 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generation and Mitigation of Harmful Geometry in Image-to-3D Models
May 10, 2026Recent advances in image-to-3D models have significantly improved the fidelity and accessibility of 3D content creation. Such a powerful reconstruction capability that enables creative design can also be misused by the adversary to generate harmful geometries, which can be further fabricated via 3D printers and pose real-world risks. However, such risks are largely underexplored: it remains unclear how well current image-to-3D models can produce these harmful geometries, and whether existing safeguards can reliably prevent such generation. To fill this gap, we conduct a systematic measurement study of harmful geometry generation and mitigation. We first describe this risk through three kinds of unsafe categories: direct-use physical hazards, risky templates or components, and deceptive replicas. Each category is instantiated with representative objects. We evaluate both open-source and commercial image-to-3D models under original, degraded, viewpoint-shifted, and semantically camouflaged inputs. We consider different evaluation metrics, including geometric validity, multi-view VLM-based semantic scoring, targeted human validation, and controlled physical fabrication. The results reveal a concerning reality that current image-to-3D models can effectively reconstruct the harmful geometries, while fewer than 0.3% of such geometries trigger commercial moderation flags. As a first step toward mitigation, we evaluate three representative safeguard families, including input moderation, model-level benign alignment, and output-level filtering. We find that existing safeguards have distinct weaknesses. We further develop a stacked defense that can reduce harmful retention to <1%, but still at 11% overall false-positive cost. Taken together, our findings demonstrate that the risk in current system and encourage better geometry-aware safeguards for moderation.
Discover, Segment, and Select: A Progressive Mechanism for Zero-shot Camouflaged Object Segmentation
Feb 23, 2026Current zero-shot Camouflaged Object Segmentation methods typically employ a two-stage pipeline (discover-then-segment): using MLLMs to obtain visual prompts, followed by SAM segmentation. However, relying solely on MLLMs for camouflaged object discovery often leads to inaccurate localization, false positives, and missed detections. To address these issues, we propose the \textbf{D}iscover-\textbf{S}egment-\textbf{S}elect (\textbf{DSS}) mechanism, a progressive framework designed to refine segmentation step by step. The proposed method contains a Feature-coherent Object Discovery (FOD) module that leverages visual features to generate diverse object proposals, a segmentation module that refines these proposals through SAM segmentation, and a Semantic-driven Mask Selection (SMS) module that employs MLLMs to evaluate and select the optimal segmentation mask from multiple candidates. Without requiring any training or supervision, DSS achieves state-of-the-art performance on multiple COS benchmarks, especially in multiple-instance scenes.
GRPO Privacy Is at Risk: A Membership Inference Attack Against Reinforcement Learning With Verifiable Rewards
Nov 18, 2025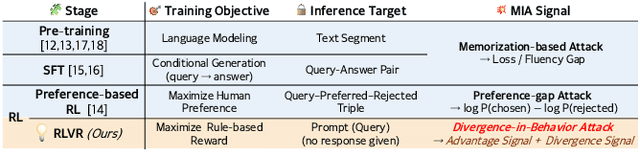
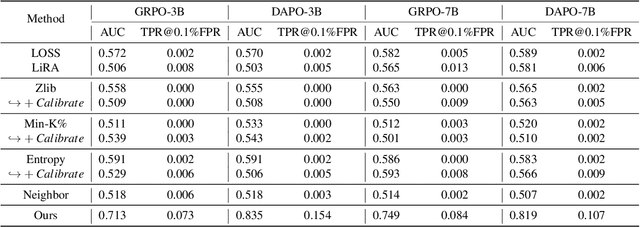
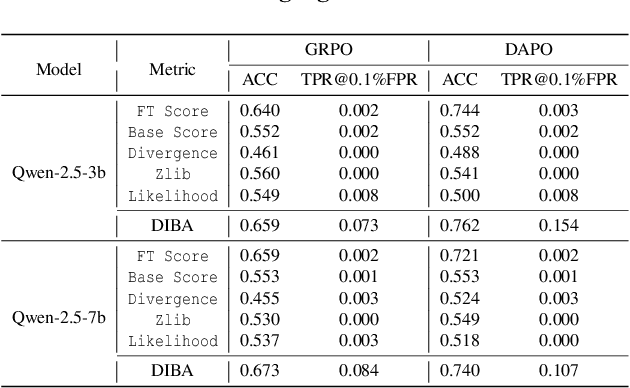
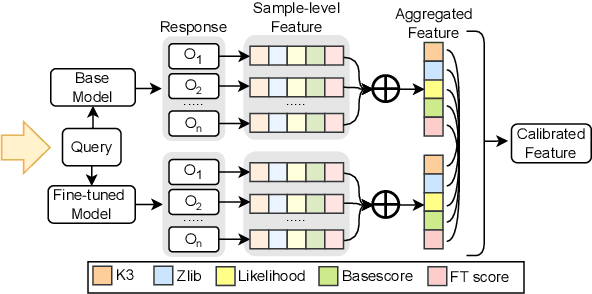
