 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinicalTrialsHub: Bridging Registries and Literature for Comprehensive Clinical Trial Access
Dec 09, 2025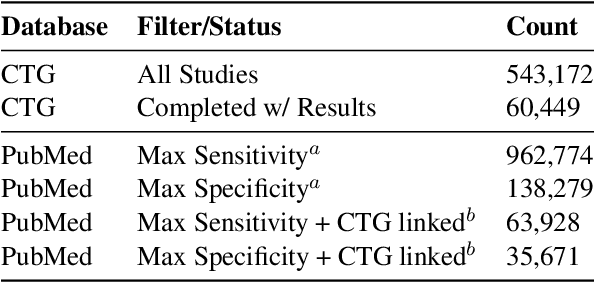
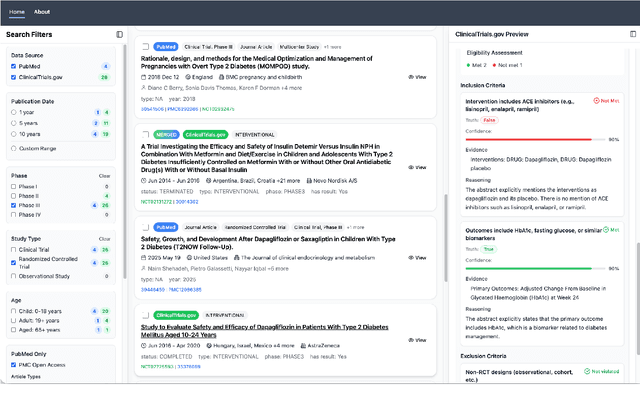
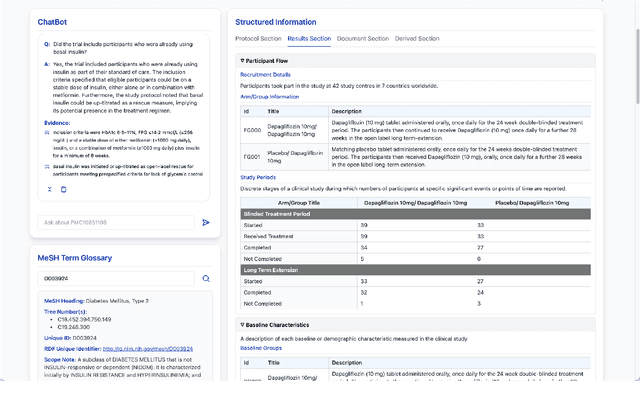

We present ClinicalTrialsHub, an interactive search-focused platform that consolidates all data from ClinicalTrials.gov and augments it by automatically extracting and structuring trial-relevant information from PubMed research articles. Our system effectively increases access to structured clinical trial data by 83.8% compared to relying on ClinicalTrials.gov alone, with potential to make access easier for patients, clinicians, researchers, and policymakers, advancing evidence-based medicine. ClinicalTrialsHub uses large language models such as GPT-5.1 and Gemini-3-Pro to enhance accessibility. The platform automatically parses full-text research articles to extract structured trial information, translates user queries into structured database searches, and provides an attributed question-answering system that generates evidence-grounded answers linked to specific source sentences. We demonstrate its utility through a user study involving clinicians, clinical researchers, and PhD students of pharmaceutical sciences and nursing, and a systematic automatic evaluation of its information extraction and question answering capabilities.
