 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Integrated Transfer Learning and Multitask Learning Approach for Pharmacokinetic Parameter Prediction
Dec 21, 2018
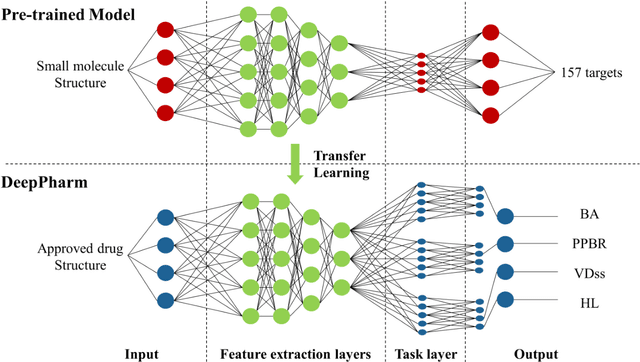
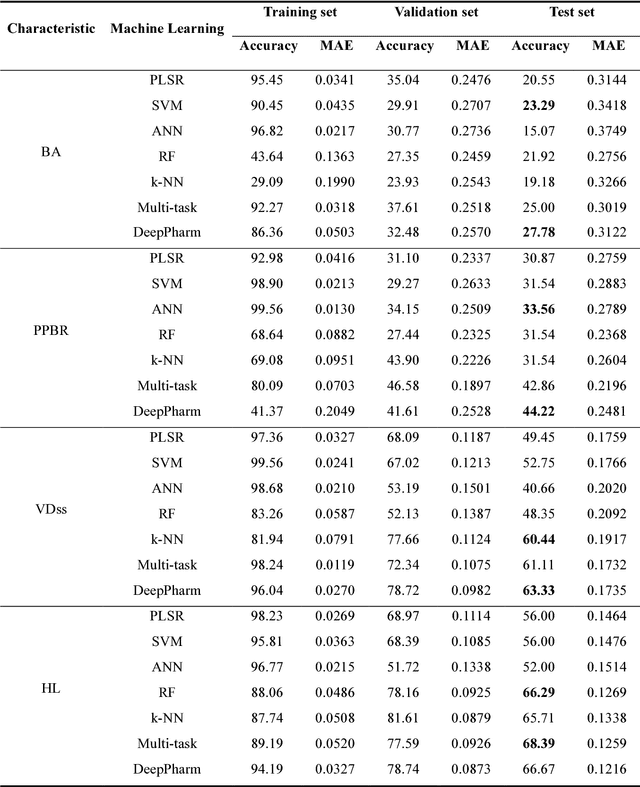

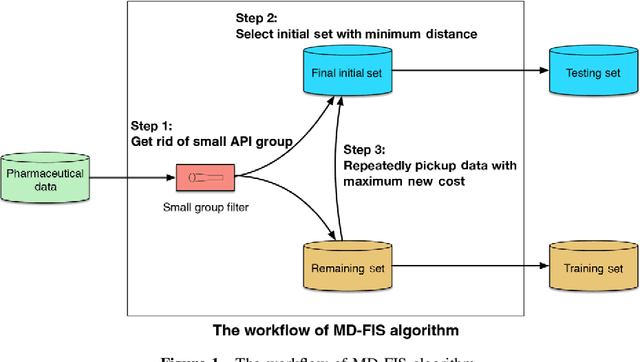
Background: Pharmacokinetic evaluation is one of the key processes in drug discovery and development. However, current absorption, distribution, metabolism, excretion prediction models still have limited accuracy. Aim: This study aims to construct an integrated transfer learning and multitask learning approach for developing quantitative structure-activity relationship models to predict four human pharmacokinetic parameters. Methods: A pharmacokinetic dataset included 1104 U.S. FDA approved small molecule drugs. The dataset included four human pharmacokinetic parameter subsets (oral bioavailability, plasma protein binding rate, apparent volume of distribution at steady-state and elimination half-life). The pre-trained model was trained on over 30 million bioactivity data. An integrated transfer learning and multitask learning approach was established to enhance the model generalization. Results: The pharmacokinetic dataset was split into three parts (60:20:20) for training, validation and test by the improved Maximum Dissimilarity algorithm with the representative initial set selection algorithm and the weighted distance function. The multitask learning techniques enhanced the model predictive ability. The integrated transfer learning and multitask learning model demonstrated the best accuracies, because deep neural networks have the general feature extraction ability, transfer learning and multitask learning improved the model generalization. Conclusions: The integrated transfer learning and multitask learning approach with the improved dataset splitting algorithm was firstly introduced to predict the pharmacokinetic parameters. This method can be further employed in drug discovery and development.
Deep learning for in vitro prediction of pharmaceutical formulations
Sep 06, 2018

