework for Autonomous Data Science Competitions
Oct 29, 2024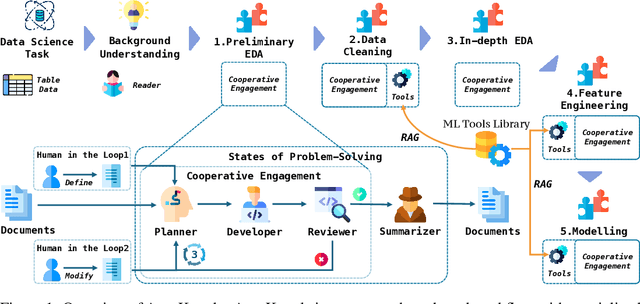
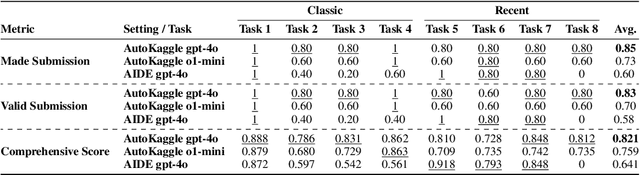
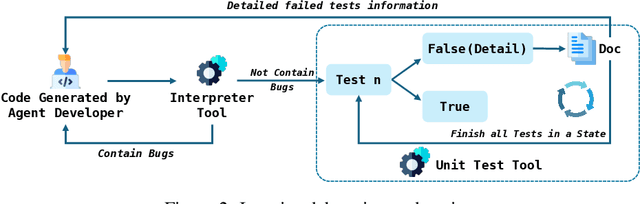
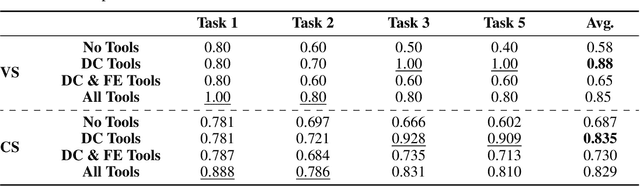
Data science tasks involving tabular data present complex challenges that require sophisticated problem-solving approaches. We propose AutoKaggle, a powerful and user-centric framework that assists data scientists in completing daily data pipelines through a collaborative multi-agent system. AutoKaggle implements an iterative development process that combines code execution, debugging, and comprehensive unit testing to ensure code correctness and logic consistency. The framework offers highly customizable workflows, allowing users to intervene at each phase, thus integrating automated intelligence with human expertise. Our universal data science toolkit, comprising validated functions for data cleaning, feature engineering, and modeling, forms the foundation of this solution, enhancing productivity by streamlining common tasks. We selected 8 Kaggle competitions to simulate data processing workflows in real-world application scenarios. Evaluation results demonstrate that AutoKaggle achieves a validation submission rate of 0.85 and a comprehensive score of 0.82 in typical data science pipelines, fully proving its effectiveness and practicality in handling complex data science tasks.
A Comparative Study on Reasoning Patterns of OpenAI's o1 Model
Oct 17, 2024



Enabling Large Language Models (LLMs) to handle a wider range of complex tasks (e.g., coding, math) has drawn great attention from many researchers. As LLMs continue to evolve, merely increasing the number of model parameters yields diminishing performance improvements and heavy computational costs. Recently, OpenAI's o1 model has shown that inference strategies (i.e., Test-time Compute methods) can also significantly enhance the reasoning capabilities of LLMs. However, the mechanisms behind these methods are still unexplored. In our work, to investigate the reasoning patterns of o1, we compare o1 with existing Test-time Compute methods (BoN, Step-wise BoN, Agent Workflow, and Self-Refine) by using OpenAI's GPT-4o as a backbone on general reasoning benchmarks in three domains (i.e., math, coding, commonsense reasoning). Specifically, first, our experiments show that the o1 model has achieved the best performance on most datasets. Second, as for the methods of searching diverse responses (e.g., BoN), we find the reward models' capability and the search space both limit the upper boundary of these methods. Third, as for the methods that break the problem into many sub-problems, the Agent Workflow has achieved better performance than Step-wise BoN due to the domain-specific system prompt for planning better reasoning processes. Fourth, it is worth mentioning that we have summarized six reasoning patterns of o1, and provided a detailed analysis on several reasoning benchmarks.
LongIns: A Challenging Long-context Instruction-based Exam for LLMs
Jun 26, 2024