A Deep Subgrouping Framework for Precision Drug Repurposing via Emulating Clinical Trials on Real-world Patient Data
Dec 29, 2024Drug repurposing identifies new therapeutic uses for existing drugs, reducing the time and costs compared to traditional de novo drug discovery. Most existing drug repurposing studies using real-world patient data often treat the entire population as homogeneous, ignoring the heterogeneity of treatment responses across patient subgroups. This approach may overlook promising drugs that benefit specific subgroups but lack notable treatment effects across the entire population, potentially limiting the number of repurposable candidates identified. To address this, we introduce STEDR, a novel drug repurposing framework that integrates subgroup analysis with treatment effect estimation. Our approach first identifies repurposing candidates by emulating multiple clinical trials on real-world patient data and then characterizes patient subgroups by learning subgroup-specific treatment effects. We deploy \model to Alzheimer's Disease (AD), a condition with few approved drugs and known heterogeneity in treatment responses. We emulate trials for over one thousand medications on a large-scale real-world database covering over 8 million patients, identifying 14 drug candidates with beneficial effects to AD in characterized subgroups. Experiments demonstrate STEDR's superior capability in identifying repurposing candidates compared to existing approaches. Additionally, our method can characterize clinically relevant patient subgroups associated with important AD-related risk factors, paving the way for precision drug repurposing.
Teach Multimodal LLMs to Comprehend Electrocardiographic Images
Oct 21, 2024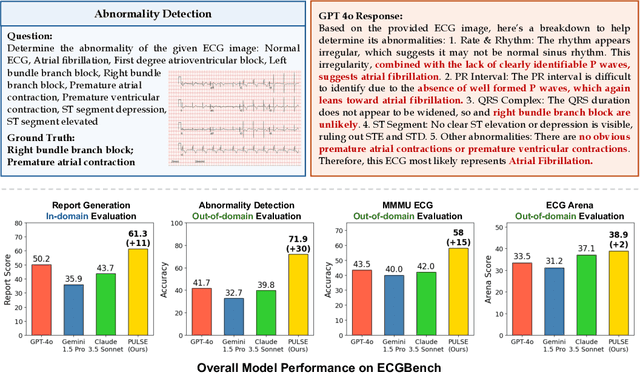



The electrocardiogram (ECG) is an essential non-invasive diagnostic tool for assessing cardiac conditions. Existing automatic interpretation methods suffer from limited generalizability, focusing on a narrow range of cardiac conditions, and typically depend on raw physiological signals, which may not be readily available in resource-limited settings where only printed or digital ECG images are accessible. Recent advancements in multimodal large language models (MLLMs) present promising opportunities for addressing these challenges. However, the application of MLLMs to ECG image interpretation remains challenging due to the lack of instruction tuning datasets and well-established ECG image benchmarks for quantitative evaluation. To address these challenges, we introduce ECGInstruct, a comprehensive ECG image instruction tuning dataset of over one million samples, covering a wide range of ECG-related tasks from diverse data sources. Using ECGInstruct, we develop PULSE, an MLLM tailored for ECG image comprehension. In addition, we curate ECGBench, a new evaluation benchmark covering four key ECG image interpretation tasks across nine different datasets. Our experiments show that PULSE sets a new state-of-the-art, outperforming general MLLMs with an average accuracy improvement of 15% to 30%. This work highlights the potential of PULSE to enhance ECG interpretation in clinical practice.
KG-TREAT: Pre-training for Treatment Effect Estimation by Synergizing Patient Data with Knowledge Graphs
Mar 06, 2024



Treatment effect estimation (TEE) is the task of determining the impact of various treatments on patient outcomes. Current TEE methods fall short due to reliance on limited labeled data and challenges posed by sparse and high-dimensional observational patient data. To address the challenges, we introduce a novel pre-training and fine-tuning framework, KG-TREAT, which synergizes large-scale observational patient data with biomedical knowledge graphs (KGs) to enhance TEE. Unlike previous approaches, KG-TREAT constructs dual-focus KGs and integrates a deep bi-level attention synergy method for in-depth information fusion, enabling distinct encoding of treatment-covariate and outcome-covariate relationships. KG-TREAT also incorporates two pre-training tasks to ensure a thorough grounding and contextualization of patient data and KGs. Evaluation on four downstream TEE tasks shows KG-TREAT's superiority over existing methods, with an average improvement of 7% in Area under the ROC Curve (AUC) and 9% in Influence Function-based Precision of Estimating Heterogeneous Effects (IF-PEHE). The effectiveness of our estimated treatment effects is further affirmed by alignment with established randomized clinical trial findings.
