 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRich-Media Re-Ranker: A User Satisfaction-Driven LLM Re-ranking Framework for Rich-Media Search
Feb 05, 2026Re-ranking plays a crucial role in modern information search systems by refining the ranking of initial search results to better satisfy user information needs. However, existing methods show two notable limitations in improving user search satisfaction: inadequate modeling of multifaceted user intents and neglect of rich side information such as visual perception signals. To address these challenges, we propose the Rich-Media Re-Ranker framework, which aims to enhance user search satisfaction through multi-dimensional and fine-grained modeling. Our approach begins with a Query Planner that analyzes the sequence of query refinements within a session to capture genuine search intents, decomposing the query into clear and complementary sub-queries to enable broader coverage of users' potential intents. Subsequently, moving beyond primary text content, we integrate richer side information of candidate results, including signals modeling visual content generated by the VLM-based evaluator. These comprehensive signals are then processed alongside carefully designed re-ranking principle that considers multiple facets, including content relevance and quality, information gain, information novelty, and the visual presentation of cover images. Then, the LLM-based re-ranker performs the holistic evaluation based on these principles and integrated signals. To enhance the scenario adaptability of the VLM-based evaluator and the LLM-based re-ranker, we further enhance their capabilities through multi-task reinforcement learning. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art baselines. Notably, the proposed framework has been deployed in a large-scale industrial search system, yielding substantial improvements in online user engagement rates and satisfaction metrics.
MoRAgent: Parameter Efficient Agent Tuning with Mixture-of-Roles
Dec 25, 2025Despite recent advancements of fine-tuning large language models (LLMs) to facilitate agent tasks, parameter-efficient fine-tuning (PEFT) methodologies for agent remain largely unexplored. In this paper, we introduce three key strategies for PEFT in agent tasks: 1) Inspired by the increasingly dominant Reason+Action paradigm, we first decompose the capabilities necessary for the agent tasks into three distinct roles: reasoner, executor, and summarizer. The reasoner is responsible for comprehending the user's query and determining the next role based on the execution trajectory. The executor is tasked with identifying the appropriate functions and parameters to invoke. The summarizer conveys the distilled information from conversations back to the user. 2) We then propose the Mixture-of-Roles (MoR) framework, which comprises three specialized Low-Rank Adaptation (LoRA) groups, each designated to fulfill a distinct role. By focusing on their respective specialized capabilities and engaging in collaborative interactions, these LoRAs collectively accomplish the agent task. 3) To effectively fine-tune the framework, we develop a multi-role data generation pipeline based on publicly available datasets, incorporating role-specific content completion and reliability verification. We conduct extensive experiments and thorough ablation studies on various LLMs and agent benchmarks, demonstrating the effectiveness of the proposed method. This project is publicly available at https://mor-agent.github.io.
VersatileFFN: Achieving Parameter Efficiency in LLMs via Adaptive Wide-and-Deep Reuse
Dec 16, 2025The rapid scaling of Large Language Models (LLMs) has achieved remarkable performance, but it also leads to prohibitive memory costs. Existing parameter-efficient approaches such as pruning and quantization mainly compress pretrained models without enhancing architectural capacity, thereby hitting the representational ceiling of the base model. In this work, we propose VersatileFFN, a novel feed-forward network (FFN) that enables flexible reuse of parameters in both width and depth dimensions within a fixed parameter budget. Inspired by the dual-process theory of cognition, VersatileFFN comprises two adaptive pathways: a width-versatile path that generates a mixture of sub-experts from a single shared FFN, mimicking sparse expert routing without increasing parameters, and a depth-versatile path that recursively applies the same FFN to emulate deeper processing for complex tokens. A difficulty-aware gating dynamically balances the two pathways, steering "easy" tokens through the efficient width-wise route and allocating deeper iterative refinement to "hard" tokens. Crucially, both pathways reuse the same parameters, so all additional capacity comes from computation rather than memory. Experiments across diverse benchmarks and model scales demonstrate the effectiveness of the method. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/VersatileFFN.
