 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Vision-Driven Reactive Soccer Skills for Humanoid Robots
Nov 06, 2025Humanoid soccer poses a representative challenge for embodied intelligence, requiring robots to operate within a tightly coupled perception-action loop. However, existing systems typically rely on decoupled modules, resulting in delayed responses and incoherent behaviors in dynamic environments, while real-world perceptual limitations further exacerbate these issues. In this work, we present a unified reinforcement learning-based controller that enables humanoid robots to acquire reactive soccer skills through the direct integration of visual perception and motion control. Our approach extends Adversarial Motion Priors to perceptual settings in real-world dynamic environments, bridging motion imitation and visually grounded dynamic control. We introduce an encoder-decoder architecture combined with a virtual perception system that models real-world visual characteristics, allowing the policy to recover privileged states from imperfect observations and establish active coordination between perception and action. The resulting controller demonstrates strong reactivity, consistently executing coherent and robust soccer behaviors across various scenarios, including real RoboCup matches.
CFinBench: A Comprehensive Chinese Financial Benchmark for Large Language Models
Jul 02, 2024



Large language models (LLMs) have achieved remarkable performance on various NLP tasks, yet their potential in more challenging and domain-specific task, such as finance, has not been fully explored. In this paper, we present CFinBench: a meticulously crafted, the most comprehensive evaluation benchmark to date, for assessing the financial knowledge of LLMs under Chinese context. In practice, to better align with the career trajectory of Chinese financial practitioners, we build a systematic evaluation from 4 first-level categories: (1) Financial Subject: whether LLMs can memorize the necessary basic knowledge of financial subjects, such as economics, statistics and auditing. (2) Financial Qualification: whether LLMs can obtain the needed financial qualified certifications, such as certified public accountant, securities qualification and banking qualification. (3) Financial Practice: whether LLMs can fulfill the practical financial jobs, such as tax consultant, junior accountant and securities analyst. (4) Financial Law: whether LLMs can meet the requirement of financial laws and regulations, such as tax law, insurance law and economic law. CFinBench comprises 99,100 questions spanning 43 second-level categories with 3 question types: single-choice, multiple-choice and judgment. We conduct extensive experiments of 50 representative LLMs with various model size on CFinBench. The results show that GPT4 and some Chinese-oriented models lead the benchmark, with the highest average accuracy being 60.16%, highlighting the challenge presented by CFinBench. The dataset and evaluation code are available at https://cfinbench.github.io/.
GAD-Generative Learning for HD Map-Free Autonomous Driving
May 01, 2024



Deep-learning-based techniques have been widely adopted for autonomous driving software stacks for mass production in recent years, focusing primarily on perception modules, with some work extending this method to prediction modules. However, the downstream planning and control modules are still designed with hefty handcrafted rules, dominated by optimization-based methods such as quadratic programming or model predictive control. This results in a performance bottleneck for autonomous driving systems in that corner cases simply cannot be solved by enumerating hand-crafted rules. We present a deep-learning-based approach that brings prediction, decision, and planning modules together with the attempt to overcome the rule-based methods' deficiency in real-world applications of autonomous driving, especially for urban scenes. The DNN model we proposed is solely trained with 10 hours of human driver data, and it supports all mass-production ADAS features available on the market to date. This method is deployed onto a Jiyue test car with no modification to its factory-ready sensor set and compute platform. the feasibility, usability, and commercial potential are demonstrated in this article.
Enhancing Document-level Relation Extraction by Entity Knowledge Injection
Jul 23, 2022
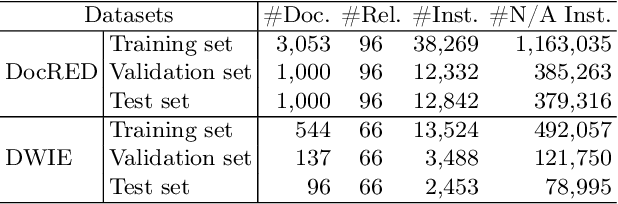
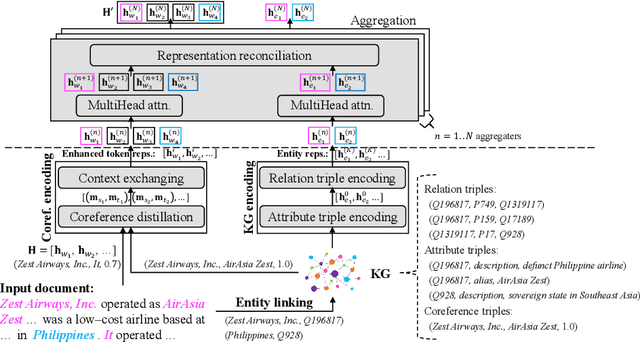
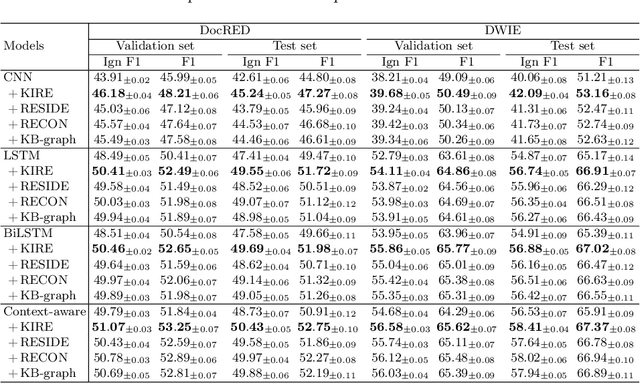
Document-level relation extraction (RE) aims to identify the relations between entities throughout an entire document. It needs complex reasoning skills to synthesize various knowledge such as coreferences and commonsense. Large-scale knowledge graphs (KGs) contain a wealth of real-world facts, and can provide valuable knowledge to document-level RE. In this paper, we propose an entity knowledge injection framework to enhance current document-level RE models. Specifically, we introduce coreference distillation to inject coreference knowledge, endowing an RE model with the more general capability of coreference reasoning. We also employ representation reconciliation to inject factual knowledge and aggregate KG representations and document representations into a unified space. The experiments on two benchmark datasets validate the generalization of our entity knowledge injection framework and the consistent improvement to several document-level RE models.
Global-to-Local Neural Networks for Document-Level Relation Extraction
Sep 22, 2020