Heterogeneous treatment effect estimation with subpopulation identification for personalized medicine in opioid use disorder
Jan 30, 2024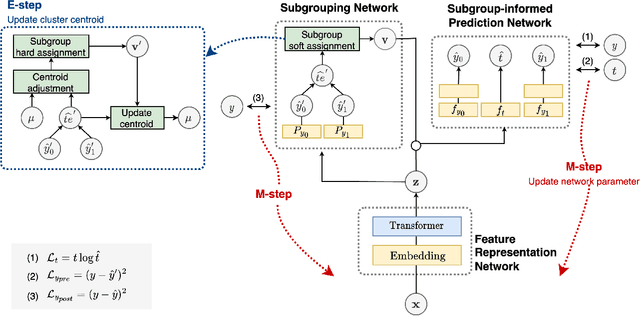
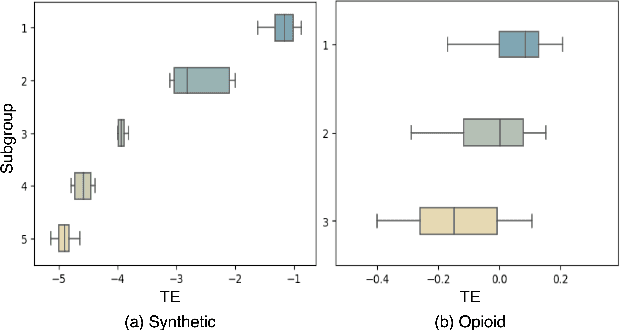
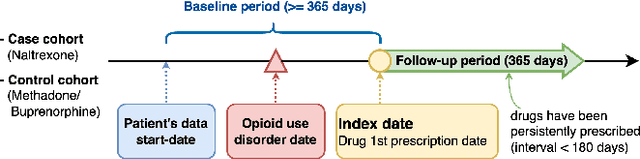
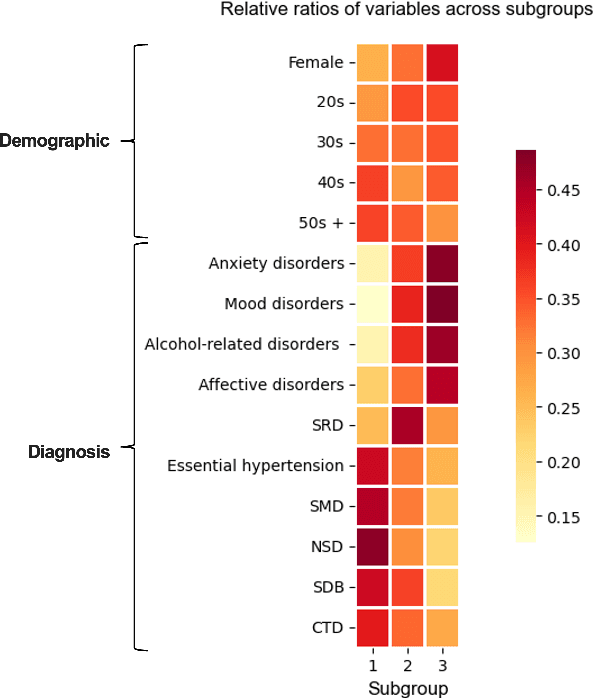
Deep learning models have demonstrated promising results in estimating treatment effects (TEE). However, most of them overlook the variations in treatment outcomes among subgroups with distinct characteristics. This limitation hinders their ability to provide accurate estimations and treatment recommendations for specific subgroups. In this study, we introduce a novel neural network-based framework, named SubgroupTE, which incorporates subgroup identification and treatment effect estimation. SubgroupTE identifies diverse subgroups and simultaneously estimates treatment effects for each subgroup, improving the treatment effect estimation by considering the heterogeneity of treatment responses. Comparative experiments on synthetic data show that SubgroupTE outperforms existing models in treatment effect estimation. Furthermore, experiments on a real-world dataset related to opioid use disorder (OUD) demonstrate the potential of our approach to enhance personalized treatment recommendations for OUD patients.
