 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Subgrouping Framework for Precision Drug Repurposing via Emulating Clinical Trials on Real-world Patient Data
Dec 29, 2024Drug repurposing identifies new therapeutic uses for existing drugs, reducing the time and costs compared to traditional de novo drug discovery. Most existing drug repurposing studies using real-world patient data often treat the entire population as homogeneous, ignoring the heterogeneity of treatment responses across patient subgroups. This approach may overlook promising drugs that benefit specific subgroups but lack notable treatment effects across the entire population, potentially limiting the number of repurposable candidates identified. To address this, we introduce STEDR, a novel drug repurposing framework that integrates subgroup analysis with treatment effect estimation. Our approach first identifies repurposing candidates by emulating multiple clinical trials on real-world patient data and then characterizes patient subgroups by learning subgroup-specific treatment effects. We deploy \model to Alzheimer's Disease (AD), a condition with few approved drugs and known heterogeneity in treatment responses. We emulate trials for over one thousand medications on a large-scale real-world database covering over 8 million patients, identifying 14 drug candidates with beneficial effects to AD in characterized subgroups. Experiments demonstrate STEDR's superior capability in identifying repurposing candidates compared to existing approaches. Additionally, our method can characterize clinically relevant patient subgroups associated with important AD-related risk factors, paving the way for precision drug repurposing.
Multi-view biomedical foundation models for molecule-target and property prediction
Oct 25, 2024


Foundation models applied to bio-molecular space hold promise to accelerate drug discovery. Molecular representation is key to building such models. Previous works have typically focused on a single representation or view of the molecules. Here, we develop a multi-view foundation model approach, that integrates molecular views of graph, image and text. Single-view foundation models are each pre-trained on a dataset of up to 200M molecules and then aggregated into combined representations. Our multi-view model is validated on a diverse set of 18 tasks, encompassing ligand-protein binding, molecular solubility, metabolism and toxicity. We show that the multi-view models perform robustly and are able to balance the