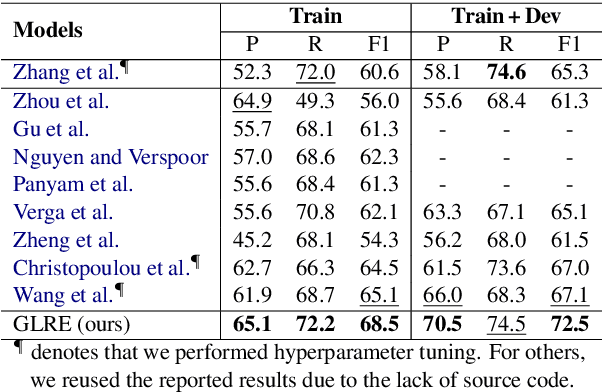
Relation extraction (RE) aims to identify the semantic relations between named entities in text. Recent years have witnessed it raised to the document level, which requires complex reasoning with entities and mentions throughout an entire document. In this paper, we propose a novel model to document-level RE, by encoding the document information in terms of entity global and local representations as well as context relation representations. Entity global representations model the semantic information of all entities in the document, entity local representations aggregate the contextual information of multiple mentions of specific entities, and context relation representations encode the topic information of other relations. Experimental results demonstrate that our model achieves superior performance on two public datasets for document-level RE. It is particularly effective in extracting relations between entities of long distance and having multiple mentions.
Task-oriented Dialogue System for Automatic Disease Diagnosis via Hierarchical Reinforcement Learning
Apr 29, 2020
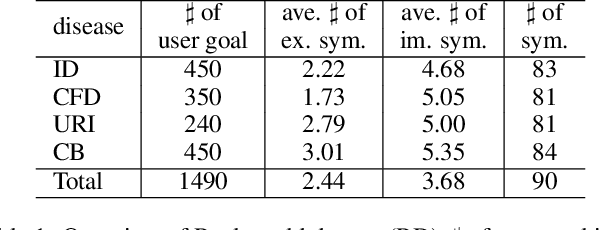

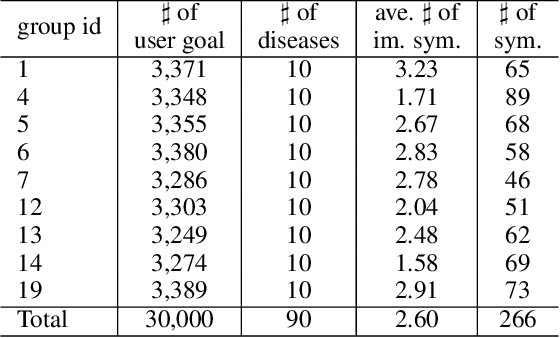
In this paper, we focus on automatic disease diagnosis with reinforcement learning (RL) methods in task-oriented dialogues setting. Different from conventional RL tasks, the action space for disease diagnosis (i.e., symptoms) is inevitably large, especially when the number of diseases increases. However, existing approaches to this problem employ a flat RL policy, which typically works well in simple tasks but has significant challenges in complex scenarios like disease diagnosis. Towards this end, we propose to integrate a hierarchical policy of two levels into the dialogue policy learning. The high level policy consists of a model named master that is responsible for triggering a model in low level, the low level policy consists of several symptom checkers and a disease classifier. Experimental results on both self-constructed real-world and synthetic datasets demonstrate that our hierarchical framework achieves higher accuracy in disease diagnosis compared with existing systems. Besides, the datasets (http://www.sdspeople.fudan.edu.cn/zywei/data/Fudan-Medical-Dialogue2.0) and codes (https://github.com/nnbay/MeicalChatbot-HRL) are all available now.