 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentOmni: Rethinking Omni-Modal Understanding via Unified Audio-Visual Latent Reasoning
May 21, 2026Joint audio-visual reasoning is essential for omnimodal understanding, yet current multimodal large language models (MLLMs) still struggle when reasoning requires fine-grained evidence from both modalities. A central limitation is that explicit text-based chain-of-thought (CoT) compresses continuous audio-visual signals into discrete tokens, weakening temporal grounding and shifting intermediate reasoning toward language priors. We argue that a unified latent space is a better medium for such reasoning because it preserves dense sensory information while remaining compatible with autoregressive generation. Based on this insight, we propose \textbf{LatentOmni}, a cross-modal reasoning framework that interleaves textual reasoning with audio-visual latent states. LatentOmni introduces feature-level supervision to align latent reasoning states with task-relevant sensory features and uses Omni-Sync Position Embedding (OSPE) to maintain temporal consistency between latent audio and visual states. We further construct \textbf{LatentOmni-Instruct-35K}, a dataset of audio-visual interleaved reasoning trajectories for supervising latent-space reasoning. Comprehensive evaluation across multiple audio-visual reasoning benchmarks demonstrates that LatentOmni achieves the best performance among the evaluated open-source models and consistently outperforms the Explicit Text CoT baseline, supporting latent-space joint reasoning as a promising path toward stronger omnimodal understanding.
OpenWorldLib: A Unified Codebase and Definition of Advanced World Models
Apr 06, 2026World models have garnered significant attention as a promising research direction in artificial intelligence, yet a clear and unified definition remains lacking. In this paper, we introduce OpenWorldLib, a comprehensive and standardized inference framework for Advanced World Models. Drawing on the evolution of world models, we propose a clear definition: a world model is a model or framework centered on perception, equipped with interaction and long-term memory capabilities, for understanding and predicting the complex world. We further systematically categorize the essential capabilities of world models. Based on this definition, OpenWorldLib integrates models across different tasks within a unified framework, enabling efficient reuse and collaborative inference. Finally, we present additional reflections and analyses on potential future directions for world model research. Code link: https://github.com/OpenDCAI/OpenWorldLib
Scaling Reasoning Tokens via RL and Parallel Thinking: Evidence From Competitive Programming
Apr 01, 2026We study how to scale reasoning token budgets for competitive programming through two complementary approaches: training-time reinforcement learning (RL) and test-time parallel thinking. During RL training, we observe an approximately log-linear relationship between validation accuracy and the average number of generated reasoning tokens over successive checkpoints, and show two ways to shift this training trajectory: verification RL warmup raises the starting point, while randomized clipping produces a steeper trend in the observed regime. As scaling single-generation reasoning during RL quickly becomes expensive under full attention, we introduce a multi-round parallel thinking pipeline that distributes the token budget across threads and rounds of generation, verification, and refinement. We train the model end-to-end on this pipeline to match the training objective to the test-time structure. Starting from Seed-OSS-36B, the full system with 16 threads and 16 rounds per thread matches the underlying RL model's oracle pass@16 at pass@1 using 7.6 million tokens per problem on average, and surpasses GPT-5-high on 456 hard competitive programming problems from AetherCode.
MoRAgent: Parameter Efficient Agent Tuning with Mixture-of-Roles
Dec 25, 2025Despite recent advancements of fine-tuning large language models (LLMs) to facilitate agent tasks, parameter-efficient fine-tuning (PEFT) methodologies for agent remain largely unexplored. In this paper, we introduce three key strategies for PEFT in agent tasks: 1) Inspired by the increasingly dominant Reason+Action paradigm, we first decompose the capabilities necessary for the agent tasks into three distinct roles: reasoner, executor, and summarizer. The reasoner is responsible for comprehending the user's query and determining the next role based on the execution trajectory. The executor is tasked with identifying the appropriate functions and parameters to invoke. The summarizer conveys the distilled information from conversations back to the user. 2) We then propose the Mixture-of-Roles (MoR) framework, which comprises three specialized Low-Rank Adaptation (LoRA) groups, each designated to fulfill a distinct role. By focusing on their respective specialized capabilities and engaging in collaborative interactions, these LoRAs collectively accomplish the agent task. 3) To effectively fine-tune the framework, we develop a multi-role data generation pipeline based on publicly available datasets, incorporating role-specific content completion and reliability verification. We conduct extensive experiments and thorough ablation studies on various LLMs and agent benchmarks, demonstrating the effectiveness of the proposed method. This project is publicly available at https://mor-agent.github.io.
