 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepDR: an integrated deep-learning model web server for drug repositioning
Nov 12, 2025Background: Identifying new indications for approved drugs is a complex and time-consuming process that requires extensive knowledge of pharmacology, clinical data, and advanced computational methods. Recently, deep learning (DL) methods have shown their capability for the accurate prediction of drug repositioning. However, implementing DL-based modeling requires in-depth domain knowledge and proficient programming skills. Results: In this application, we introduce DeepDR, the first integrated platform that combines a variety of established DL-based models for disease- and target-specific drug repositioning tasks. DeepDR leverages invaluable experience to recommend candidate drugs, which covers more than 15 networks and a comprehensive knowledge graph that includes 5.9 million edges across 107 types of relationships connecting drugs, diseases, proteins/genes, pathways, and expression from six existing databases and a large scientific corpus of 24 million PubMed publications. Additionally, the recommended results include detailed descriptions of the recommended drugs and visualize key patterns with interpretability through a knowledge graph. Conclusion: DeepDR is free and open to all users without the requirement of registration. We believe it can provide an easy-to-use, systematic, highly accurate, and computationally automated platform for both experimental and computational scientists.
Y-Mol: A Multiscale Biomedical Knowledge-Guided Large Language Model for Drug Development
Oct 15, 2024Large Language Models (LLMs) have recently demonstrated remarkable performance in general tasks across various fields. However, their effectiveness within specific domains such as drug development remains challenges. To solve these challenges, we introduce \textbf{Y-Mol}, forming a well-established LLM paradigm for the flow of drug development. Y-Mol is a multiscale biomedical knowledge-guided LLM designed to accomplish tasks across lead compound discovery, pre-clinic, and clinic prediction. By integrating millions of multiscale biomedical knowledge and using LLaMA2 as the base