The long-context capabilities of large language models (LLMs) have been a hot topic in recent years. To evaluate the performance of LLMs in different scenarios, various assessment benchmarks have emerged. However, as most of these benchmarks focus on identifying key information to answer questions, which mainly requires the retrieval ability of LLMs, these benchmarks can partially represent the reasoning performance of LLMs from large amounts of information. Meanwhile, although LLMs often claim to have context windows of 32k, 128k, 200k, or even longer, these benchmarks fail to reveal the actual supported length of these LLMs. To address these issues, we propose the LongIns benchmark dataset, a challenging long-context instruction-based exam for LLMs, which is built based on the existing instruction datasets. Specifically, in our LongIns, we introduce three evaluation settings: Global Instruction & Single Task (GIST), Local Instruction & Single Task (LIST), and Local Instruction & Multiple Tasks (LIMT). Based on LongIns, we perform comprehensive evaluations on existing LLMs and have the following important findings: (1). The top-performing GPT-4 with 128k context length performs poorly on the evaluation context window of 16k in our LongIns. (2). For the multi-hop reasoning ability of many existing LLMs, significant efforts are still needed under short context windows (less than 4k).
MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series
May 29, 2024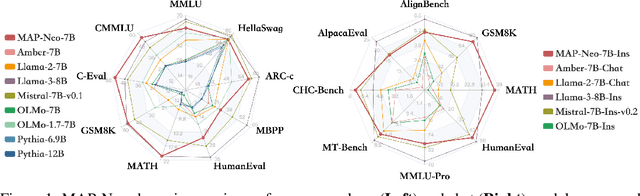

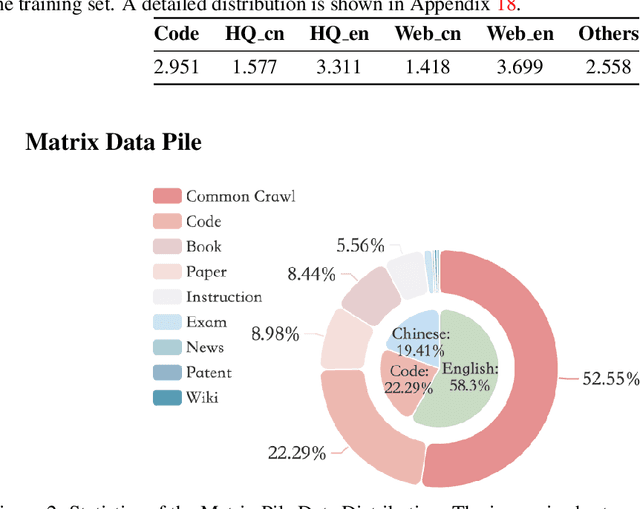
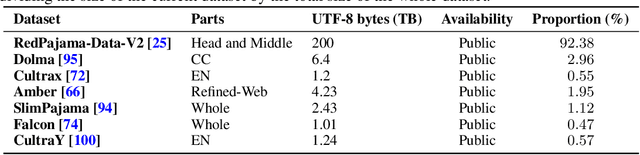
Large Language Models (LLMs) have made great strides in recent years to achieve unprecedented performance across different tasks. However, due to commercial interest, the most competitive models like GPT, Gemini, and Claude have been gated behind proprietary interfaces without disclosing the training details. Recently, many institutions have open-sourced several strong LLMs like LLaMA-3, comparable to existing closed-source LLMs. However, only the model's weights are provided with most details (e.g., intermediate checkpoints, pre-training corpus, and training code, etc.) being undisclosed. To improve the transparency of LLMs, the research community has formed to open-source truly open LLMs (e.g., Pythia, Amber, OLMo), where more details (e.g., pre-training corpus and training code) are being provided. These models have greatly advanced the scientific study of these large models including their strengths, weaknesses, biases and risks. However, we observe that the existing truly open LLMs on reasoning, knowledge, and coding tasks are still inferior to existing state-of-the-art LLMs with similar model sizes. To this end, we open-source MAP-Neo, a highly capable and transparent bilingual language model with 7B parameters trained from scratch on 4.5T high-quality tokens. Our MAP-Neo is the first fully open-sourced bilingual LLM with comparable performance compared to existing state-of-the-art LLMs. Moreover, we open-source all details to reproduce our MAP-Neo, where the cleaned pre-training corpus, data cleaning pipeline, checkpoints, and well-optimized training/evaluation framework are provided. Finally, we hope our MAP-Neo will enhance and strengthen the open research community and inspire more innovations and creativities to facilitate the further improvements of LLMs.
MAmmoTH2: Scaling Instructions from the Web
May 06, 2024



Instruction tuning improves the reasoning abilities of large language models (LLMs), with data quality and scalability being the crucial factors. Most instruction tuning data come from human crowd-sourcing or GPT-4 distillation. We propose a paradigm to efficiently harvest 10 million naturally existing instruction data from the pre-training web corpus to enhance LLM reasoning. Our approach involves (1) recalling relevant documents, (2) extracting instruction-response pairs, and (3) refining the extracted pairs using open-source LLMs. Fine-tuning base LLMs on this dataset, we build MAmmoTH2 models, which significantly boost performance on reasoning benchmarks. Notably, MAmmoTH2-7B's (Mistral) performance increases from 11% to 34% on MATH and from 36% to 67% on GSM8K without training on any in-domain data. Further training MAmmoTH2 on public instruction tuning datasets yields MAmmoTH2-Plus, achieving state-of-the-art performance on several reasoning and chatbot benchmarks. Our work demonstrates how to harvest large-scale, high-quality instruction data without costly human annotation or GPT-4 distillation, providing a new paradigm for building better instruction tuning data.