strengths and weaknesses of specific views. We then apply this model to screen compounds against a large (>100 targets) set of G Protein-Coupled receptors (GPCRs). From this library of targets, we identify 33 that are related to Alzheimer's disease. On this subset, we employ our model to identify strong binders, which are validated through structure-based modeling and identification of key binding motifs.
Multimodal Machine Learning in Precision Health
Apr 10, 2022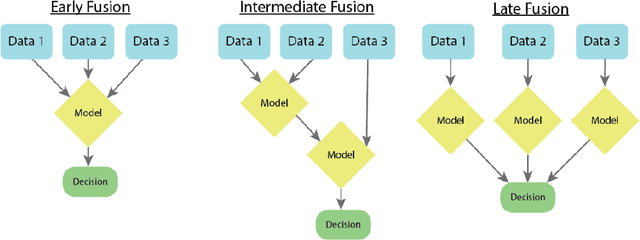
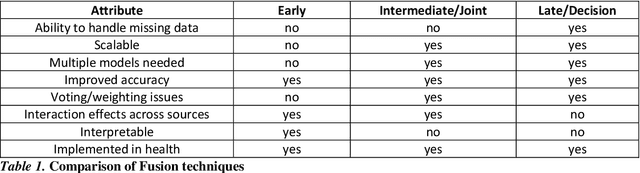

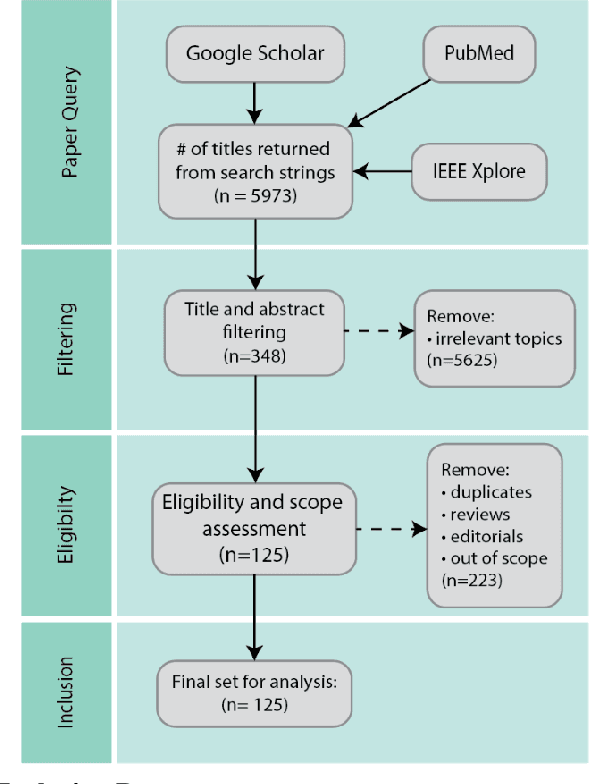
As machine learning and artificial intelligence are more frequently being leveraged to tackle problems in the health sector, there has been increased interest in utilizing them in clinical decision-support. This has historically been the case in single modal data such as electronic health record data. Attempts to improve prediction and resemble the multimodal nature of clinical expert decision-making this has been met in the computational field of machine learning by a fusion of disparate data. This review was conducted to summarize this field and identify topics ripe for future research. We conducted this review in accordance with the PRISMA (Preferred Reporting Items for Systematic reviews and Meta-Analyses) extension for Scoping Reviews to characterize multi-modal data fusion in health. We used a combination of content analysis and literature searches to establish search strings and databases of PubMed, Google Scholar, and IEEEXplore from 2011 to 2021. A final set of 125 articles were included in the analysis. The most common health areas utilizing multi-modal methods were neurology and oncology. However, there exist a wide breadth of current applications. The most common form of information fusion was early fusion. Notably, there was an improvement in predictive performance performing heterogeneous data fusion. Lacking from the papers were clear clinical deployment strategies and pursuit of FDA-approved tools. These findings provide a map of the current literature on multimodal data fusion as applied to health diagnosis/prognosis problems. Multi-modal machine learning, while more robust in its estimations over unimodal methods, has drawbacks in its scalability and the time-consuming nature of information concatenation.
Deep learning for drug repurposing: methods, databases, and applications
Feb 08, 2022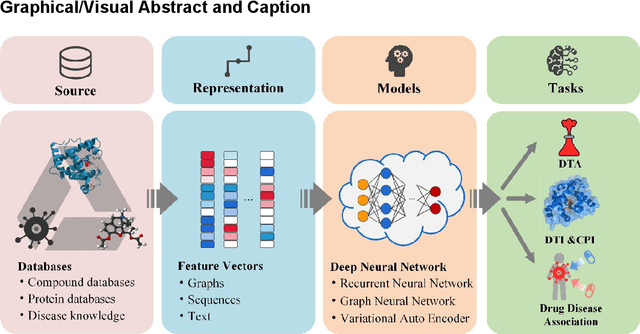
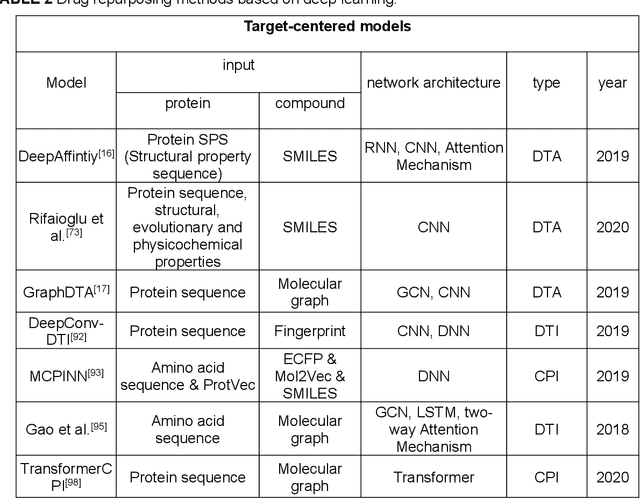
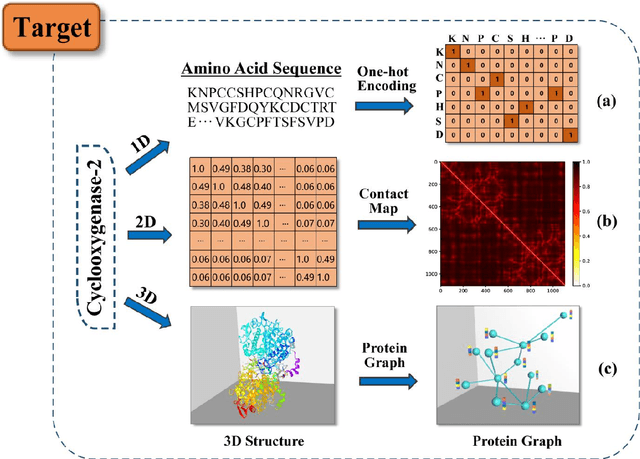