TongSIM: A General Platform for Simulating Intelligent Machines
Dec 23, 2025As artificial intelligence (AI) rapidly advances, especially in multimodal large language models (MLLMs), research focus is shifting from single-modality text processing to the more complex domains of multimodal and embodied AI. Embodied intelligence focuses on training agents within realistic simulated environments, leveraging physical interaction and action feedback rather than conventionally labeled datasets. Yet, most existing simulation platforms remain narrowly designed, each tailored to specific tasks. A versatile, general-purpose training environment that can support everything from low-level embodied navigation to high-level composite activities, such as multi-agent social simulation and human-AI collaboration, remains largely unavailable. To bridge this gap, we introduce TongSIM, a high-fidelity, general-purpose platform for training and evaluating embodied agents. TongSIM offers practical advantages by providing over 100 diverse, multi-room indoor scenarios as well as an open-ended, interaction-rich outdoor town simulation, ensuring broad applicability across research needs. Its comprehensive evaluation framework and benchmarks enable precise assessment of agent capabilities, such as perception, cognition, decision-making, human-robot cooperation, and spatial and social reasoning. With features like customized scenes, task-adaptive fidelity, diverse agent types, and dynamic environmental simulation, TongSIM delivers flexibility and scalability for researchers, serving as a unified platform that accelerates training, evaluation, and advancement toward general embodied intelligence.
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
Dec 18, 2025The rapidly growing demand for high-quality data in Large Language Models (LLMs) has intensified the need for scalable, reliable, and semantically rich data preparation pipelines. However, current practices remain dominated by ad-hoc scripts and loosely specified workflows, which lack principled abstractions, hinder reproducibility, and offer limited support for model-in-the-loop data generation. To address these challenges, we present DataFlow, a unified and extensible LLM-driven data preparation framework. DataFlow is designed with system-level abstractions that enable modular, reusable, and composable data transformations, and provides a PyTorch-style pipeline construction API for building debuggable and optimizable dataflows. The framework consists of nearly 200 reusable operators and six domain-general pipelines spanning text, mathematical reasoning, code, Text-to-SQL, agentic RAG, and large-scale knowledge extraction. To further improve usability, we introduce DataFlow-Agent, which automatically translates natural-language specifications into executable pipelines via operator synthesis, pipeline planning, and iterative verification. Across six representative use cases, DataFlow consistently improves downstream LLM performance. Our math, code, and text pipelines outperform curated human datasets and specialized synthetic baselines, achieving up to +3\% execution accuracy in Text-to-SQL over SynSQL, +7\% average improvements on code benchmarks, and 1--3 point gains on MATH, GSM8K, and AIME. Moreover, a unified 10K-sample dataset produced by DataFlow enables base models to surpass counterparts trained on 1M Infinity-Instruct data. These results demonstrate that DataFlow provides a practical and high-performance substrate for reliable, reproducible, and scalable LLM data preparation, and establishes a system-level foundation for future data-centric AI development.