SubgroupTE: Advancing Treatment Effect Estimation with Subgroup Identification
Jan 22, 2024

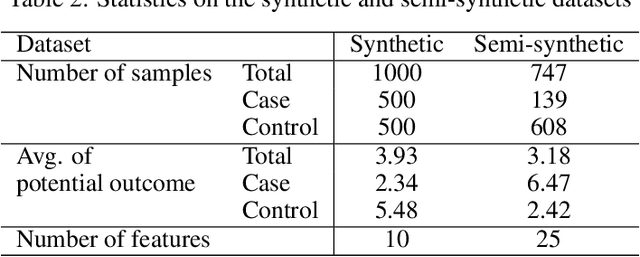
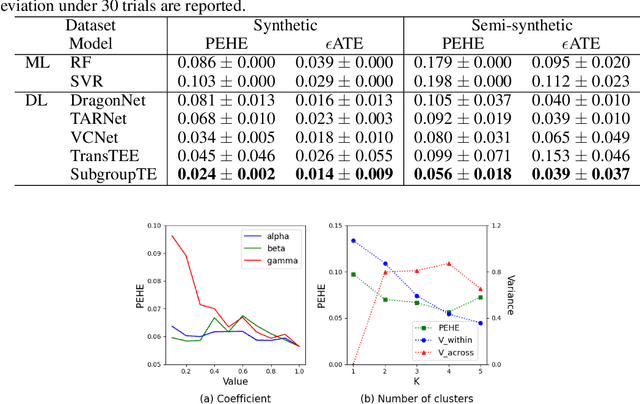
Precise estimation of treatment effects is crucial for evaluating intervention effectiveness. While deep learning models have exhibited promising performance in learning counterfactual representations for treatment effect estimation (TEE), a major limitation in most of these models is that they treat the entire population as a homogeneous group, overlooking the diversity of treatment effects across potential subgroups that have varying treatment effects. This limitation restricts the ability to precisely estimate treatment effects and provide subgroup-specific treatment recommendations. In this paper, we propose a novel treatment effect estimation model, named SubgroupTE, which incorporates subgroup identification in TEE. SubgroupTE identifies heterogeneous subgroups with different treatment responses and more precisely estimates treatment effects by considering subgroup-specific causal effects. In addition, SubgroupTE iteratively optimizes subgrouping and treatment effect estimation networks to enhance both estimation and subgroup identification. Comprehensive experiments on the synthetic and semi-synthetic datasets exhibit the outstanding performance of SubgroupTE compared with the state-of-the-art models on treatment effect estimation. Additionally, a real-world study demonstrates the capabilities of SubgroupTE in enhancing personalized treatment recommendations for patients with opioid use disorder (OUD) by advancing treatment effect estimation with subgroup identification.
