 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoTorrent: Towards Swift, Sustained, and Streaming Multi-Modal Video Generation
Feb 14, 2026Recent multi-modal video generation models have achieved high visual quality, but their prohibitive latency and limited temporal stability hinder real-time deployment. Streaming inference exacerbates these issues, leading to pronounced multimodal degradation, such as spatial blurring, temporal drift, and lip desynchronization, which creates an unresolved efficiency-performance trade-off. To this end, we propose EchoTorrent, a novel schema with a fourfold design: (1) Multi-Teacher Training fine-tunes a pre-trained model on distinct preference domains to obtain specialized domain experts, which sequentially transfer domain-specific knowledge to a student model; (2) Adaptive CFG Calibration (ACC-DMD), which calibrates the audio CFG augmentation errors in DMD via a phased spatiotemporal schedule, eliminating redundant CFG computations and enabling single-pass inference per step; (3) Hybrid Long Tail Forcing, which enforces alignment exclusively on tail frames during long-horizon self-rollout training via a causal-bidirectional hybrid architecture, effectively mitigates spatiotemporal degradation in streaming mode while enhancing fidelity to reference frames; and (4) VAE Decoder Refiner through pixel-domain optimization of the VAE decoder to recover high-frequency details while circumventing latent-space ambiguities. Extensive experiments and analysis demonstrate that EchoTorrent achieves few-pass autoregressive generation with substantially extended temporal consistency, identity preservation, and audio-lip synchronization.
EchoMimicV2: Towards Striking, Simplified, and Semi-Body Human Animation
Nov 15, 2024
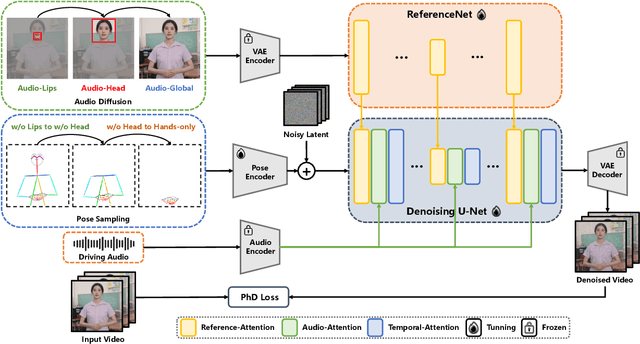
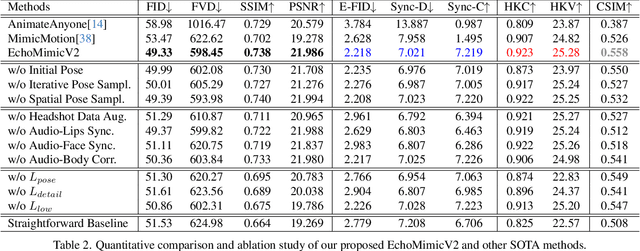

Recent work on human animation usually involves audio, pose, or movement maps conditions, thereby achieves vivid animation quality. However, these methods often face practical challenges due to extra control conditions, cumbersome condition injection modules, or limitation to head region driving. Hence, we ask if it is possible to achieve striking half-body human animation while simplifying unnecessary conditions. To this end, we propose a half-body human animation method, dubbed EchoMimicV2, that leverages a novel Audio-Pose Dynamic Harmonization strategy, including Pose Sampling and Audio Diffusion, to enhance half-body details, facial and gestural expressiveness, and meanwhile reduce conditions redundancy. To compensate for the scarcity of half-body data, we utilize Head Partial Attention to seamlessly accommodate headshot data into our training framework, which can be omitted during inference, providing a free lunch for animation. Furthermore, we design the Phase-specific Denoising Loss to guide motion, detail, and low-level quality for animation in specific phases, respectively. Besides, we also present a novel benchmark for evaluating the effectiveness of half-body human animation. Extensive experiments and analyses demonstrate that EchoMimicV2 surpasses existing methods in both quantitative and qualitative evaluations.
