 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Machine Learning for Lunar Mineralogy-I: Hyperspectral Imaging of Volcanic Samples
Mar 28, 2025This study examines the mineral composition of volcanic samples similar to lunar materials, focusing on olivine and pyroxene. Using hyperspectral imaging from 400 to 1000 nm, we created data cubes to analyze the reflectance characteristics of samples from samples from Vulcano, a volcanically active island in the Aeolian Archipelago, north of Sicily, Italy, categorizing them into nine regions of interest and analyzing spectral data for each. We applied various unsupervised clustering algorithms, including K-Means, Hierarchical Clustering, GMM, and Spectral Clustering, to classify the spectral profiles. Principal Component Analysis revealed distinct spectral signatures associated with specific minerals, facilitating precise identification. Clustering performance varied by region, with K-Means achieving the highest silhouette-score of 0.47, whereas GMM performed poorly with a score of only 0.25. Non-negative Matrix Factorization aided in identifying similarities among clusters across different methods and reference spectra for olivine and pyroxene. Hierarchical clustering emerged as the most reliable technique, achieving a 94\% similarity with the olivine spectrum in one sample, whereas GMM exhibited notable variability. Overall, the analysis indicated that both Hierarchical and K-Means methods yielded lower errors in total measurements, with K-Means demonstrating superior performance in estimated dispersion and clustering. Additionally, GMM showed a higher root mean square error compared to the other models. The RMSE analysis confirmed K-Means as the most consistent algorithm across all samples, suggesting a predominance of olivine in the Vulcano region relative to pyroxene. This predominance is likely linked to historical formation conditions similar to volcanic processes on the Moon, where olivine-rich compositions are common in ancient lava flows and impact melt rocks.
Advancing Machine Learning for Stellar Activity and Exoplanet Period Rotation
Sep 09, 2024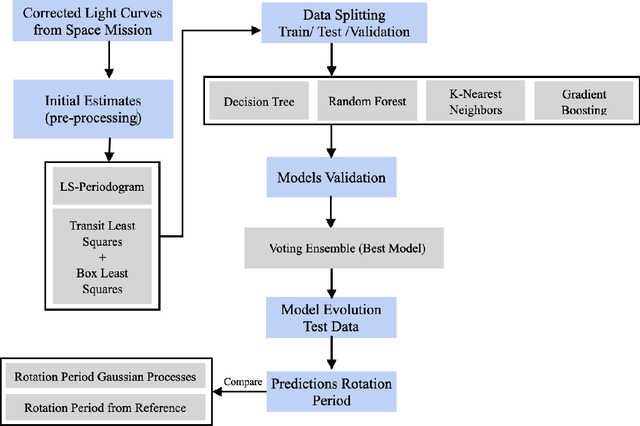
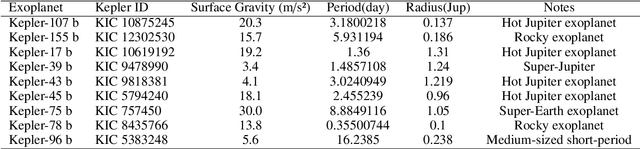
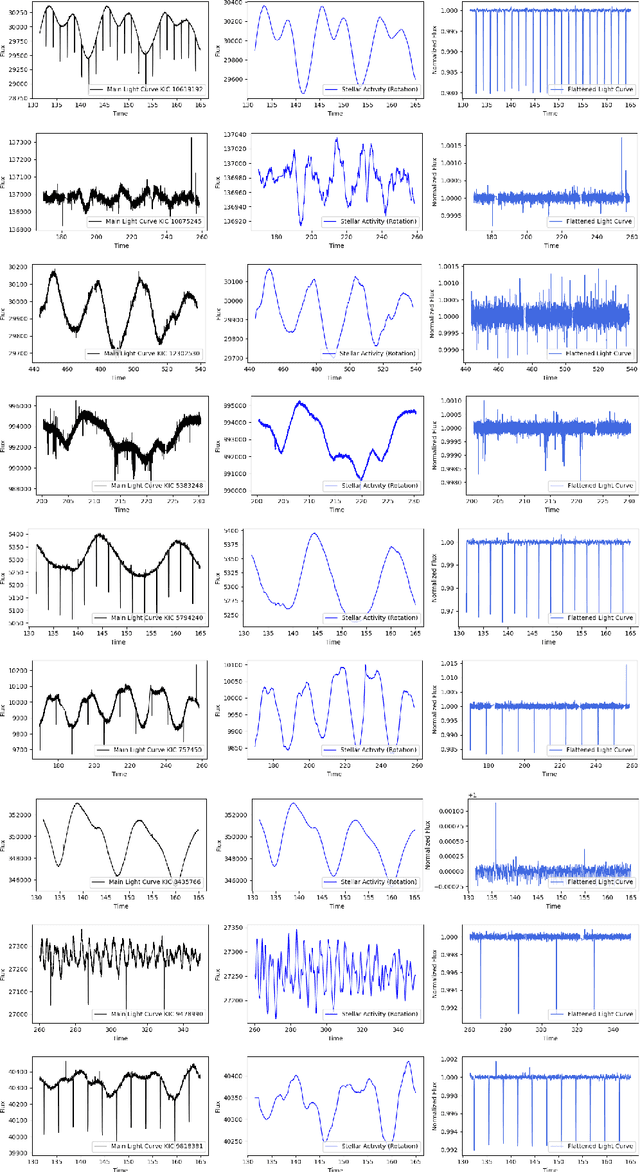
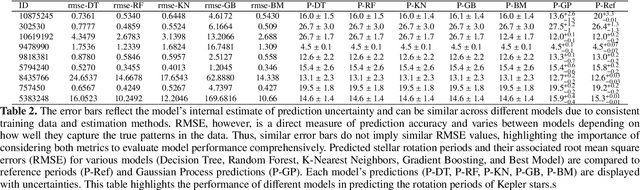
This study applied machine learning models to estimate stellar rotation periods from corrected light curve data obtained by the NASA Kepler mission. Traditional methods often struggle to estimate rotation periods accurately due to noise and variability in the light curve data. The workflow involved using initial period estimates from the LS-Periodogram and Transit Least Squares techniques, followed by splitting the data into training, validation, and testing sets. We employed several machine learning algorithms, including Decision Tree, Random Forest, K-Nearest Neighbors, and Gradient Boosting, and also utilized a Voting Ensemble approach to improve prediction accuracy and robustness. The analysis included data from multiple Kepler IDs, providing detailed metrics on orbital periods and planet radii. Performance evaluation showed that the Voting Ensemble model yielded the most accurate results, with an RMSE approximately 50\% lower than the Decision Tree model and 17\% better than the K-Nearest Neighbors model. The Random Forest model performed comparably to the Voting Ensemble, indicating high accuracy. In contrast, the Gradient Boosting model exhibited a worse RMSE compared to the other approaches. Comparisons of the predicted rotation periods to the photometric reference periods showed close alignment, suggesting the machine learning models achieved high prediction accuracy. The results indicate that machine learning, particularly ensemble methods, can effectively solve the problem of accurately estimating stellar rotation periods, with significant implications for advancing the study of exoplanets and stellar astrophysics.