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Nov 27, 2023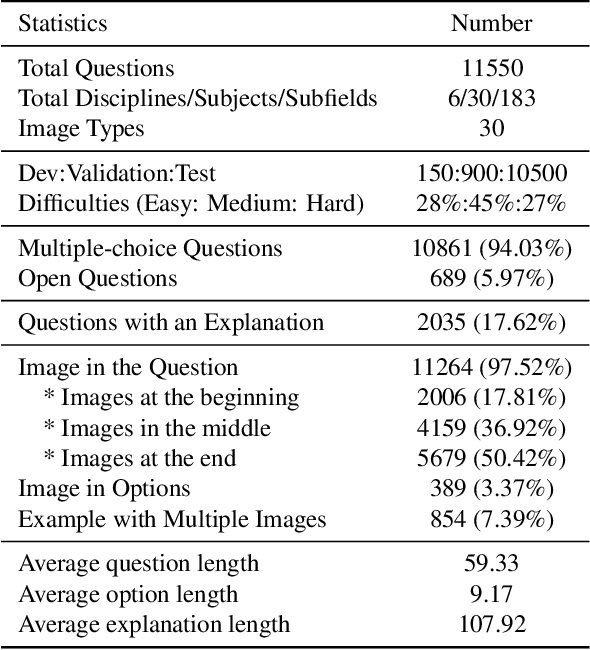

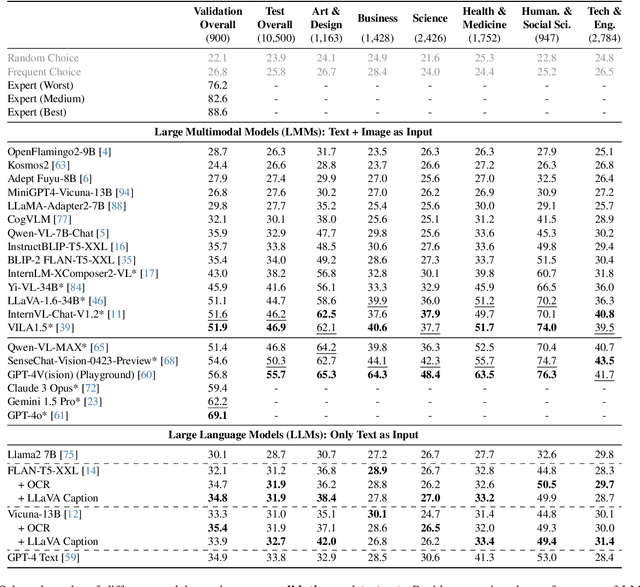
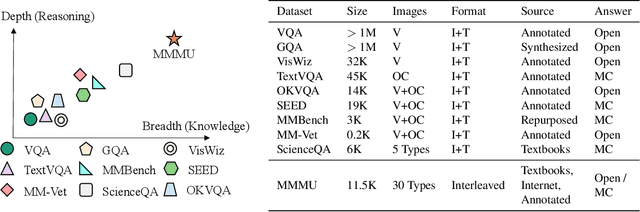
We introduce MMMU: a new benchmark designed to evaluate multimodal models on massive multi-discipline tasks demanding college-level subject knowledge and deliberate reasoning. MMMU includes 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering. These questions span 30 subjects and 183 subfields, comprising 30 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. Unlike existing benchmarks, MMMU focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. Our evaluation of 14 open-source LMMs and the proprietary GPT-4V(ision) highlights the substantial challenges posed by MMMU. Even the advanced GPT-4V only achieves a 56% accuracy, indicating significant room for improvement. We believe MMMU will stimulate the community to build next-generation multimodal foundation models towards expert artificial general intelligence.
Deconfounding Actor-Critic Network with Policy Adaptation for Dynamic Treatment Regimes
May 31, 2022


Despite intense efforts in basic and clinical research, an individualized ventilation strategy for critically ill patients remains a major challenge. Recently, dynamic treatment regime (DTR) with reinforcement learning (RL) on electronic health records (EHR) has attracted interest from both the healthcare industry and machine learning research community. However, most learned DTR policies might be biased due to the existence of confounders. Although some treatment actions non-survivors received may be helpful, if confounders cause the mortality, the training of RL models guided by long-term outcomes (e.g., 90-day mortality) would punish those treatment actions causing the learned DTR policies to be suboptimal. In this study, we develop a new deconfounding actor-critic network (DAC) to learn optimal DTR policies for patients. To alleviate confounding issues, we incorporate a patient resampling module and a confounding balance module into our actor-critic framework. To avoid punishing the effective treatment actions non-survivors received, we design a short-term reward to capture patients' immediate health state changes. Combining short-term with long-term rewards could further improve the model performance. Moreover, we introduce a policy adaptation method to successfully transfer the learned model to new-source small-scale datasets. The experimental results on one semi-synthetic and two different real-world datasets show the proposed model outperforms the state-of-the-art models. The proposed model provides individualized treatment decisions for mechanical ventilation that could improve patient outcomes.
