 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecies196: A One-Million Semi-supervised Dataset for Fine-grained Species Recognition
Paper and Code
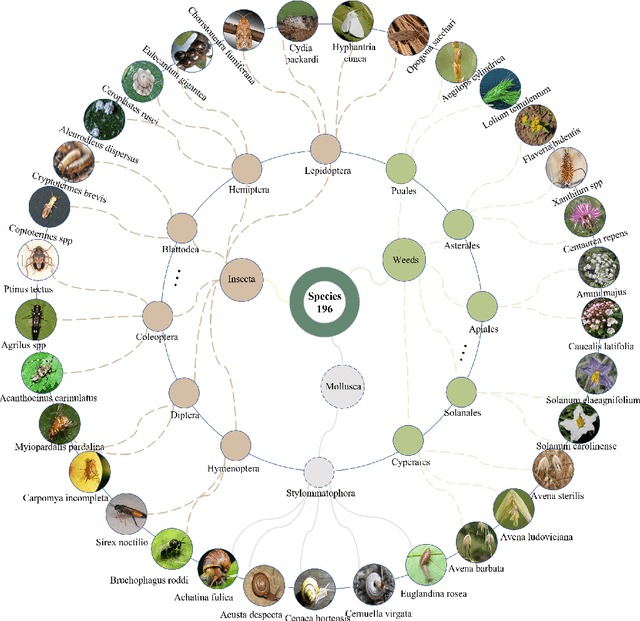
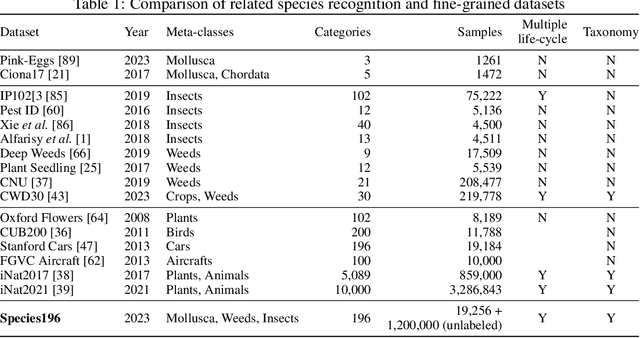
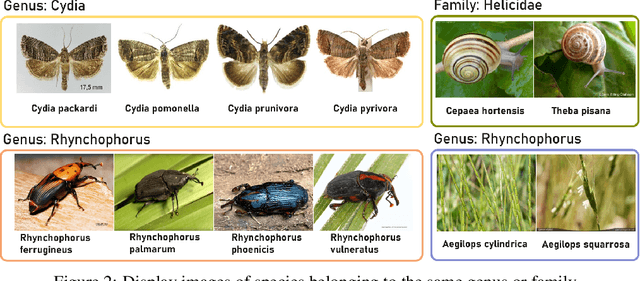

The development of foundation vision models has pushed the general visual recognition to a high level, but cannot well address the fine-grained recognition in specialized domain such as invasive species classification. Identifying and managing invasive species has strong social and ecological value. Currently, most invasive species datasets are limited in scale and cover a narrow range of species, which restricts the development of deep-learning based invasion biometrics systems. To fill the gap of this area, we introduced Species196, a large-scale semi-supervised dataset of 196-category invasive species. It collects over 19K images with expert-level accurate annotations Species196-L, and 1.2M unlabeled images of invasive species Species196-U. The dataset provides four experimental settings for benchmarking the existing models and algorithms, namely, supervised learning, semi-supervised learning, self-supervised pretraining and zero-shot inference ability of large multi-modal models. To facilitate future research on these four learning paradigms, we conduct an empirical study of the representative methods on the introduced dataset. The dataset is publicly available at https://species-dataset.github.io/.