VersatileFFN: Achieving Parameter Efficiency in LLMs via Adaptive Wide-and-Deep Reuse
Dec 16, 2025The rapid scaling of Large Language Models (LLMs) has achieved remarkable performance, but it also leads to prohibitive memory costs. Existing parameter-efficient approaches such as pruning and quantization mainly compress pretrained models without enhancing architectural capacity, thereby hitting the representational ceiling of the base model. In this work, we propose VersatileFFN, a novel feed-forward network (FFN) that enables flexible reuse of parameters in both width and depth dimensions within a fixed parameter budget. Inspired by the dual-process theory of cognition, VersatileFFN comprises two adaptive pathways: a width-versatile path that generates a mixture of sub-experts from a single shared FFN, mimicking sparse expert routing without increasing parameters, and a depth-versatile path that recursively applies the same FFN to emulate deeper processing for complex tokens. A difficulty-aware gating dynamically balances the two pathways, steering "easy" tokens through the efficient width-wise route and allocating deeper iterative refinement to "hard" tokens. Crucially, both pathways reuse the same parameters, so all additional capacity comes from computation rather than memory. Experiments across diverse benchmarks and model scales demonstrate the effectiveness of the method. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/VersatileFFN.
BRACE: A Benchmark for Robust Audio Caption Quality Evaluation
Dec 11, 2025
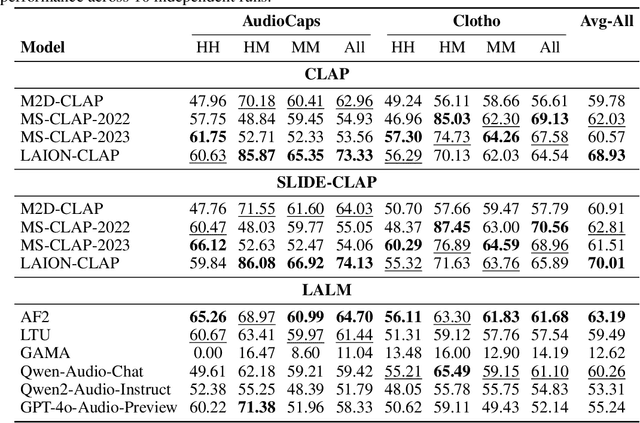
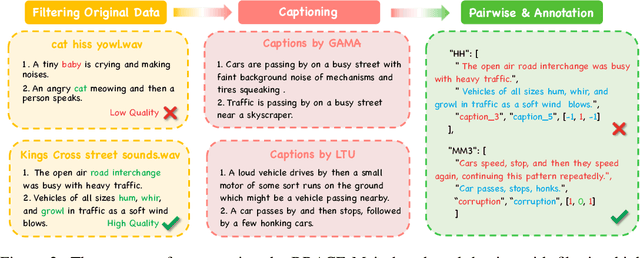
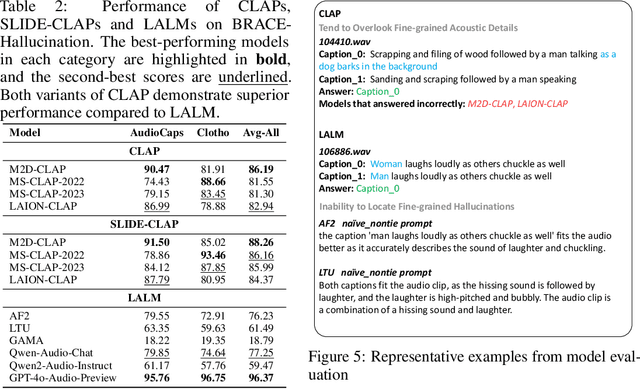
Automatic audio captioning is essential for audio understanding, enabling applications such as accessibility and content indexing. However, evaluating the quality of audio captions remains a major challenge, especially in reference-free settings where high-quality ground-truth captions are unavailable. While CLAPScore is currently the most widely used reference-free Audio Caption Evaluation Metric(ACEM), its robustness under diverse conditions has not been systematically validated. To address this gap, we introduce BRACE, a new benchmark designed to evaluate audio caption alignment quality in a reference-free setting. BRACE is primarily designed for assessing ACEMs, and can also be extended to measure the modality alignment abilities of Large Audio Language Model(LALM). BRACE consists of two sub-benchmarks: BRACE-Main for fine-grained caption comparison and BRACE-Hallucination for detecting subtle hallucinated content. We construct these datasets through high-quality filtering, LLM-based corruption, and human annotation. Given the widespread adoption of CLAPScore as a reference-free ACEM and the increasing application of LALMs in audio-language tasks, we evaluate both approaches using the BRACE benchmark, testing CLAPScore across various CLAP model variants and assessing multiple LALMs. Notably, even the best-performing CLAP-based ACEM achieves only a 70.01 F1-score on the BRACE-Main benchmark, while the best LALM reaches just 63.19. By revealing the limitations of CLAP models and LALMs, our BRACE benchmark offers valuable insights into the direction of future research.
