 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Knowledge Enrichment for Long-tail Entities
Paper and Code
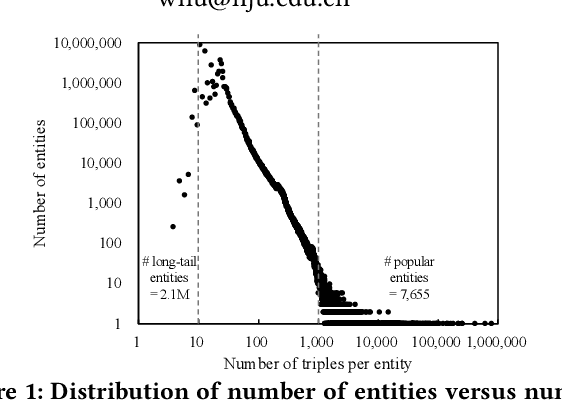



Knowledge bases (KBs) have gradually become a valuable asset for many AI applications. While many current KBs are quite large, they are widely acknowledged as incomplete, especially lacking facts of long-tail entities, e.g., less famous persons. Existing approaches enrich KBs mainly on completing missing links or filling missing values. However, they only tackle a part of the enrichment problem and lack specific considerations regarding long-tail entities. In this paper, we propose a full-fledged approach to knowledge enrichment, which predicts missing properties and infers true facts of long-tail entities from the open Web. Prior knowledge from popular entities is leveraged to improve every enrichment step. Our experiments on the synthetic and real-world datasets and comparison with related work demonstrate the feasibility and superiority of the approach.