Membership inference attacks (MIAs) on large language models (LLMs) pose significant privacy risks across various stages of model training. Recent advances in Reinforcement Learning with Verifiable Rewards (RLVR) have brought a profound paradigm shift in LLM training, particularly for complex reasoning tasks. However, the on-policy nature of RLVR introduces a unique privacy leakage pattern: since training relies on self-generated responses without fixed ground-truth outputs, membership inference must now determine whether a given prompt (independent of any specific response) is used during fine-tuning. This creates a threat where leakage arises not from answer memorization. To audit this novel privacy risk, we propose Divergence-in-Behavior Attack (DIBA), the first membership inference framework specifically designed for RLVR. DIBA shifts the focus from memorization to behavioral change, leveraging measurable shifts in model behavior across two axes: advantage-side improvement (e.g., correctness gain) and logit-side divergence (e.g., policy drift). Through comprehensive evaluations, we demonstrate that DIBA significantly outperforms existing baselines, achieving around 0.8 AUC and an order-of-magnitude higher TPR@0.1%FPR. We validate DIBA's superiority across multiple settings--including in-distribution, cross-dataset, cross-algorithm, black-box scenarios, and extensions to vision-language models. Furthermore, our attack remains robust under moderate defensive measures. To the best of our knowledge, this is the first work to systematically analyze privacy vulnerabilities in RLVR, revealing that even in the absence of explicit supervision, training data exposure can be reliably inferred through behavioral traces.
Improving Sustainability of Adversarial Examples in Class-Incremental Learning
Nov 12, 2025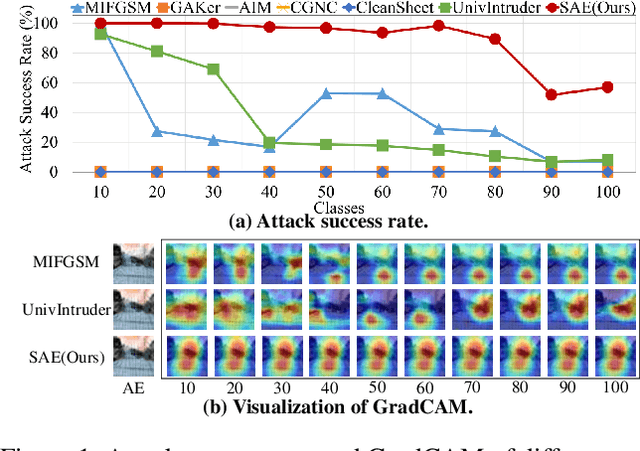
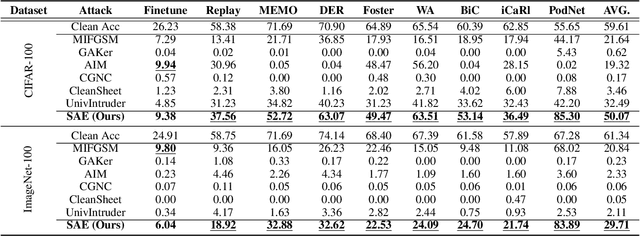
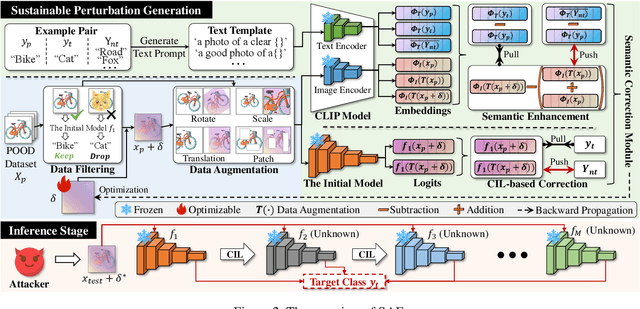

Current adversarial examples (AEs) are typically designed for static models. However, with the wide application of Class-Incremental Learning (CIL), models are no longer static and need to be updated with new data distributed and labeled differently from the old ones. As a result, existing AEs often fail after CIL updates due to significant domain drift. In this paper, we propose SAE to enhance the sustainability of AEs against CIL. The core idea of SAE is to enhance the robustness of AE semantics against domain drift by making them more similar to the target class while distinguishing them from all other classes. Achieving this is challenging, as relying solely on the initial CIL model to optimize AE semantics often leads to overfitting. To resolve the problem, we propose a Semantic Correction Module. This module encourages the AE semantics to be generalized, based on a visual-language model capable of producing universal semantics. Additionally, it incorporates the CIL model to correct the optimization direction of the AE semantics, guiding them closer to the target class. To further reduce fluctuations in AE semantics, we propose a Filtering-and-Augmentation Module, which first identifies non-target examples with target-class semantics in the latent space and then augments them to foster more stable semantics. Comprehensive experiments demonstrate that SAE outperforms baselines by an average of 31.28% when updated with a 9-fold increase in the number of classes.
