 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressMind: A Multimodal Pretrained Large Language Model for Expressway Operation
Mar 17, 2026The current expressway operation relies on rule-based and isolated models, which limits the ability to jointly analyze knowledge across different systems. Meanwhile, Large Language Models (LLMs) are increasingly applied in intelligent transportation, advancing traffic models from algorithmic to cognitive intelligence. However, general LLMs are unable to effectively understand the regulations and causal relationships of events in unconventional scenarios in the expressway field. Therefore, this paper constructs a pre-trained multimodal large language model (MLLM) for expressways, ExpressMind, which serves as the cognitive core for intelligent expressway operations. This paper constructs the industry's first full-stack expressway dataset, encompassing traffic knowledge texts, emergency reasoning chains, and annotated video events to overcome data scarcity. This paper proposes a dual-layer LLM pre-training paradigm based on self-supervised training and unsupervised learning. Additionally, this study introduces a Graph-Augmented RAG framework to dynamically index the expressway knowledge base. To enhance reasoning for expressway incident response strategies, we develop a RL-aligned Chain-of-Thought (RL-CoT) mechanism that enforces consistency between model reasoning and expert problem-solving heuristics for incident handling. Finally, ExpressMind integrates a cross-modal encoder to align the dynamic feature sequences under the visual and textual channels, enabling it to understand traffic scenes in both video and image modalities. Extensive experiments on our newly released multi-modal expressway benchmark demonstrate that ExpressMind comprehensively outperforms existing baselines in event detection, safety response generation, and complex traffic analysis. The code and data are available at: https://wanderhee.github.io/ExpressMind/.
Circle-RoPE: Cone-like Decoupled Rotary Positional Embedding for Large Vision-Language Models
May 22, 2025Rotary Position Embedding (RoPE) is a widely adopted technique for encoding relative positional information in large language models (LLMs). However, when extended to large vision-language models (LVLMs), its variants introduce unintended cross-modal positional biases. Specifically, they enforce relative positional dependencies between text token indices and image tokens, causing spurious alignments. This issue arises because image tokens representing the same content but located at different spatial positions are assigned distinct positional biases, leading to inconsistent cross-modal associations. To address this, we propose Per-Token Distance (PTD) - a simple yet effective metric for quantifying the independence of positional encodings across modalities. Informed by this analysis, we introduce Circle-RoPE, a novel encoding scheme that maps image token indices onto a circular trajectory orthogonal to the linear path of text token indices, forming a cone-like structure. This configuration ensures that each text token maintains an equal distance to all image tokens, reducing artificial cross-modal biases while preserving intra-image spatial information. To further enhance performance, we propose a staggered layer strategy that applies different RoPE variants across layers. This design leverages the complementary strengths of each RoPE variant, thereby enhancing the model's overall performance. Our experimental results demonstrate that our method effectively preserves spatial information from images while reducing relative positional bias, offering a more robust and flexible positional encoding framework for LVLMs. The code is available at [https://github.com/lose4578/CircleRoPE](https://github.com/lose4578/CircleRoPE).
DiC: Rethinking Conv3x3 Designs in Diffusion Models
Dec 31, 2024



Diffusion models have shown exceptional performance in visual generation tasks. Recently, these models have shifted from traditional U-Shaped CNN-Attention hybrid structures to fully transformer-based isotropic architectures. While these transformers exhibit strong scalability and performance, their reliance on complicated self-attention operation results in slow inference speeds. Contrary to these works, we rethink one of the simplest yet fastest module in deep learning, 3x3 Convolution, to construct a scaled-up purely convolutional diffusion model. We first discover that an Encoder-Decoder Hourglass design outperforms scalable isotropic architectures for Conv3x3, but still under-performing our expectation. Further improving the architecture, we introduce sparse skip connections to reduce redundancy and improve scalability. Based on the architecture, we introduce conditioning improvements including stage-specific embeddings, mid-block condition injection, and conditional gating. These improvements lead to our proposed Diffusion CNN (DiC), which serves as a swift yet competitive diffusion architecture baseline. Experiments on various scales and settings show that DiC surpasses existing diffusion transformers by considerable margins in terms of performance while keeping a good speed advantage. Project page: https://github.com/YuchuanTian/DiC
DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models
Mar 05, 2024



Large language models (LLMs) face a daunting challenge due to the excessive computational and memory requirements of the commonly used Transformer architecture. While state space model (SSM) is a new type of foundational network architecture offering lower computational complexity, their performance has yet to fully rival that of Transformers. This paper introduces DenseSSM, a novel approach to enhance the flow of hidden information between layers in SSMs. By selectively integrating shallowlayer hidden states into deeper layers, DenseSSM retains fine-grained information crucial for the final output. Dense connections enhanced DenseSSM still maintains the training parallelizability and inference efficiency. The proposed method can be widely applicable to various SSM types like RetNet and Mamba. With similar model size, DenseSSM achieves significant improvements, exemplified by DenseRetNet outperforming the original RetNet with up to 5% accuracy improvement on public benchmarks. code is avalaible at https://github.com/WailordHe/DenseSSM
A robust audio deepfake detection system via multi-view feature
Mar 04, 2024