Current pharmaceutical formulation development still strongly relies on the traditional trial-and-error approach by individual experiences of pharmaceutical scientists, which is laborious, time-consuming and costly. Recently, deep learning has been widely applied in many challenging domains because of its important capability of automatic feature extraction. The aim of this research is to use deep learning to predict pharmaceutical formulations. In this paper, two different types of dosage forms were chosen as model systems. Evaluation criteria suitable for pharmaceutics were applied to assessing the performance of the models. Moreover, an automatic dataset selection algorithm was developed for selecting the representative data as validation and test datasets. Six machine learning methods were compared with deep learning. The result shows the accuracies of both two deep neural networks were above 80% and higher than other machine learning models, which showed good prediction in pharmaceutical formulations. In summary, deep learning with the automatic data splitting algorithm and the evaluation criteria suitable for pharmaceutical formulation data was firstly developed for the prediction of pharmaceutical formulations. The cross-disciplinary integration of pharmaceutics and artificial intelligence may shift the paradigm of pharmaceutical researches from experience-dependent studies to data-driven methodologies.
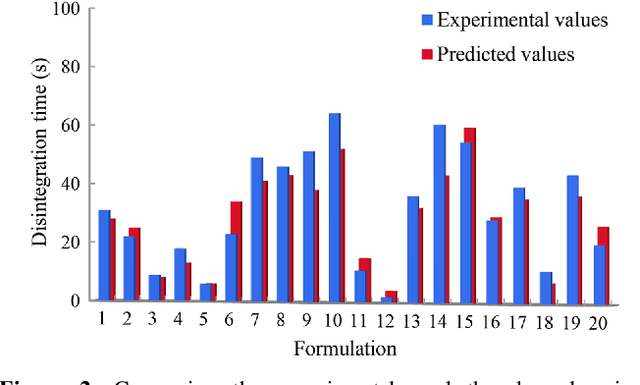
Predicting Oral Disintegrating Tablet Formulations by Neural Network Techniques
Mar 14, 2018
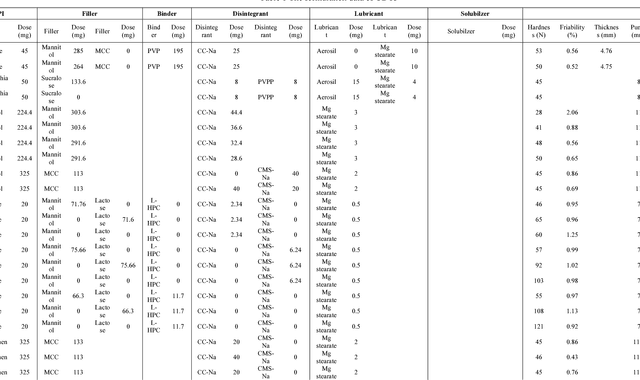
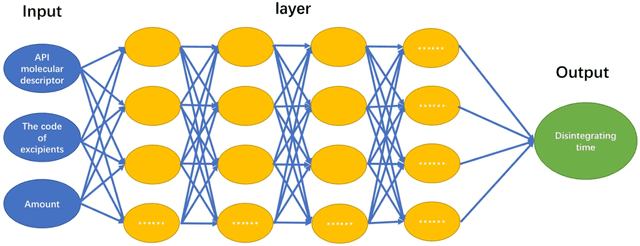

Oral Disintegrating Tablets (ODTs) is a novel dosage form that can be dissolved on the tongue within 3min or less especially for geriatric and pediatric patients. Current ODT formulation studies usually rely on the personal experience of pharmaceutical experts and trial-and-error in the laboratory, which is inefficient and time-consuming. The aim of current research was to establish the prediction model of ODT formulations with direct compression process by Artificial Neural Network (ANN) and Deep Neural Network (DNN) techniques. 145 formulation data were extracted from Web of Science. All data sets were divided into three parts: training set (105 data), validation set (20) and testing set (20). ANN and DNN were compared for the prediction of the disintegrating time. The accuracy of the ANN model has reached 85.60%, 80.00% and 75.00% on the training set, validation set and testing set respectively, whereas that of the DNN model was 85.60%, 85.00% and 80.00%, respectively. Compared with the ANN, DNN showed the better prediction for ODT formulations. It is the first time that deep neural network with the improved dataset selection algorithm is applied to formulation prediction on small data. The proposed predictive approach could evaluate the critical parameters about quality control of formulation, and guide research and process development. The implementation of this prediction model could effectively reduce drug product development timeline and material usage, and proactively facilitate the development of a robust drug product.