NICE: Improving Panoptic Narrative Detection and Segmentation with Cascading Collaborative Learning
Oct 23, 2023Panoptic Narrative Detection (PND) and Segmentation (PNS) are two challenging tasks that involve identifying and locating multiple targets in an image according to a long narrative description. In this paper, we propose a unified and effective framework called NICE that can jointly learn these two panoptic narrative recognition tasks. Existing visual grounding tasks use a two-branch paradigm, but applying this directly to PND and PNS can result in prediction conflict due to their intrinsic many-to-many alignment property. To address this, we introduce two cascading modules based on the barycenter of the mask, which are Coordinate Guided Aggregation (CGA) and Barycenter Driven Localization (BDL), responsible for segmentation and detection, respectively. By linking PNS and PND in series with the barycenter of segmentation as the anchor, our approach naturally aligns the two tasks and allows them to complement each other for improved performance. Specifically, CGA provides the barycenter as a reference for detection, reducing BDL's reliance on a large number of candidate boxes. BDL leverages its excellent properties to distinguish different instances, which improves the performance of CGA for segmentation. Extensive experiments demonstrate that NICE surpasses all existing methods by a large margin, achieving 4.1% for PND and 2.9% for PNS over the state-of-the-art. These results validate the effectiveness of our proposed collaborative learning strategy. The project of this work is made publicly available at https://github.com/Mr-Neko/NICE.
3D Shape-Based Myocardial Infarction Prediction Using Point Cloud Classification Networks
Jul 14, 2023



Myocardial infarction (MI) is one of the most prevalent cardiovascular diseases with associated clinical decision-making typically based on single-valued imaging biomarkers. However, such metrics only approximate the complex 3D structure and physiology of the heart and hence hinder a better understanding and prediction of MI outcomes. In this work, we investigate the utility of complete 3D cardiac shapes in the form of point clouds for an improved detection of MI events. To this end, we propose a fully automatic multi-step pipeline consisting of a 3D cardiac surface reconstruction step followed by a point cloud classification network. Our method utilizes recent advances in geometric deep learning on point clouds to enable direct and efficient multi-scale learning on high-resolution surface models of the cardiac anatomy. We evaluate our approach on 1068 UK Biobank subjects for the tasks of prevalent MI detection and incident MI prediction and find improvements of ~13% and ~5% respectively over clinical benchmarks. Furthermore, we analyze the role of each ventricle and cardiac phase for 3D shape-based MI detection and conduct a visual analysis of the morphological and physiological patterns typically associated with MI outcomes.
Rotation-Scale Equivariant Steerable Filters
Apr 10, 2023Incorporating either rotation equivariance or scale equivariance into CNNs has proved to be effective in improving models' generalization performance. However, jointly integrating rotation and scale equivariance into CNNs has not been widely explored. Digital histology imaging of biopsy tissue can be captured at arbitrary orientation and magnification and stored at different resolutions, resulting in cells appearing in different scales. When conventional CNNs are applied to histopathology image analysis, the generalization performance of models is limited because 1) a part of the parameters of filters are trained to fit rotation transformation, thus decreasing the capability of learning other discriminative features; 2) fixed-size filters trained on images at a given scale fail to generalize to those at different scales. To deal with these issues, we propose the Rotation-Scale Equivariant Steerable Filter (RSESF), which incorporates steerable filters and scale-space theory. The RSESF contains copies of filters that are linear combinations of Gaussian filters, whose direction is controlled by directional derivatives and whose scale parameters are trainable but constrained to span disjoint scales in successive layers of the network. Extensive experiments on two gland segmentation datasets demonstrate that our method outperforms other approaches, with much fewer trainable parameters and fewer GPU resources required. The source code is available at: https://github.com/ynulonger/RSESF.