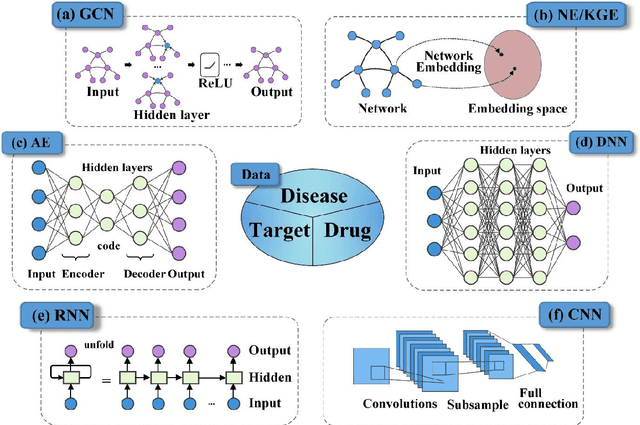
Drug development is time-consuming and expensive. Repurposing existing drugs for new therapies is an attractive solution that accelerates drug development at reduced experimental costs, specifically for Coronavirus Disease 2019 (COVID-19), an infectious disease caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). However, comprehensively obtaining and productively integrating available knowledge and big biomedical data to effectively advance deep learning models is still challenging for drug repurposing in other complex diseases. In this review, we introduce guidelines on how to utilize deep learning methodologies and tools for drug repurposing. We first summarized the commonly used bioinformatics and pharmacogenomics databases for drug repurposing. Next, we discuss recently developed sequence-based and graph-based representation approaches as well as state-of-the-art deep learning-based methods. Finally, we present applications of drug repurposing to fight the COVID-19 pandemic, and outline its future challenges.
Repurpose Open Data to Discover Therapeutics for COVID-19 using Deep Learning
May 21, 2020There have been more than 850,000 confirmed cases and over 48,000 deaths from the human coronavirus disease 2019 (COVID-19) pandemic, caused by novel severe acute respiratory syndrome coronavirus (SARS-CoV-2), in the United States alone. However, there are currently no proven effective medications against COVID-19. Drug repurposing offers a promising way for the development of prevention and treatment strategies for COVID-19. This study reports an integrative, network-based deep learning methodology to identify repurposable drugs for COVID-19 (termed CoV-KGE). Specifically, we built a comprehensive knowledge graph that includes 15 million edges across 39 types of relationships connecting drugs, diseases, genes, pathways, and expressions, from a large scientific corpus of 24 million PubMed publications. Using Amazon AWS computing resources, we identified 41 repurposable drugs (including indomethacin, toremifene and niclosamide) whose therapeutic association with COVID-19 were validated by transcriptomic and proteomic data in SARS-CoV-2 infected human cells and data from ongoing clinical trials. While this study, by no means recommends specific drugs, it demonstrates a powerful deep learning methodology to prioritize existing drugs for further investigation, which holds the potential of accelerating therapeutic development for COVID-19.