 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAD-Generative Learning for HD Map-Free Autonomous Driving
May 01, 2024



Deep-learning-based techniques have been widely adopted for autonomous driving software stacks for mass production in recent years, focusing primarily on perception modules, with some work extending this method to prediction modules. However, the downstream planning and control modules are still designed with hefty handcrafted rules, dominated by optimization-based methods such as quadratic programming or model predictive control. This results in a performance bottleneck for autonomous driving systems in that corner cases simply cannot be solved by enumerating hand-crafted rules. We present a deep-learning-based approach that brings prediction, decision, and planning modules together with the attempt to overcome the rule-based methods' deficiency in real-world applications of autonomous driving, especially for urban scenes. The DNN model we proposed is solely trained with 10 hours of human driver data, and it supports all mass-production ADAS features available on the market to date. This method is deployed onto a Jiyue test car with no modification to its factory-ready sensor set and compute platform. the feasibility, usability, and commercial potential are demonstrated in this article.
Attention Diversification for Domain Generalization
Oct 09, 2022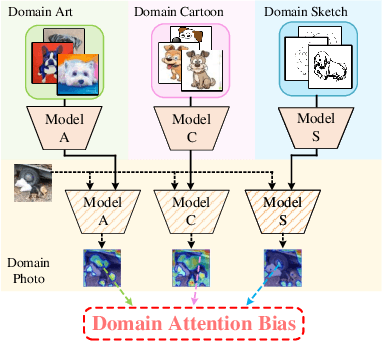
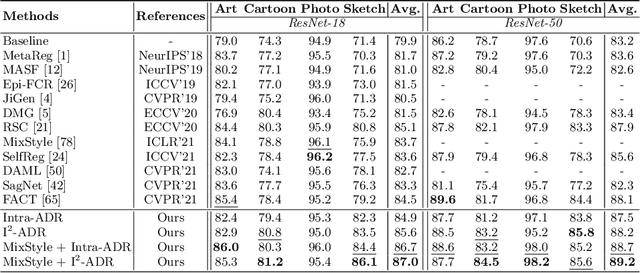
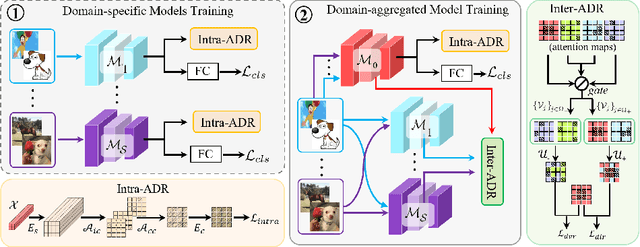
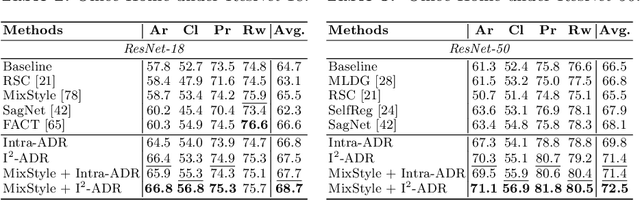
Convolutional neural networks (CNNs) have demonstrated gratifying results at learning discriminative features. However, when applied to unseen domains, state-of-the-art models are usually prone to errors due to domain shift. After investigating this issue from the perspective of shortcut learning, we find the devils lie in the fact that models trained on different domains merely bias to different domain-specific features yet overlook diverse task-related features. Under this guidance, a novel Attention Diversification framework is proposed, in which Intra-Model and Inter-Model Attention Diversification Regularization are collaborated to reassign appropriate attention to diverse task-related features. Briefly, Intra-Model Attention Diversification Regularization is equipped on the high-level feature maps to achieve in-channel discrimination and cross-channel diversification via forcing different channels to pay their most salient attention to different spatial locations. Besides, Inter-Model Attention Diversification Regularization is proposed to further provide task-related attention diversification and domain-related attention suppression, which is a paradigm of "simulate, divide and assemble": simulate domain shift via exploiting multiple domain-specific models, divide attention maps into task-related and domain-related groups, and assemble them within each group respectively to execute regularization. Extensive experiments and analyses are conducted on various benchmarks to demonstrate that our method achieves state-of-the-art performance over other competing methods. Code is available at https://github.com/hikvision-research/DomainGeneralization.