SPEED-Q: Staged Processing with Enhanced Distillation towards Efficient Low-bit On-device VLM Quantization
Nov 12, 2025Deploying Vision-Language Models (VLMs) on edge devices (e.g., smartphones and robots) is crucial for enabling low-latency and privacy-preserving intelligent applications. Given the resource constraints of these devices, quantization offers a promising solution by improving memory efficiency and reducing bandwidth requirements, thereby facilitating the deployment of VLMs. However, existing research has rarely explored aggressive quantization on VLMs, particularly for the models ranging from 1B to 2B parameters, which are more suitable for resource-constrained edge devices. In this paper, we propose SPEED-Q, a novel Staged Processing with Enhanced Distillation framework for VLM low-bit weight-only quantization that systematically addresses the following two critical obstacles: (1) significant discrepancies in quantization sensitivity between vision (ViT) and language (LLM) components in VLMs; (2) training instability arising from the reduced numerical precision inherent in low-bit quantization. In SPEED-Q, a staged sensitivity adaptive mechanism is introduced to effectively harmonize performance across different modalities. We further propose a distillation-enhanced quantization strategy to stabilize the training process and reduce data dependence. Together, SPEED-Q enables accurate, stable, and data-efficient quantization of complex VLMs. SPEED-Q is the first framework tailored for quantizing entire small-scale billion-parameter VLMs to low bits. Extensive experiments across multiple benchmarks demonstrate that SPEED-Q achieves up to 6x higher accuracy than existing quantization methods under 2-bit settings and consistently outperforms prior on-device VLMs under both 2-bit and 4-bit settings. Our code and models are available at https://github.com/antgroup/SPEED-Q.
Rethinking Text-to-SQL: Dynamic Multi-turn SQL Interaction for Real-world Database Exploration
Oct 30, 2025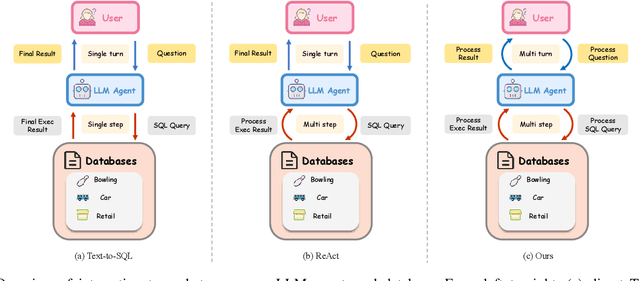



Recent advances in Text-to-SQL have achieved strong results in static, single-turn tasks, where models generate SQL queries from natural language questions. However, these systems fall short in real-world interactive scenarios, where user intents evolve and queries must be refined over multiple turns. In applications such as finance and business analytics, users iteratively adjust query constraints or dimensions based on intermediate results. To evaluate such dynamic capabilities, we introduce DySQL-Bench, a benchmark assessing model performance under evolving user interactions. Unlike previous manually curated datasets, DySQL-Bench is built through an automated two-stage pipeline of task synthesis and verification. Structured tree representations derived from raw database tables guide LLM-based task generation, followed by interaction-oriented filtering and expert validation. Human evaluation confirms 100% correctness of the synthesized data. We further propose a multi-turn evaluation framework simulating realistic interactions among an LLM-simulated user, the model under test, and an executable database. The model must adapt its reasoning and SQL generation as user intents change. DySQL-Bench covers 13 domains across BIRD and Spider 2 databases, totaling 1,072 tasks. Even GPT-4o attains only 58.34% overall accuracy and 23.81% on the Pass@5 metric, underscoring the benchmark's difficulty. All code and data are released at https://github.com/Aurora-slz/Real-World-SQL-Bench .