Leveraging LLMs to Evaluate Usefulness of Document
Jun 11, 2025The conventional Cranfield paradigm struggles to effectively capture user satisfaction due to its weak correlation between relevance and satisfaction, alongside the high costs of relevance annotation in building test collections. To tackle these issues, our research explores the potential of leveraging large language models (LLMs) to generate multilevel usefulness labels for evaluation. We introduce a new user-centric evaluation framework that integrates users' search context and behavioral data into LLMs. This framework uses a cascading judgment structure designed for multilevel usefulness assessments, drawing inspiration from ordinal regression techniques. Our study demonstrates that when well-guided with context and behavioral information, LLMs can accurately evaluate usefulness, allowing our approach to surpass third-party labeling methods. Furthermore, we conduct ablation studies to investigate the influence of key components within the framework. We also apply the labels produced by our method to predict user satisfaction, with real-world experiments indicating that these labels substantially improve the performance of satisfaction prediction models.
Foundation Models for Geospatial Reasoning: Assessing Capabilities of Large Language Models in Understanding Geometries and Topological Spatial Relations
May 22, 2025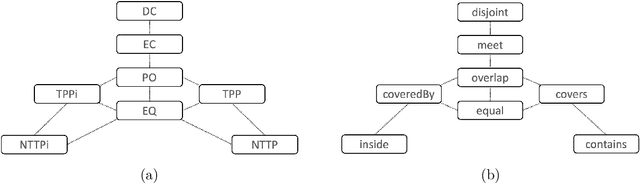
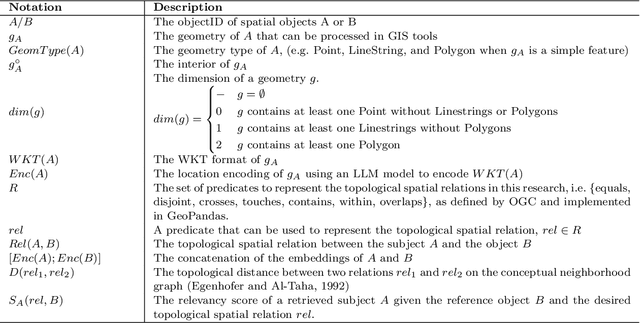
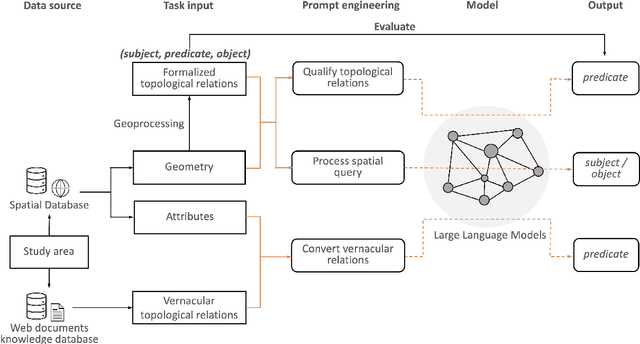
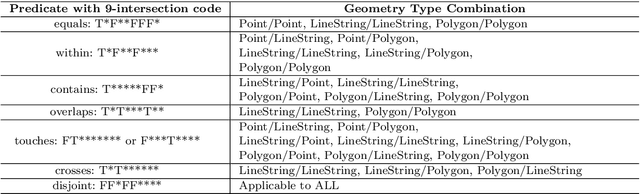
Applying AI foundation models directly to geospatial datasets remains challenging due to their limited ability to represent and reason with geographical entities, specifically vector-based geometries and natural language descriptions of complex spatial relations. To address these issues, we investigate the extent to which a well-known-text (WKT) representation of geometries and their spatial relations (e.g., topological predicates) are preserved during spatial reasoning when the geospatial vector data are passed to large language models (LLMs) including GPT-3.5-turbo, GPT-4, and DeepSeek-R1-14B. Our workflow employs three distinct approaches to complete the spatial reasoning tasks for comparison, i.e., geometry embedding-based, prompt engineering-based, and everyday language-based evaluation. Our experiment results demonstrate that both the embedding-based and prompt engineering-based approaches to geospatial question-answering tasks with GPT models can achieve an accuracy of over 0.6 on average for the identification of topological spatial relations between two geometries. Among the evaluated models, GPT-4 with few-shot prompting achieved the highest performance with over 0.66 accuracy on topological spatial relation inference. Additionally, GPT-based reasoner is capable of properly comprehending inverse topological spatial relations and including an LLM-generated geometry can enhance the effectiveness for geographic entity retrieval. GPT-4 also exhibits the ability to translate certain vernacular descriptions about places into formal topological relations, and adding the geometry-type or place-type context in prompts may improve inference accuracy, but it varies by instance. The performance of these spatial reasoning tasks offers valuable insights for the refinement of LLMs with geographical knowledge towards the development of geo-foundation models capable of geospatial reasoning.