With the advancement of generative modeling techniques, synthetic human speech becomes increasingly indistinguishable from real, and tricky challenges are elicited for the audio deepfake detection (ADD) system. In this paper, we exploit audio features to improve the generalizability of ADD systems. Investigation of the ADD task performance is conducted over a broad range of audio features, including various handcrafted features and learning-based features. Experiments show that learning-based audio features pretrained on a large amount of data generalize better than hand-crafted features on out-of-domain scenarios. Subsequently, we further improve the generalizability of the ADD system using proposed multi-feature approaches to incorporate complimentary information from features of different views. The model trained on ASV2019 data achieves an equal error rate of 24.27\% on the In-the-Wild dataset.
SAM-DiffSR: Structure-Modulated Diffusion Model for Image Super-Resolution
Feb 27, 2024Diffusion-based super-resolution (SR) models have recently garnered significant attention due to their potent restoration capabilities. But conventional diffusion models perform noise sampling from a single distribution, constraining their ability to handle real-world scenes and complex textures across semantic regions. With the success of segment anything model (SAM), generating sufficiently fine-grained region masks can enhance the detail recovery of diffusion-based SR model. However, directly integrating SAM into SR models will result in much higher computational cost. In this paper, we propose the SAM-DiffSR model, which can utilize the fine-grained structure information from SAM in the process of sampling noise to improve the image quality without additional computational cost during inference. In the process of training, we encode structural position information into the segmentation mask from SAM. Then the encoded mask is integrated into the forward diffusion process by modulating it to the sampled noise. This adjustment allows us to independently adapt the noise mean within each corresponding segmentation area. The diffusion model is trained to estimate this modulated noise. Crucially, our proposed framework does NOT change the reverse diffusion process and does NOT require SAM at inference. Experimental results demonstrate the effectiveness of our proposed method, showcasing superior performance in suppressing artifacts, and surpassing existing diffusion-based methods by 0.74 dB at the maximum in terms of PSNR on DIV2K dataset. The code and dataset are available at https://github.com/lose4578/SAM-DiffSR.
Data-efficient Large Vision Models through Sequential Autoregression
Feb 07, 2024



Training general-purpose vision models on purely sequential visual data, eschewing linguistic inputs, has heralded a new frontier in visual understanding. These models are intended to not only comprehend but also seamlessly transit to out-of-domain tasks. However, current endeavors are hamstrung by an over-reliance on colossal models, exemplified by models with upwards of 3B parameters, and the necessity for an extensive corpus of visual data, often comprising a staggering 400B tokens. In this paper, we delve into the development of an efficient, autoregression-based vision model, innovatively architected to operate on a limited dataset. We meticulously demonstrate how this model achieves proficiency in a spectrum of visual tasks spanning both high-level and low-level semantic understanding during the testing phase. Our empirical evaluations underscore the model's agility in adapting to various tasks, heralding a significant reduction in the parameter footprint, and a marked decrease in training data requirements, thereby paving the way for more sustainable and accessible advancements in the field of generalist vision models. The code is available at https://github.com/ggjy/DeLVM.
Vision Superalignment: Weak-to-Strong Generalization for Vision Foundation Models
Feb 06, 2024Recent advancements in large language models have sparked interest in their extraordinary and near-superhuman capabilities, leading researchers to explore methods for evaluating and optimizing these abilities, which is called superalignment. In this context, our paper delves into the realm of vision foundation models, focusing on the concept of weak-to-strong generalization, which involves using a weaker model to supervise a stronger one, aiming to enhance the latter's capabilities beyond the former's limits. We introduce a novel and adaptively adjustable loss function for weak-to-strong supervision. Our comprehensive experiments span various scenarios, including few-shot learning, transfer learning, noisy label learning, and common knowledge distillation settings. The results are striking: our approach not only exceeds the performance benchmarks set by strong-to-strong generalization but also surpasses the outcomes of fine-tuning strong models with whole datasets. This compelling evidence underscores the significant potential of weak-to-strong generalization, showcasing its capability to substantially elevate the performance of vision foundation models. The code is available at https://github.com/ggjy/vision_weak_to_strong.
Species196: A One-Million Semi-supervised Dataset for Fine-grained Species Recognition
Sep 26, 2023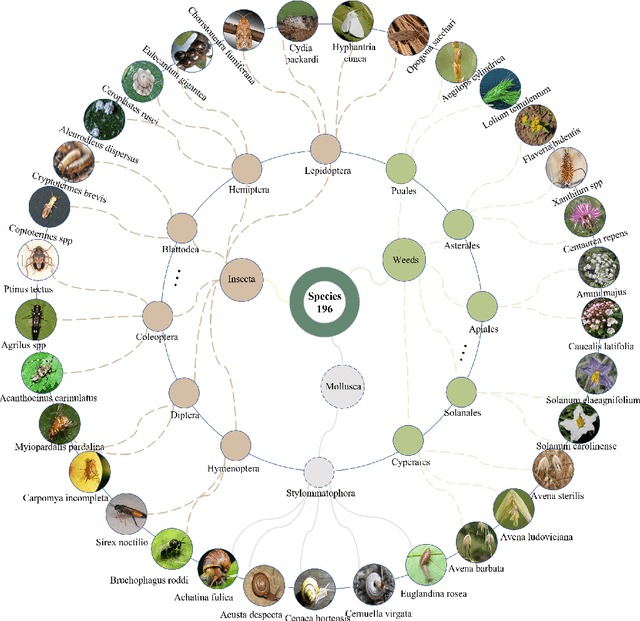
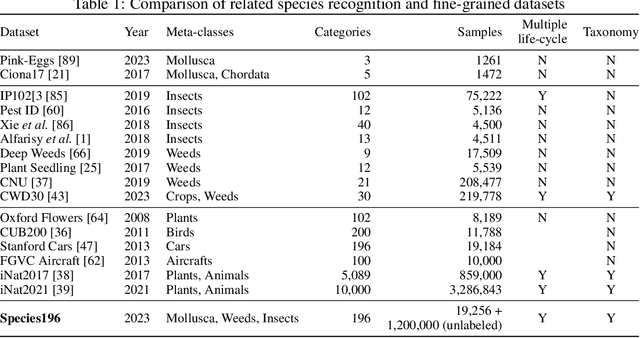
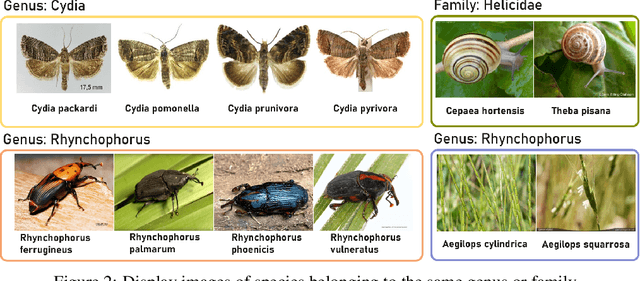