ADS_UNet: A Nested UNet for Histopathology Image Segmentation
Apr 10, 2023The UNet model consists of fully convolutional network (FCN) layers arranged as contracting encoder and upsampling decoder maps. Nested arrangements of these encoder and decoder maps give rise to extensions of the UNet model, such as UNete and UNet++. Other refinements include constraining the outputs of the convolutional layers to discriminate between segment labels when trained end to end, a property called deep supervision. This reduces feature diversity in these nested UNet models despite their large parameter space. Furthermore, for texture segmentation, pixel correlations at multiple scales contribute to the classification task; hence, explicit deep supervision of shallower layers is likely to enhance performance. In this paper, we propose ADS UNet, a stage-wise additive training algorithm that incorporates resource-efficient deep supervision in shallower layers and takes performance-weighted combinations of the sub-UNets to create the segmentation model. We provide empirical evidence on three histopathology datasets to support the claim that the proposed ADS UNet reduces correlations between constituent features and improves performance while being more resource efficient. We demonstrate that ADS_UNet outperforms state-of-the-art Transformer-based models by 1.08 and 0.6 points on CRAG and BCSS datasets, and yet requires only 37% of GPU consumption and 34% of training time as that required by Transformers.
Scale-Equivariant UNet for Histopathology Image Segmentation
Apr 10, 2023Digital histopathology slides are scanned and viewed under different magnifications and stored as images at different resolutions. Convolutional Neural Networks (CNNs) trained on such images at a given scale fail to generalise to those at different scales. This inability is often addressed by augmenting training data with re-scaled images, allowing a model with sufficient capacity to learn the requisite patterns. Alternatively, designing CNN filters to be scale-equivariant frees up model capacity to learn discriminative features. In this paper, we propose the Scale-Equivariant UNet (SEUNet) for image segmentation by building on scale-space theory. The SEUNet contains groups of filters that are linear combinations of Gaussian basis filters, whose scale parameters are trainable but constrained to span disjoint scales through the layers of the network. Extensive experiments on a nuclei segmentation dataset and a tissue type segmentation dataset demonstrate that our method outperforms other approaches, with much fewer trainable parameters.
Cloud-based Federated Boosting for Mobile Crowdsensing
May 09, 2020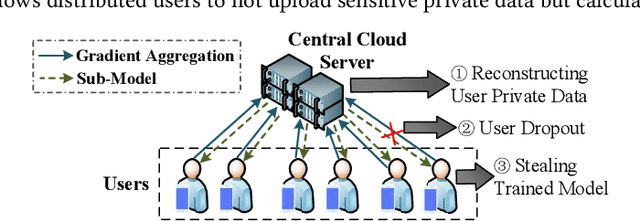

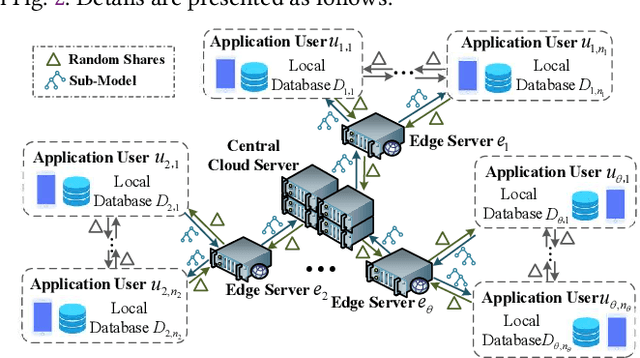
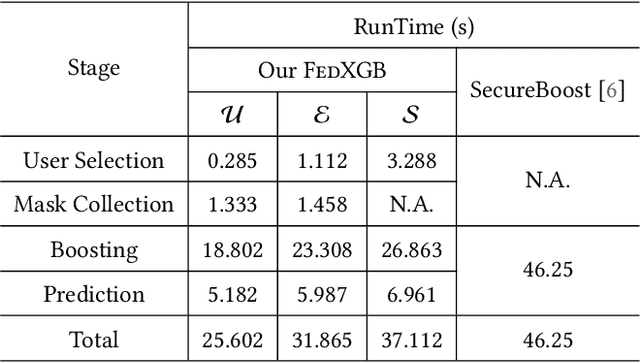
The application of federated extreme gradient boosting to mobile crowdsensing apps brings several benefits, in particular high performance on efficiency and classification. However, it also brings a new challenge for data and model privacy protection. Besides it being vulnerable to Generative Adversarial Network (GAN) based user data reconstruction attack, there is not the existing architecture that considers how to preserve model privacy. In this paper, we propose a secret sharing based federated learning architecture FedXGB to achieve the privacy-preserving extreme gradient boosting for mobile crowdsensing. Specifically, we first build a secure classification and regression tree (CART) of XGBoost using secret sharing. Then, we propose a secure prediction protocol to protect the model privacy of XGBoost in mobile crowdsensing. We conduct a comprehensive theoretical analysis and extensive experiments to evaluate the security, effectiveness, and efficiency of FedXGB. The results indicate that FedXGB is secure against the honest-but-curious adversaries and attains less than 1% accuracy loss compared with the original XGBoost model.