* 33 pages, 13 figures, IJGIS GeoFM Special Issue
Circle-RoPE: Cone-like Decoupled Rotary Positional Embedding for Large Vision-Language Models
May 22, 2025Rotary Position Embedding (RoPE) is a widely adopted technique for encoding relative positional information in large language models (LLMs). However, when extended to large vision-language models (LVLMs), its variants introduce unintended cross-modal positional biases. Specifically, they enforce relative positional dependencies between text token indices and image tokens, causing spurious alignments. This issue arises because image tokens representing the same content but located at different spatial positions are assigned distinct positional biases, leading to inconsistent cross-modal associations. To address this, we propose Per-Token Distance (PTD) - a simple yet effective metric for quantifying the independence of positional encodings across modalities. Informed by this analysis, we introduce Circle-RoPE, a novel encoding scheme that maps image token indices onto a circular trajectory orthogonal to the linear path of text token indices, forming a cone-like structure. This configuration ensures that each text token maintains an equal distance to all image tokens, reducing artificial cross-modal biases while preserving intra-image spatial information. To further enhance performance, we propose a staggered layer strategy that applies different RoPE variants across layers. This design leverages the complementary strengths of each RoPE variant, thereby enhancing the model's overall performance. Our experimental results demonstrate that our method effectively preserves spatial information from images while reducing relative positional bias, offering a more robust and flexible positional encoding framework for LVLMs. The code is available at [https://github.com/lose4578/CircleRoPE](https://github.com/lose4578/CircleRoPE).
FltLM: An Intergrated Long-Context Large Language Model for Effective Context Filtering and Understanding
Oct 09, 2024
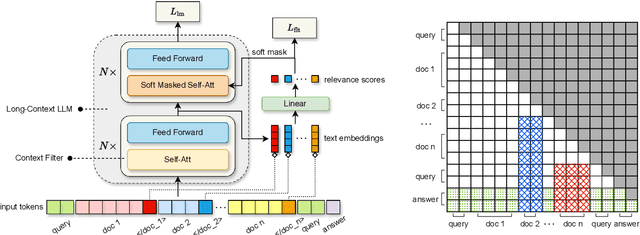

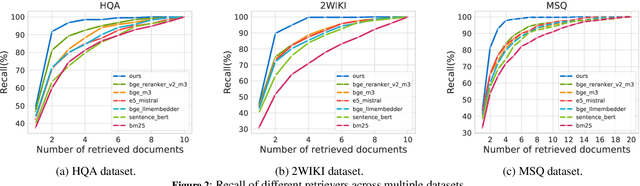
The development of Long-Context Large Language Models (LLMs) has markedly advanced natural language processing by facilitating the process of textual data across long documents and multiple corpora. However, Long-Context LLMs still face two critical challenges: The lost in the middle phenomenon, where crucial middle-context information is likely to be missed, and the distraction issue that the models lose focus due to overly extended contexts. To address these challenges, we propose the Context Filtering Language Model (FltLM), a novel integrated Long-Context LLM which enhances the ability of the model on multi-document question-answering (QA) tasks. Specifically, FltLM innovatively incorporates a context filter with a soft mask mechanism, identifying and dynamically excluding irrelevant content to concentrate on pertinent information for better comprehension and reasoning. Our approach not only mitigates these two challenges, but also enables the model to operate conveniently in a single forward pass. Experimental results demonstrate that FltLM significantly outperforms supervised fine-tuning and retrieval-based methods in complex QA scenarios, suggesting a promising solution for more accurate and reliable long-context natural language understanding applications.
Cross-video Identity Correlating for Person Re-identification Pre-training
Sep 27, 2024



Recent researches have proven that pre-training on large-scale person images extracted from internet videos is an effective way in learning better representations for person re-identification. However, these researches are mostly confined to pre-training at the instance-level or single-video tracklet-level. They ignore the identity-invariance in images of the same person across different videos, which is a key focus in person re-identification. To address this issue, we propose a Cross-video Identity-cOrrelating pre-traiNing (CION) framework. Defining a noise concept that comprehensively considers both intra-identity consistency and inter-identity discrimination, CION seeks the identity correlation from cross-video images by modeling it as a progressive multi-level denoising problem. Furthermore, an identity-guided self-distillation loss is proposed to implement better large-scale pre-training by mining the identity-invariance within person images. We conduct extensive experiments to verify the superiority of our CION in terms of efficiency and performance. CION achieves significantly leading performance with even fewer training samples. For example, compared with the previous state-of-the-art~\cite{ISR}, CION with the same ResNet50-IBN achieves higher mAP of 93.3\% and 74.3\% on Market1501 and MSMT17, while only utilizing 8\% training samples. Finally, with CION demonstrating superior model-agnostic ability, we contribute a model zoo named ReIDZoo to meet diverse research and application needs in this field. It contains a series of CION pre-trained models with spanning structures and parameters, totaling 32 models with 10 different structures, including GhostNet, ConvNext, RepViT, FastViT and so on. The code and models will be made publicly available at https://github.com/Zplusdragon/CION_ReIDZoo.