Attention Diversification for Domain Generalization
Oct 09, 2022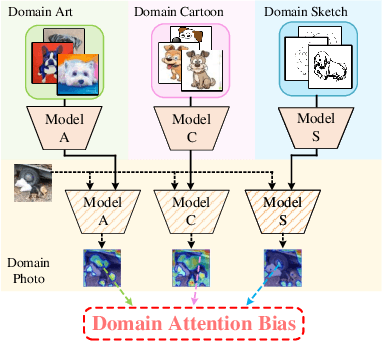
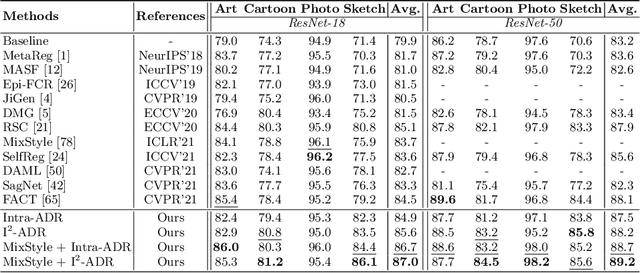
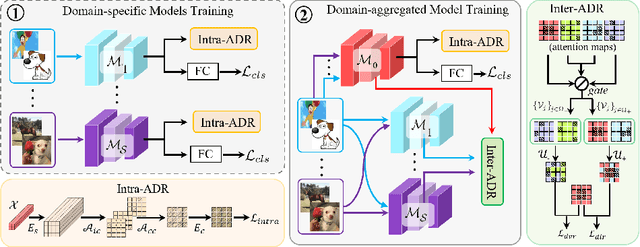
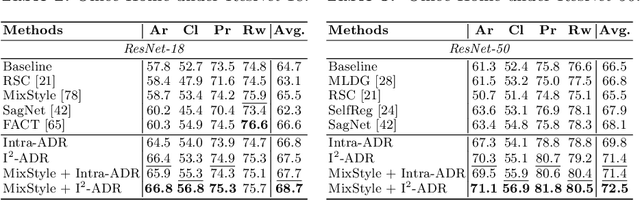
Convolutional neural networks (CNNs) have demonstrated gratifying results at learning discriminative features. However, when applied to unseen domains, state-of-the-art models are usually prone to errors due to domain shift. After investigating this issue from the perspective of shortcut learning, we find the devils lie in the fact that models trained on different domains merely bias to different domain-specific features yet overlook diverse task-related features. Under this guidance, a novel Attention Diversification framework is proposed, in which Intra-Model and Inter-Model Attention Diversification Regularization are collaborated to reassign appropriate attention to diverse task-related features. Briefly, Intra-Model Attention Diversification Regularization is equipped on the high-level feature maps to achieve in-channel discrimination and cross-channel diversification via forcing different channels to pay their most salient attention to different spatial locations. Besides, Inter-Model Attention Diversification Regularization is proposed to further provide task-related attention diversification and domain-related attention suppression, which is a paradigm of "simulate, divide and assemble": simulate domain shift via exploiting multiple domain-specific models, divide attention maps into task-related and domain-related groups, and assemble them within each group respectively to execute regularization. Extensive experiments and analyses are conducted on various benchmarks to demonstrate that our method achieves state-of-the-art performance over other competing methods. Code is available at https://github.com/hikvision-research/DomainGeneralization.
* ECCV 2022. Code available at https://github.com/hikvision-research/DomainGeneralization
Slimmable Domain Adaptation
Jun 14, 2022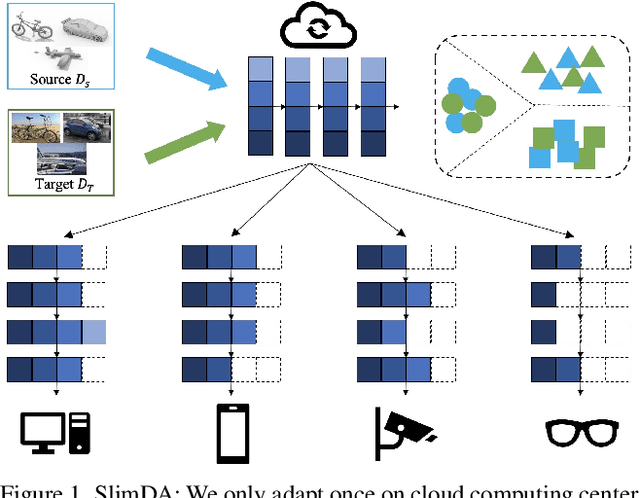

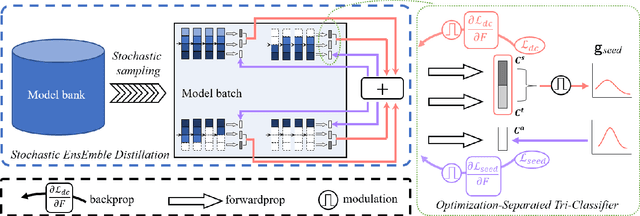
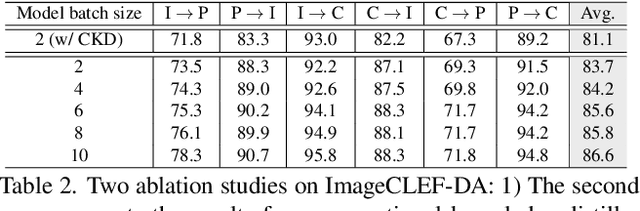
