 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Machine Learning for Lunar Mineralogy-I: Hyperspectral Imaging of Volcanic Samples
Mar 28, 2025This study examines the mineral composition of volcanic samples similar to lunar materials, focusing on olivine and pyroxene. Using hyperspectral imaging from 400 to 1000 nm, we created data cubes to analyze the reflectance characteristics of samples from samples from Vulcano, a volcanically active island in the Aeolian Archipelago, north of Sicily, Italy, categorizing them into nine regions of interest and analyzing spectral data for each. We applied various unsupervised clustering algorithms, including K-Means, Hierarchical Clustering, GMM, and Spectral Clustering, to classify the spectral profiles. Principal Component Analysis revealed distinct spectral signatures associated with specific minerals, facilitating precise identification. Clustering performance varied by region, with K-Means achieving the highest silhouette-score of 0.47, whereas GMM performed poorly with a score of only 0.25. Non-negative Matrix Factorization aided in identifying similarities among clusters across different methods and reference spectra for olivine and pyroxene. Hierarchical clustering emerged as the most reliable technique, achieving a 94\% similarity with the olivine spectrum in one sample, whereas GMM exhibited notable variability. Overall, the analysis indicated that both Hierarchical and K-Means methods yielded lower errors in total measurements, with K-Means demonstrating superior performance in estimated dispersion and clustering. Additionally, GMM showed a higher root mean square error compared to the other models. The RMSE analysis confirmed K-Means as the most consistent algorithm across all samples, suggesting a predominance of olivine in the Vulcano region relative to pyroxene. This predominance is likely linked to historical formation conditions similar to volcanic processes on the Moon, where olivine-rich compositions are common in ancient lava flows and impact melt rocks.
MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series
May 29, 2024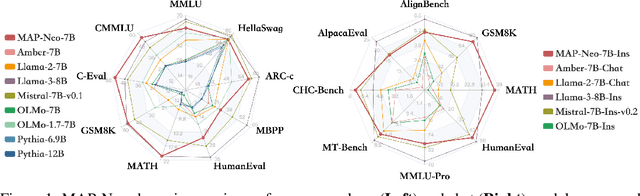

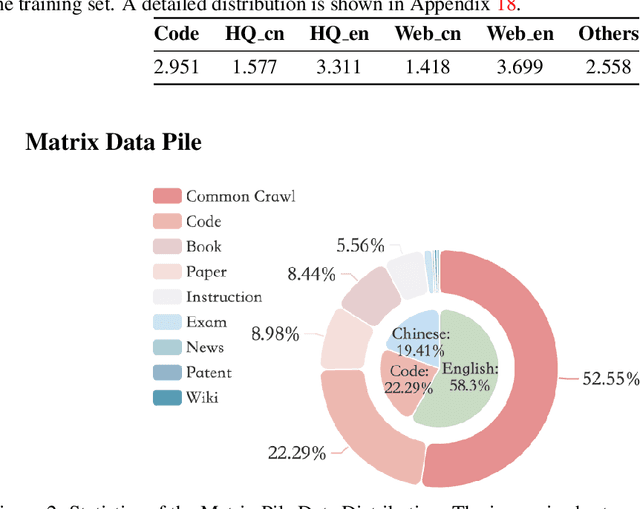
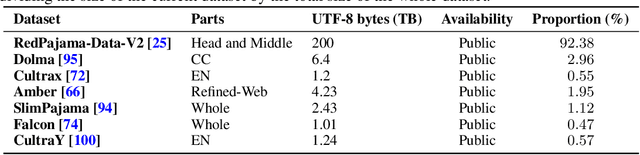
Large Language Models (LLMs) have made great strides in recent years to achieve unprecedented performance across different tasks. However, due to commercial interest, the most competitive models like GPT, Gemini, and Claude have been gated behind proprietary interfaces without disclosing the training details. Recently, many institutions have open-sourced several strong LLMs like LLaMA-3, comparable to existing closed-source LLMs. However, only the model's weights are provided with most details (e.g., intermediate checkpoints, pre-training corpus, and training code, etc.) being undisclosed. To improve the transparency of LLMs, the research community has formed to open-source truly open LLMs (e.g., Pythia, Amber, OLMo), where more details (e.g., pre-training corpus and training code) are being provided. These models have greatly advanced the scientific study of these large models including their strengths, weaknesses, biases and risks. However, we observe that the existing truly open LLMs on reasoning, knowledge, and coding tasks are still inferior to existing state-of-the-art LLMs with similar model sizes. To this end, we open-source MAP-Neo, a highly capable and transparent bilingual language model with 7B parameters trained from scratch on 4.5T high-quality tokens. Our MAP-Neo is the first fully open-sourced bilingual LLM with comparable performance compared to existing state-of-the-art LLMs. Moreover, we open-source all details to reproduce our MAP-Neo, where the cleaned pre-training corpus, data cleaning pipeline, checkpoints, and well-optimized training/evaluation framework are provided. Finally, we hope our MAP-Neo will enhance and strengthen the open research community and inspire more innovations and creativities to facilitate the further improvements of LLMs.