CFinBench: A Comprehensive Chinese Financial Benchmark for Large Language Models
Jul 02, 2024



Large language models (LLMs) have achieved remarkable performance on various NLP tasks, yet their potential in more challenging and domain-specific task, such as finance, has not been fully explored. In this paper, we present CFinBench: a meticulously crafted, the most comprehensive evaluation benchmark to date, for assessing the financial knowledge of LLMs under Chinese context. In practice, to better align with the career trajectory of Chinese financial practitioners, we build a systematic evaluation from 4 first-level categories: (1) Financial Subject: whether LLMs can memorize the necessary basic knowledge of financial subjects, such as economics, statistics and auditing. (2) Financial Qualification: whether LLMs can obtain the needed financial qualified certifications, such as certified public accountant, securities qualification and banking qualification. (3) Financial Practice: whether LLMs can fulfill the practical financial jobs, such as tax consultant, junior accountant and securities analyst. (4) Financial Law: whether LLMs can meet the requirement of financial laws and regulations, such as tax law, insurance law and economic law. CFinBench comprises 99,100 questions spanning 43 second-level categories with 3 question types: single-choice, multiple-choice and judgment. We conduct extensive experiments of 50 representative LLMs with various model size on CFinBench. The results show that GPT4 and some Chinese-oriented models lead the benchmark, with the highest average accuracy being 60.16%, highlighting the challenge presented by CFinBench. The dataset and evaluation code are available at https://cfinbench.github.io/.
PanGu-$π$: Enhancing Language Model Architectures via Nonlinearity Compensation
Dec 27, 2023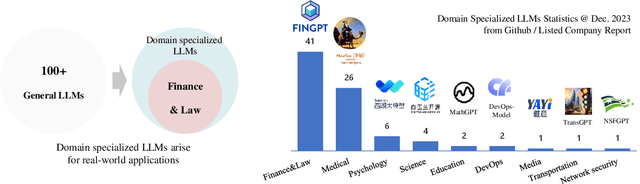

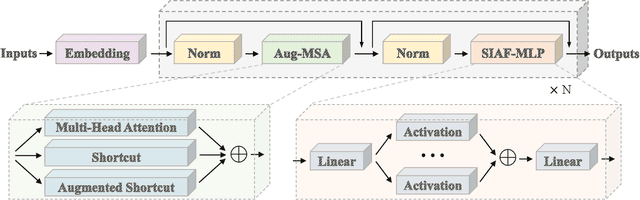

The recent trend of large language models (LLMs) is to increase the scale of both model size (\aka the number of parameters) and dataset to achieve better generative ability, which is definitely proved by a lot of work such as the famous GPT and Llama. However, large models often involve massive computational costs, and practical applications cannot afford such high prices. However, the method of constructing a strong model architecture for LLMs is rarely discussed. We first analyze the state-of-the-art language model architectures and observe the feature collapse problem. Based on the theoretical analysis, we propose that the nonlinearity is also very important for language models, which is usually studied in convolutional neural networks for vision tasks. The series informed activation function is then introduced with tiny calculations that can be ignored, and an augmented shortcut is further used to enhance the model nonlinearity. We then demonstrate that the proposed approach is significantly effective for enhancing the model nonlinearity through carefully designed ablations; thus, we present a new efficient model architecture for establishing modern, namely, PanGu-$\pi$. Experiments are then conducted using the same dataset and training strategy to compare PanGu-$\pi$ with state-of-the-art LLMs. The results show that PanGu-$\pi$-7B can achieve a comparable performance to that of benchmarks with about 10\% inference speed-up, and PanGu-$\pi$-1B can achieve state-of-the-art performance in terms of accuracy and efficiency. In addition, we have deployed PanGu-$\pi$-7B in the high-value domains of finance and law, developing an LLM named YunShan for practical application. The results show that YunShan can surpass other models with similar scales on benchmarks.