LLM, Y-Mol augments the reasoning capability in the biomedical domain by learning from a corpus of publications, knowledge graphs, and expert-designed synthetic data. The capability is further enriched with three types of drug-oriented instructions: description-based prompts from processed publications, semantic-based prompts for extracting associations from knowledge graphs, and template-based prompts for understanding expert knowledge from biomedical tools. Besides, Y-Mol offers a set of LLM paradigms that can autonomously execute the downstream tasks across the entire process of drug development, including virtual screening, drug design, pharmacological properties prediction, and drug-related interaction prediction. Our extensive evaluations of various biomedical sources demonstrate that Y-Mol significantly outperforms general-purpose LLMs in discovering lead compounds, predicting molecular properties, and identifying drug interaction events.
Deep learning for drug repurposing: methods, databases, and applications
Feb 08, 2022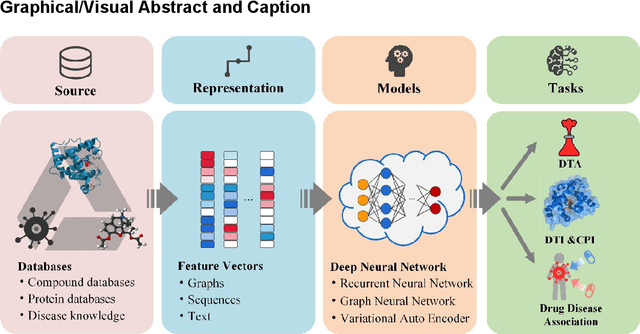
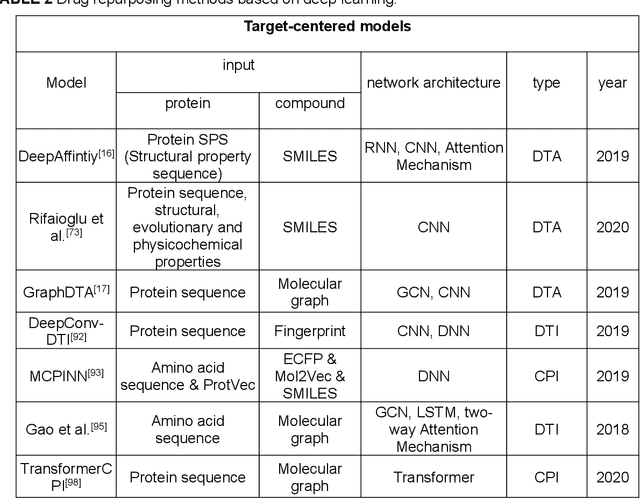
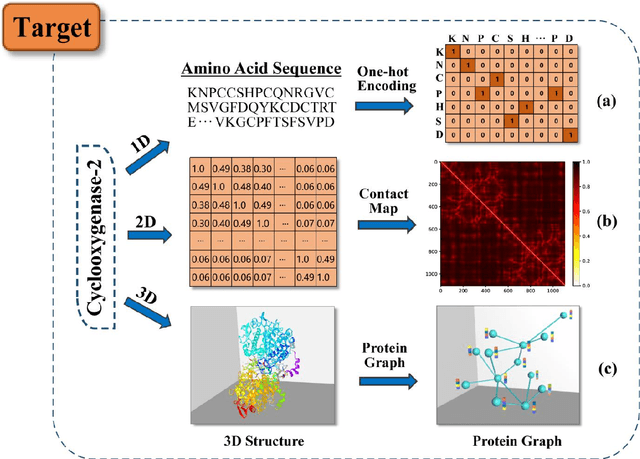
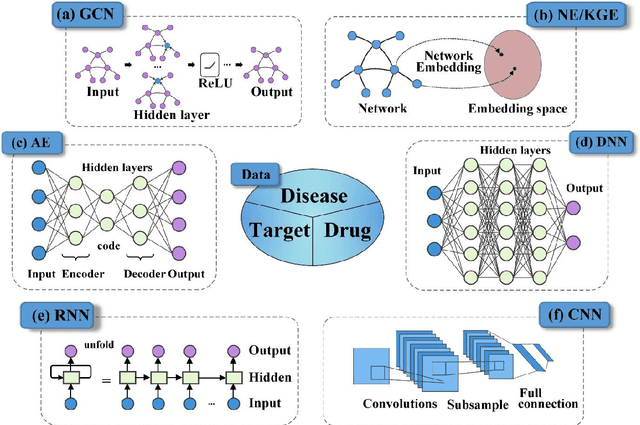
Drug development is time-consuming and expensive. Repurposing existing drugs for new therapies is an attractive solution that accelerates drug development at reduced experimental costs, specifically for Coronavirus Disease 2019 (COVID-19), an infectious disease caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). However, comprehensively obtaining and productively integrating available knowledge and big biomedical data to effectively advance deep learning models is still challenging for drug repurposing in other complex diseases. In this review, we introduce guidelines on how to utilize deep learning methodologies and tools for drug repurposing. We first summarized the commonly used bioinformatics and pharmacogenomics databases for drug repurposing. Next, we discuss recently developed sequence-based and graph-based representation approaches as well as state-of-the-art deep learning-based methods. Finally, we present applications of drug repurposing to fight the COVID-19 pandemic, and outline its future challenges.