* ECCV 2022. Code available at https://github.com/hikvision-research/DomainGeneralization
A Free Lunch for Unsupervised Domain Adaptive Object Detection without Source Data
Dec 10, 2020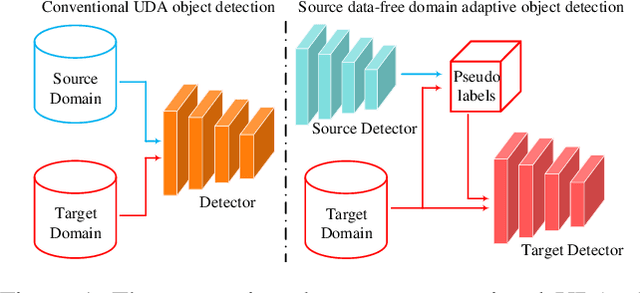
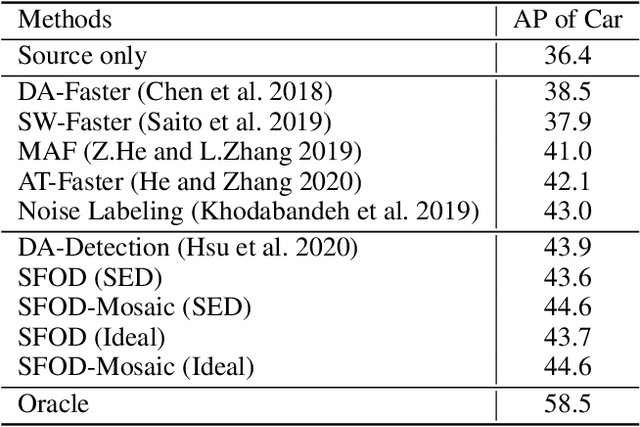

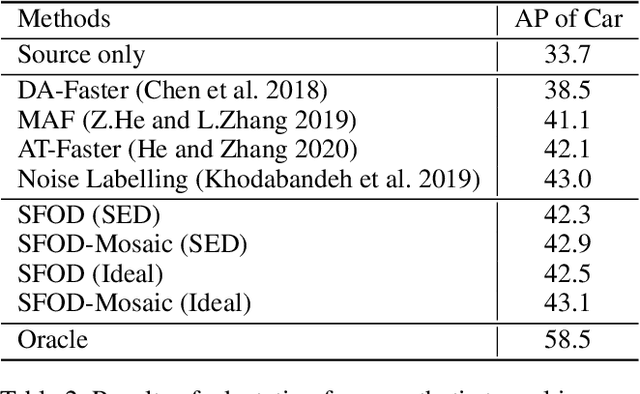
Unsupervised domain adaptation (UDA) assumes that source and target domain data are freely available and usually trained together to reduce the domain gap. However, considering the data privacy and the inefficiency of data transmission, it is impractical in real scenarios. Hence, it draws our eyes to optimize the network in the target domain without accessing labeled source data. To explore this direction in object detection, for the first time, we propose a source data-free domain adaptive object detection (SFOD) framework via modeling it into a problem of learning with noisy labels. Generally, a straightforward method is to leverage the pre-trained network from the source domain to generate the pseudo labels for target domain optimization. However, it is difficult to evaluate the quality of pseudo labels since no labels are available in target domain. In this paper, self-entropy descent (SED) is a metric proposed to search an appropriate confidence threshold for reliable pseudo label generation without using any handcrafted labels. Nonetheless, completely clean labels are still unattainable. After a thorough experimental analysis, false negatives are found to dominate in the generated noisy labels. Undoubtedly, false negatives mining is helpful for performance improvement, and we ease it to false negatives simulation through data augmentation like Mosaic. Extensive experiments conducted in four representative adaptation tasks have demonstrated that the proposed framework can easily achieve state-of-the-art performance. From another view, it also reminds the UDA community that the labeled source data are not fully exploited in the existing methods.