 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-to-Local Neural Networks for Document-Level Relation Extraction
Sep 22, 2020


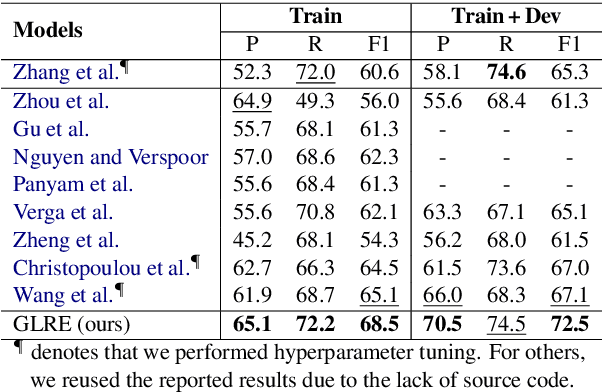
Relation extraction (RE) aims to identify the semantic relations between named entities in text. Recent years have witnessed it raised to the document level, which requires complex reasoning with entities and mentions throughout an entire document. In this paper, we propose a novel model to document-level RE, by encoding the document information in terms of entity global and local representations as well as context relation representations. Entity global representations model the semantic information of all entities in the document, entity local representations aggregate the contextual information of multiple mentions of specific entities, and context relation representations encode the topic information of other relations. Experimental results demonstrate that our model achieves superior performance on two public datasets for document-level RE. It is particularly effective in extracting relations between entities of long distance and having multiple mentions.
Open Knowledge Enrichment for Long-tail Entities
Feb 19, 2020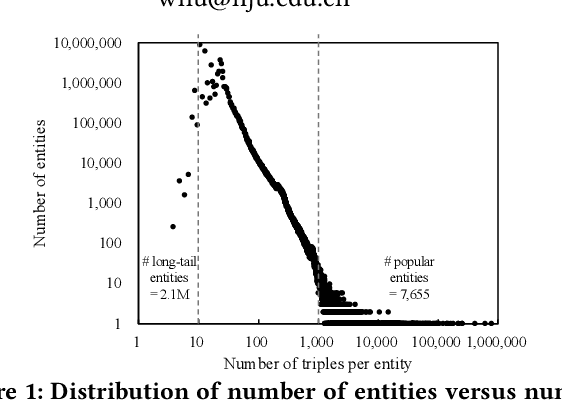



Knowledge bases (KBs) have gradually become a valuable asset for many AI applications. While many current KBs are quite large, they are widely acknowledged as incomplete, especially lacking facts of long-tail entities, e.g., less famous persons. Existing approaches enrich KBs mainly on completing missing links or filling missing values. However, they only tackle a part of the enrichment problem and lack specific considerations regarding long-tail entities. In this paper, we propose a full-fledged approach to knowledge enrichment, which predicts missing properties and infers true facts of long-tail entities from the open Web. Prior knowledge from popular entities is leveraged to improve every enrichment step. Our experiments on the synthetic and real-world datasets and comparison with related work demonstrate the feasibility and superiority of the approach.