An Integrated Transfer Learning and Multitask Learning Approach for Pharmacokinetic Parameter Prediction
Dec 21, 2018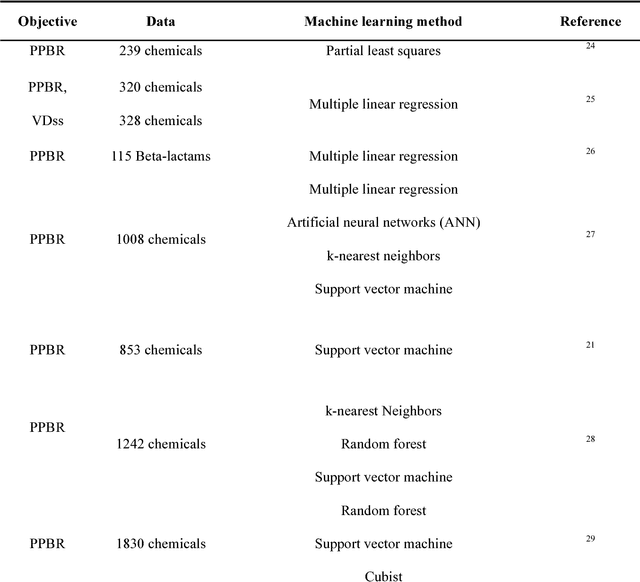
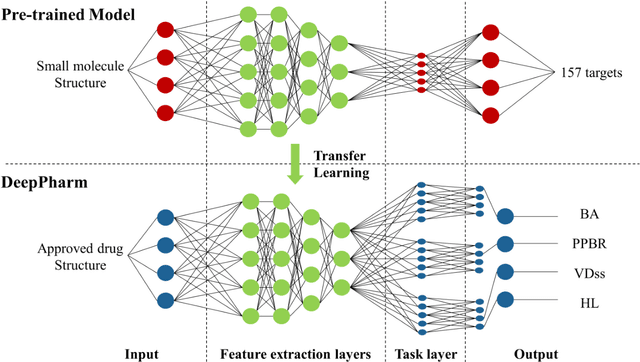
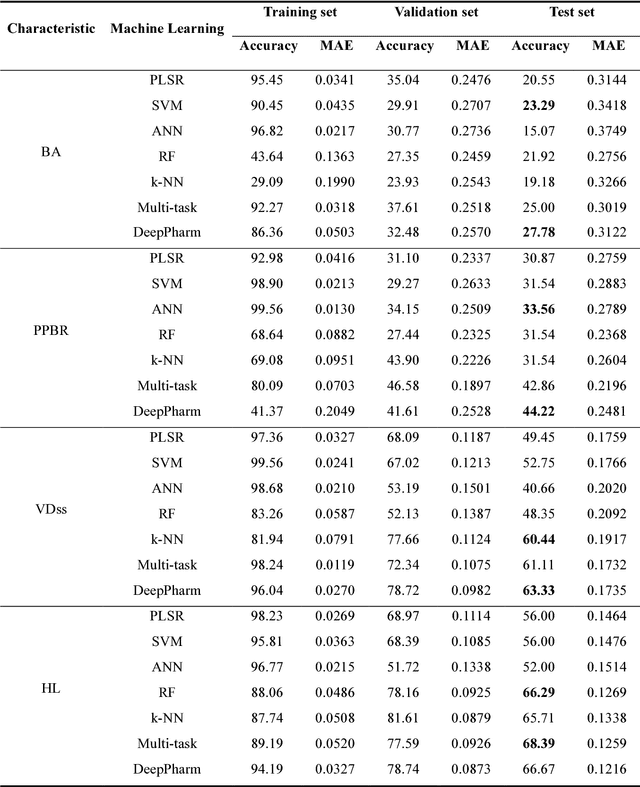

Background: Pharmacokinetic evaluation is one of the key processes in drug discovery and development. However, current absorption, distribution, metabolism, excretion prediction models still have limited accuracy. Aim: This study aims to construct an integrated transfer learning and multitask learning approach for developing quantitative structure-activity relationship models to predict four human pharmacokinetic parameters. Methods: A pharmacokinetic dataset included 1104 U.S. FDA approved small molecule drugs. The dataset included four human pharmacokinetic parameter subsets (oral bioavailability, plasma protein binding rate, apparent volume of distribution at steady-state and elimination half-life). The pre-trained model was trained on over 30 million bioactivity data. An integrated transfer learning and multitask learning approach was established to enhance the model generalization. Results: The pharmacokinetic dataset was split into three parts (60:20:20) for training, validation and test by the improved Maximum Dissimilarity algorithm with the representative initial set selection algorithm and the weighted distance function. The multitask learning techniques enhanced the model predictive ability. The integrated transfer learning and multitask learning model demonstrated the best accuracies, because deep neural networks have the general feature extraction ability, transfer learning and multitask learning improved the model generalization. Conclusions: The integrated transfer learning and multitask learning approach with the improved dataset splitting algorithm was firstly introduced to predict the pharmacokinetic parameters. This method can be further employed in drug discovery and development.