Vanilla unsupervised domain adaptation methods tend to optimize the model with fixed neural architecture, which is not very practical in real-world scenarios since the target data is usually processed by different resource-limited devices. It is therefore of great necessity to facilitate architecture adaptation across various devices. In this paper, we introduce a simple framework, Slimmable Domain Adaptation, to improve cross-domain generalization with a weight-sharing model bank, from which models of different capacities can be sampled to accommodate different accuracy-efficiency trade-offs. The main challenge in this framework lies in simultaneously boosting the adaptation performance of numerous models in the model bank. To tackle this problem, we develop a Stochastic EnsEmble Distillation method to fully exploit the complementary knowledge in the model bank for inter-model interaction. Nevertheless, considering the optimization conflict between inter-model interaction and intra-model adaptation, we augment the existing bi-classifier domain confusion architecture into an Optimization-Separated Tri-Classifier counterpart. After optimizing the model bank, architecture adaptation is leveraged via our proposed Unsupervised Performance Evaluation Metric. Under various resource constraints, our framework surpasses other competing approaches by a very large margin on multiple benchmarks. It is also worth emphasizing that our framework can preserve the performance improvement against the source-only model even when the computing complexity is reduced to $1/64$. Code will be available at https://github.com/hikvision-research/SlimDA.
* To appear in CVPR 2022. Code is coming soon: https://github.com/hikvision-research/SlimDA
Neural Inheritance Relation Guided One-Shot Layer Assignment Search
Feb 28, 2020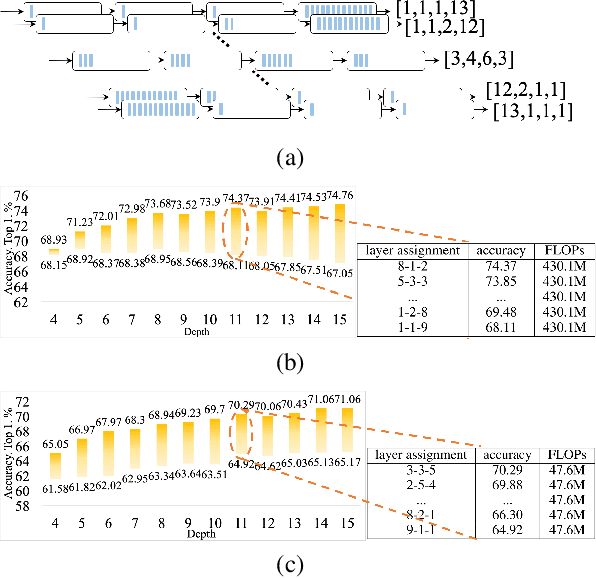
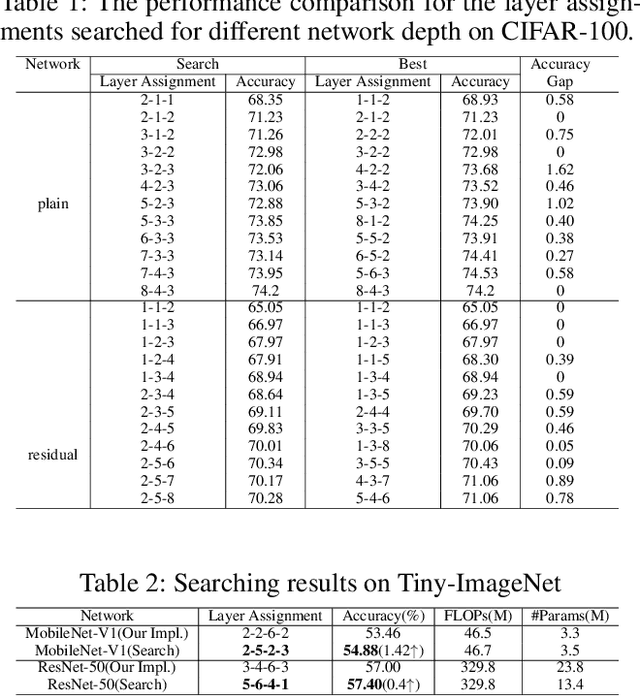
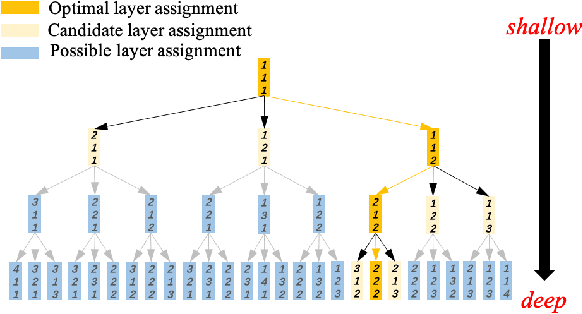
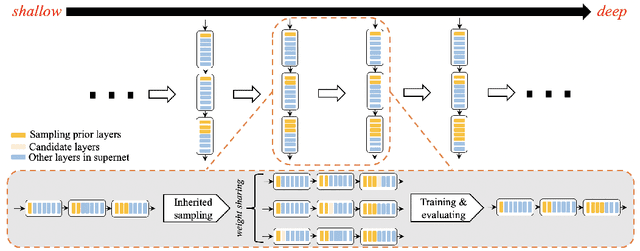