The development of foundation vision models has pushed the general visual recognition to a high level, but cannot well address the fine-grained recognition in specialized domain such as invasive species classification. Identifying and managing invasive species has strong social and ecological value. Currently, most invasive species datasets are limited in scale and cover a narrow range of species, which restricts the development of deep-learning based invasion biometrics systems. To fill the gap of this area, we introduced Species196, a large-scale semi-supervised dataset of 196-category invasive species. It collects over 19K images with expert-level accurate annotations Species196-L, and 1.2M unlabeled images of invasive species Species196-U. The dataset provides four experimental settings for benchmarking the existing models and algorithms, namely, supervised learning, semi-supervised learning, self-supervised pretraining and zero-shot inference ability of large multi-modal models. To facilitate future research on these four learning paradigms, we conduct an empirical study of the representative methods on the introduced dataset. The dataset is publicly available at https://species-dataset.github.io/.
Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism
Sep 25, 2023
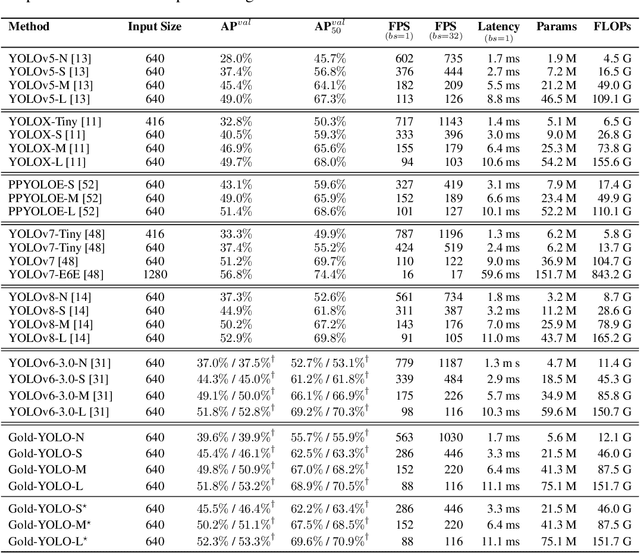


In the past years, YOLO-series models have emerged as the leading approaches in the area of real-time object detection. Many studies pushed up the baseline to a higher level by modifying the architecture, augmenting data and designing new losses. However, we find previous models still suffer from information fusion problem, although Feature Pyramid Network (FPN) and Path Aggregation Network (PANet) have alleviated this. Therefore, this study provides an advanced Gatherand-Distribute mechanism (GD) mechanism, which is realized with convolution and self-attention operations. This new designed model named as Gold-YOLO, which boosts the multi-scale feature fusion capabilities and achieves an ideal balance between latency and accuracy across all model scales. Additionally, we implement MAE-style pretraining in the YOLO-series for the first time, allowing YOLOseries models could be to benefit from unsupervised pretraining. Gold-YOLO-N attains an outstanding 39.9% AP on the COCO val2017 datasets and 1030 FPS on a T4 GPU, which outperforms the previous SOTA model YOLOv6-3.0-N with similar FPS by +2.4%. The PyTorch code is available at https://github.com/huawei-noah/Efficient-Computing/tree/master/Detection/Gold-YOLO, and the MindSpore code is available at https://gitee.com/mindspore/models/tree/master/research/cv/Gold_YOLO.