 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleLong: A Multi-Timescale Benchmark for Long Video Understanding
May 29, 2025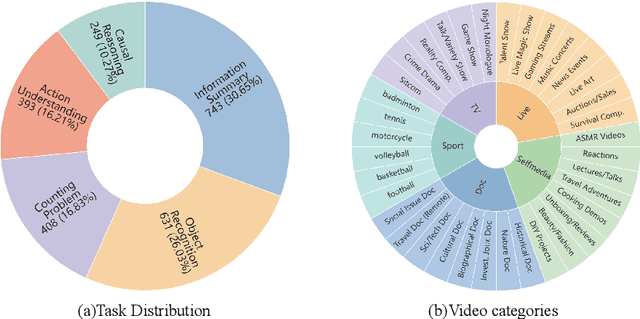



Although long-video understanding demands that models capture hierarchical temporal information -- from clip (seconds) and shot (tens of seconds) to event (minutes) and story (hours) -- existing benchmarks either neglect this multi-scale design or scatter scale-specific questions across different videos, preventing direct comparison of model performance across timescales on the same content. To address this, we introduce ScaleLong, the first benchmark to disentangle these factors by embedding questions targeting four hierarchical timescales -- clip (seconds), shot (tens of seconds), event (minutes), and story (hours) -- all within the same video content. This within-content multi-timescale questioning design enables direct comparison of model performance across timescales on identical videos. ScaleLong features 269 long videos (avg.\ 86\,min) from 5 main categories and 36 sub-categories, with 4--8 carefully designed questions, including at least one question for each timescale. Evaluating 23 MLLMs reveals a U-shaped performance curve, with higher accuracy at the shortest and longest timescales and a dip at intermediate levels. Furthermore, ablation studies show that increased visual token capacity consistently enhances reasoning across all timescales. ScaleLong offers a fine-grained, multi-timescale benchmark for advancing MLLM capabilities in long-video understanding. The code and dataset are available https://github.com/multimodal-art-projection/ScaleLong.
IV-Bench: A Benchmark for Image-Grounded Video Perception and Reasoning in Multimodal LLMs
Apr 21, 2025Existing evaluation frameworks for Multimodal Large Language Models (MLLMs) primarily focus on image reasoning or general video understanding tasks, largely overlooking the significant role of image context in video comprehension. To bridge this gap, we propose IV-Bench, the first comprehensive benchmark for evaluating Image-Grounded Video Perception and Reasoning. IV-Bench consists of 967 videos paired with 2,585 meticulously annotated image-text queries across 13 tasks (7 perception and 6 reasoning tasks) and 5 representative categories. Extensive evaluations of state-of-the-art open-source (e.g., InternVL2.5, Qwen2.5-VL) and closed-source (e.g., GPT-4o, Gemini2-Flash and Gemini2-Pro) MLLMs demonstrate that current models substantially underperform in image-grounded video Perception and Reasoning, merely achieving at most 28.9% accuracy. Further analysis reveals key factors influencing model performance on IV-Bench, including inference pattern, frame number, and resolution. Additionally, through a simple data synthesis approach, we demonstratethe challenges of IV- Bench extend beyond merely aligning the data format in the training proecss. These findings collectively provide valuable insights for future research. Our codes and data are released in https://github.com/multimodal-art-projection/IV-Bench.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
I-SHEEP: Self-Alignment of LLM from Scratch through an Iterative Self-Enhancement Paradigm
Aug 15, 2024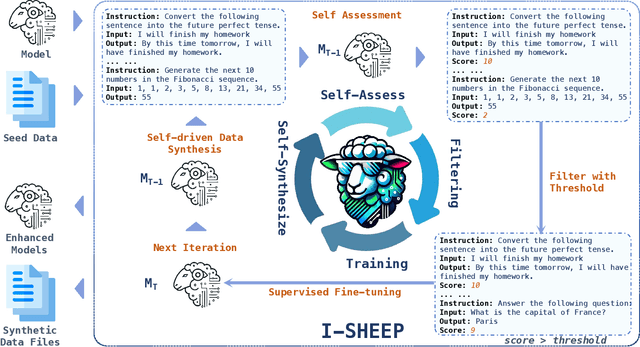


