 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu Pro MoE: Mixture of Grouped Experts for Efficient Sparsity
May 28, 2025The surgence of Mixture of Experts (MoE) in Large Language Models promises a small price of execution cost for a much larger model parameter count and learning capacity, because only a small fraction of parameters are activated for each input token. However, it is commonly observed that some experts are activated far more often than others, leading to system inefficiency when running the experts on different devices in parallel. Therefore, we introduce Mixture of Grouped Experts (MoGE), which groups the experts during selection and balances the expert workload better than MoE in nature. It constrains tokens to activate an equal number of experts within each predefined expert group. When a model execution is distributed on multiple devices, this architectural design ensures a balanced computational load across devices, significantly enhancing throughput, particularly for the inference phase. Further, we build Pangu Pro MoE on Ascend NPUs, a sparse model based on MoGE with 72 billion total parameters, 16 billion of which are activated for each token. The configuration of Pangu Pro MoE is optimized for Ascend 300I Duo and 800I A2 through extensive system simulation studies. Our experiments indicate that MoGE indeed leads to better expert load balancing and more efficient execution for both model training and inference on Ascend NPUs. The inference performance of Pangu Pro MoE achieves 1148 tokens/s per card and can be further improved to 1528 tokens/s per card by speculative acceleration, outperforming comparable 32B and 72B Dense models. Furthermore, we achieve an excellent cost-to-performance ratio for model inference on Ascend 300I Duo. Our studies show that Ascend NPUs are capable of training Pangu Pro MoE with massive parallelization to make it a leading model within the sub-100B total parameter class, outperforming prominent open-source models like GLM-Z1-32B and Qwen3-32B.
CFinBench: A Comprehensive Chinese Financial Benchmark for Large Language Models
Jul 02, 2024



Large language models (LLMs) have achieved remarkable performance on various NLP tasks, yet their potential in more challenging and domain-specific task, such as finance, has not been fully explored. In this paper, we present CFinBench: a meticulously crafted, the most comprehensive evaluation benchmark to date, for assessing the financial knowledge of LLMs under Chinese context. In practice, to better align with the career trajectory of Chinese financial practitioners, we build a systematic evaluation from 4 first-level categories: (1) Financial Subject: whether LLMs can memorize the necessary basic knowledge of financial subjects, such as economics, statistics and auditing. (2) Financial Qualification: whether LLMs can obtain the needed financial qualified certifications, such as certified public accountant, securities qualification and banking qualification. (3) Financial Practice: whether LLMs can fulfill the practical financial jobs, such as tax consultant, junior accountant and securities analyst. (4) Financial Law: whether LLMs can meet the requirement of financial laws and regulations, such as tax law, insurance law and economic law. CFinBench comprises 99,100 questions spanning 43 second-level categories with 3 question types: single-choice, multiple-choice and judgment. We conduct extensive experiments of 50 representative LLMs with various model size on CFinBench. The results show that GPT4 and some Chinese-oriented models lead the benchmark, with the highest average accuracy being 60.16%, highlighting the challenge presented by CFinBench. The dataset and evaluation code are available at https://cfinbench.github.io/.
LocMoE+: Enhanced Router with Token Feature Awareness for Efficient LLM Pre-Training
May 24, 2024Mixture-of-Experts (MoE) architectures have recently gained increasing popularity within the domain of large language models (LLMs) due to their ability to significantly reduce training and inference overhead. However, MoE architectures face challenges, such as significant disparities in the number of tokens assigned to each expert and a tendency toward homogenization among experts, which adversely affects the model's semantic generation capabilities. In this paper, we introduce LocMoE+, a refined version of the low-overhead LocMoE, incorporating the following enhancements: (1) Quantification and definition of the affinity between experts and tokens. (2) Implementation of a global-level adaptive routing strategy to rearrange tokens based on their affinity scores. (3) Reestimation of the lower bound for expert capacity, which has been shown to progressively decrease as the token feature distribution evolves. Experimental results demonstrate that, without compromising model convergence or efficacy, the number of tokens each expert processes can be reduced by over 60%. Combined with communication optimizations, this leads to an average improvement in training efficiency ranging from 5.4% to 46.6%. After fine-tuning, LocMoE+ exhibits a performance improvement of 9.7% to 14.1% across the GDAD, C-Eval, and TeleQnA datasets.
LocMoE: A Low-overhead MoE for Large Language Model Training
Jan 25, 2024

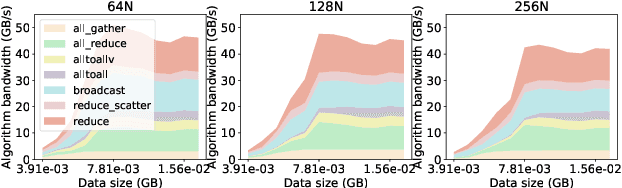
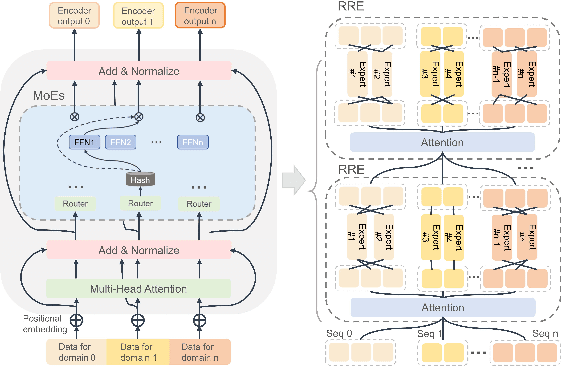
The Mixtures-of-Experts (MoE) model is a widespread distributed and integrated learning method for large language models (LLM), which is favored due to its ability to sparsify and expand models efficiently. However, the performance of MoE is limited by load imbalance and high latency of All-To-All communication, along with relatively redundant computation owing to large expert capacity. Load imbalance may result from existing routing policies that consistently tend to select certain experts. The frequent inter-node communication in the All-To-All procedure also significantly prolongs the training time. To alleviate the above performance problems, we propose a novel routing strategy that combines load balance and locality by converting partial inter-node communication to that of intra-node. Notably, we elucidate that there is a minimum threshold for expert capacity, calculated through the maximal angular deviation between the gating weights of the experts and the assigned tokens. We port these modifications on the PanGu-Sigma model based on the MindSpore framework with multi-level routing and conduct experiments on Ascend clusters. The experiment results demonstrate that the proposed LocMoE reduces training time per epoch by 12.68% to 22.24% compared to classical routers, such as hash router and switch router, without impacting the model accuracy.