Layer assignment is seldom picked out as an independent research topic in neural architecture search. In this paper, for the first time, we systematically investigate the impact of different layer assignments to the network performance by building an architecture dataset of layer assignment on CIFAR-100. Through analyzing this dataset, we discover a neural inheritance relation among the networks with different layer assignments, that is, the optimal layer assignments for deeper networks always inherit from those for shallow networks. Inspired by this neural inheritance relation, we propose an efficient one-shot layer assignment search approach via inherited sampling. Specifically, the optimal layer assignment searched in the shallow network can be provided as a strong sampling priori to train and search the deeper ones in supernet, which extremely reduces the network search space. Comprehensive experiments carried out on CIFAR-100 illustrate the efficiency of our proposed method. Our search results are strongly consistent with the optimal ones directly selected from the architecture dataset. To further confirm the generalization of our proposed method, we also conduct experiments on Tiny-ImageNet and ImageNet. Our searched results are remarkably superior to the handcrafted ones under the unchanged computational budgets. The neural inheritance relation discovered in this paper can provide insights to the universal neural architecture search.
PIRM Challenge on Perceptual Image Enhancement on Smartphones: Report
Oct 03, 2018
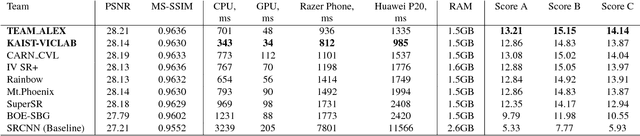

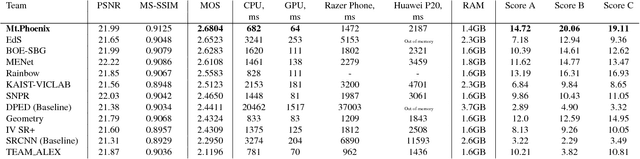
This paper reviews the first challenge on efficient perceptual image enhancement with the focus on deploying deep learning models on smartphones. The challenge consisted of two tracks. In the first one, participants were solving the classical image super-resolution problem with a bicubic downscaling factor of 4. The second track was aimed at real-world photo enhancement, and the goal was to map low-quality photos from the iPhone 3GS device to the same photos captured with a DSLR camera. The target metric used in this challenge combined the runtime, PSNR scores and solutions' perceptual results measured in the user study. To ensure the efficiency of the submitted models, we additionally measured their runtime and memory requirements on Android smartphones. The proposed solutions significantly improved baseline results defining the state-of-the-art for image enhancement on smartphones.