Estimating Individual Treatment Effects with Time-Varying Confounders
Aug 27, 2020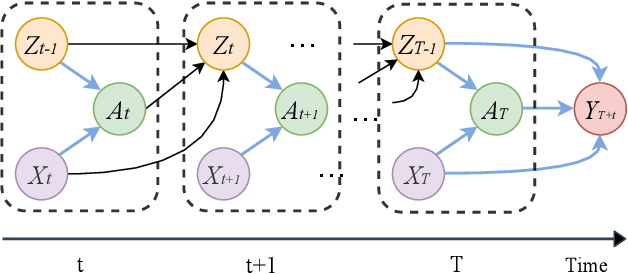
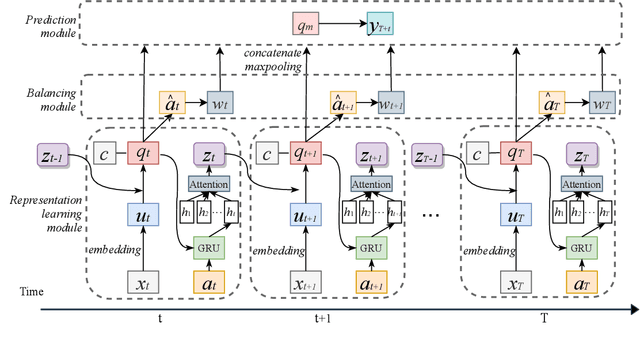

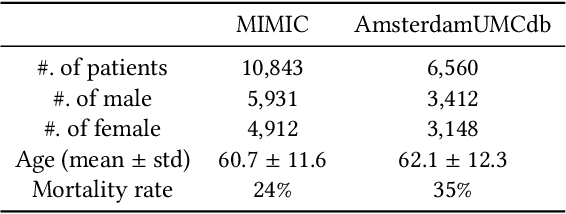
Estimating the individual treatment effect (ITE) from observational data is meaningful and practical in healthcare. Existing work mainly relies on the strong ignorability assumption that no hidden confounders exist, which may lead to bias in estimating causal effects. Some studies consider the hidden confounders are designed for static environment and not easily adaptable to a dynamic setting. In fact, most observational data (e.g., electronic medical records) is naturally dynamic and consists of sequential information. In this paper, we propose Deep Sequential Weighting (DSW) for estimating ITE with time-varying confounders. Specifically, DSW infers the hidden confounders by incorporating the current treatment assignments and historical information using a deep recurrent weighting neural network. The learned representations of hidden confounders combined with current observed data are leveraged for potential outcome and treatment predictions. We compute the time-varying inverse probabilities of treatment for re-weighting the population. We conduct comprehensive comparison experiments on fully-synthetic, semi-synthetic and real-world datasets to evaluate the performance of our model and baselines. Results demonstrate that our model can generate unbiased and accurate treatment effect by conditioning both time-varying observed and hidden confounders, paving the way for personalized medicine.
When deep learning meets causal inference: a computational framework for drug repurposing from real-world data
Jul 16, 2020


Drug repurposing is an effective strategy to identify new uses for existing drugs, providing the quickest possible transition from bench to bedside. Existing methods for drug repurposing that mainly focus on pre-clinical information may exist translational issues when applied to human beings. Real world data (RWD), such as electronic health records and insurance claims, provide information on large cohorts of users for many drugs. Here we present an efficient and easily-customized framework for generating and testing multiple candidates for drug repurposing using a retrospective analysis of RWDs. Building upon well-established causal inference and deep learning methods, our framework emulates randomized clinical trials for drugs present in a large-scale medical claims database. We demonstrate our framework in a case study of coronary artery disease (CAD) by evaluating the effect of 55 repurposing drug candidates on various disease outcomes. We achieve 6 drug candidates that significantly improve the CAD outcomes but not have been indicated for treating CAD, paving the way for drug repurposing.