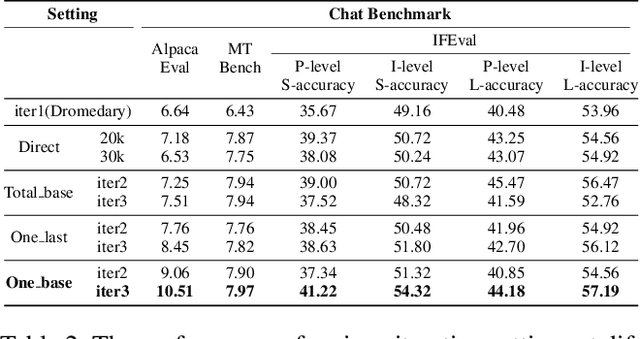
Large Language Models (LLMs) have achieved significant advancements, however, the common learning paradigm treats LLMs as passive information repositories, neglecting their potential for active learning and alignment. Some approaches train LLMs using their own generated synthetic data, exploring the possibility of active alignment. However, there is still a huge gap between these one-time alignment methods and the continuous automatic alignment of humans. In this paper, we introduce \textbf{I-SHEEP}, an \textbf{I}terative \textbf{S}elf-En\textbf{H}anc\textbf{E}m\textbf{E}nt \textbf{P}aradigm.This human-like paradigm enables LLMs to \textbf{continuously self-align from scratch with nothing}. Compared to the one-time alignment method Dromedary \cite{sun2023principledriven}, which refers to the first iteration in this paper, I-SHEEP can significantly enhance capacities on both Qwen and Llama models. I-SHEEP achieves a maximum relative improvement of 78.2\% in the Alpaca Eval, 24.0\% in the MT Bench, and an absolute increase of 8.88\% in the IFEval accuracy over subsequent iterations in Qwen-1.5 72B model. Additionally, I-SHEEP surpasses the base model in various standard benchmark generation tasks, achieving an average improvement of 24.77\% in code generation tasks, 12.04\% in TrivialQA, and 20.29\% in SQuAD. We also provide new insights based on the experiment results. Our codes, datasets, and models are available at \textbf{https://anonymous.4open.science/r/I-SHEEP}.
MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series
May 29, 2024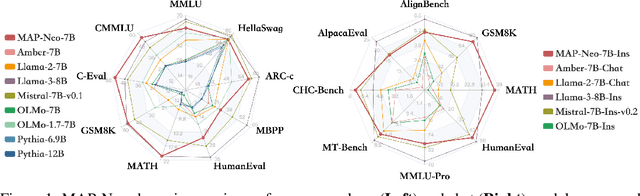

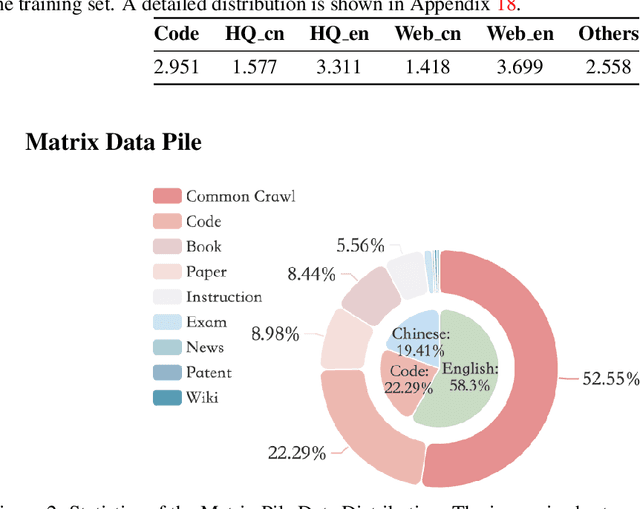
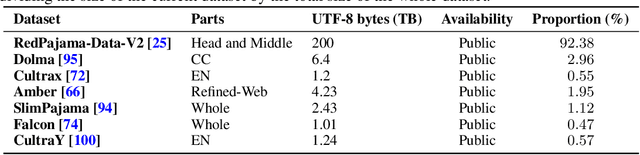
Large Language Models (LLMs) have made great strides in recent years to achieve unprecedented performance across different tasks. However, due to commercial interest, the most competitive models like GPT, Gemini, and Claude have been gated behind proprietary interfaces without disclosing the training details. Recently, many institutions have open-sourced several strong LLMs like LLaMA-3, comparable to existing closed-source LLMs. However, only the model's weights are provided with most details (e.g., intermediate checkpoints, pre-training corpus, and training code, etc.) being undisclosed. To improve the transparency of LLMs, the research community has formed to open-source truly open LLMs (e.g., Pythia, Amber, OLMo), where more details (e.g., pre-training corpus and training code) are being provided. These models have greatly advanced the scientific study of these large models including their strengths, weaknesses, biases and risks. However, we observe that the existing truly open LLMs on reasoning, knowledge, and coding tasks are still inferior to existing state-of-the-art LLMs with similar model sizes. To this end, we open-source MAP-Neo, a highly capable and transparent bilingual language model with 7B parameters trained from scratch on 4.5T high-quality tokens. Our MAP-Neo is the first fully open-sourced bilingual LLM with comparable performance compared to existing state-of-the-art LLMs. Moreover, we open-source all details to reproduce our MAP-Neo, where the cleaned pre-training corpus, data cleaning pipeline, checkpoints, and well-optimized training/evaluation framework are provided. Finally, we hope our MAP-Neo will enhance and strengthen the open research community and inspire more innovations and creativities to facilitate the further improvements of LLMs.
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Nov 27, 2023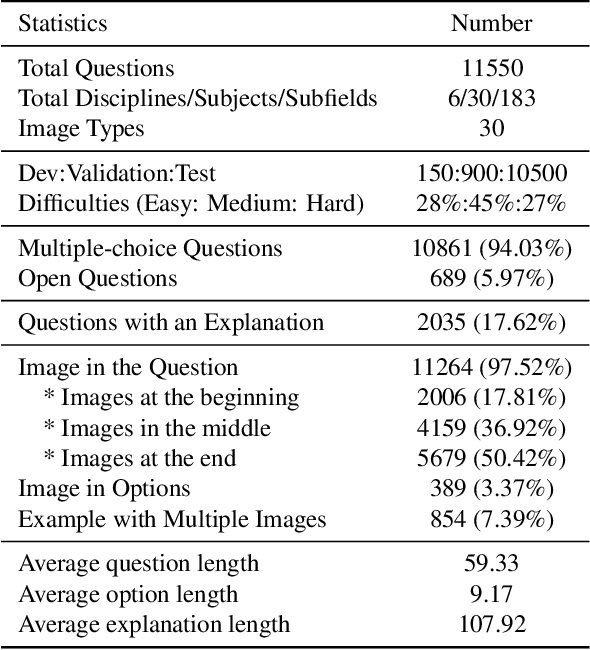

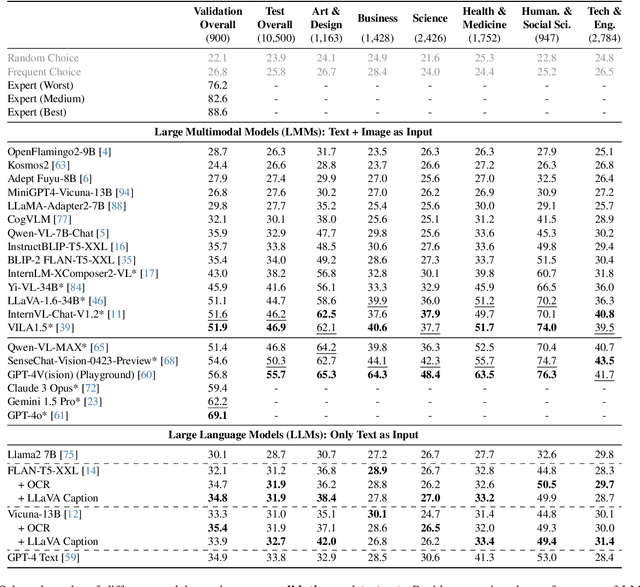
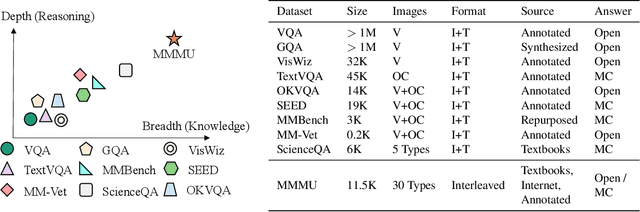
We introduce MMMU: a new benchmark designed to evaluate multimodal models on massive multi-discipline tasks demanding college-level subject knowledge and deliberate reasoning. MMMU includes 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering. These questions span 30 subjects and 183 subfields, comprising 30 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. Unlike existing benchmarks, MMMU focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. Our evaluation of 14 open-source LMMs and the proprietary GPT-4V(ision) highlights the substantial challenges posed by MMMU. Even the advanced GPT-4V only achieves a 56% accuracy, indicating significant room for improvement. We believe MMMU will stimulate the community to build next-generation multimodal foundation models towards expert artificial general intelligence.
Interactive Natural Language Processing
May 22, 2023



Interactive Natural Language Processing (iNLP) has emerged as a novel paradigm within the field of NLP, aimed at addressing limitations in existing frameworks while aligning with the ultimate goals of artificial intelligence. This paradigm considers language models as agents capable of observing, acting, and receiving feedback iteratively from external entities. Specifically, language models in this context can: (1) interact with humans for better understanding and addressing user needs, personalizing responses, aligning with human values, and improving the overall user experience; (2) interact with knowledge bases for enriching language representations with factual knowledge, enhancing the contextual relevance of responses, and dynamically leveraging external information to generate more accurate and informed responses; (3) interact with models and tools for effectively decomposing and addressing complex tasks, leveraging specialized expertise for specific subtasks, and fostering the simulation of social behaviors; and (4) interact with environments for learning grounded representations of language, and effectively tackling embodied tasks such as reasoning, planning, and decision-making in response to environmental observations. This paper offers a comprehensive survey of iNLP, starting by proposing a unified definition and framework of the concept. We then provide a systematic classification of iNLP, dissecting its various components, including interactive objects, interaction interfaces, and interaction methods. We proceed to delve into the evaluation methodologies used in the field, explore its diverse applications, scrutinize its ethical and safety issues, and discuss prospective research directions. This survey serves as an entry point for researchers who are interested in this rapidly evolving area and offers a broad view of the current landscape and future trajectory of iNLP.