 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp Convergence Rates for Masked Diffusion Models
Feb 26, 2026Discrete diffusion models have achieved strong empirical performance in text and other symbolic domains, with masked (absorbing-rate) variants emerging as competitive alternatives to autoregressive models. Among existing samplers, the Euler method remains the standard choice in many applications, and more recently, the First-Hitting Sampler (FHS) has shown considerable promise for masked diffusion models. Despite their practical success, the theoretical understanding of these samplers remains limited. Existing analyses are conducted in Kullback-Leibler (KL) divergence, which often yields loose parameter dependencies and requires strong assumptions on score estimation. Moreover, these guarantees do not cover recently developed high-performance sampler of FHS. In this work, we first develop a direct total-variation (TV) based analysis for the Euler method that overcomes these limitations. Our results relax assumptions on score estimation, improve parameter dependencies, and establish convergence guarantees without requiring any surrogate initialization. Also for this setting, we provide the first convergence lower bound for the Euler sampler, establishing tightness with respect to both the data dimension $d$ and the target accuracy $\varepsilon$. Finally, we analyze the FHS sampler and show that it incurs no sampling error beyond that induced by score estimation, which we show to be tight with a matching lower error bound. Overall, our analysis introduces a direct TV-based error decomposition along the CTMC trajectory and a decoupling-based path-wise analysis for FHS, which may be of independent interest.
Learnable Chernoff Baselines for Inference-Time Alignment
Feb 08, 2026We study inference-time reward-guided alignment for generative models. Existing methods often rely on either architecture-specific adaptations or computationally costly inference procedures. We introduce Learnable Chernoff Baselines (LCBs) as a method for efficiently and approximately sampling from the exponentially tilted kernels that arise from KL-regularized reward alignment. Using only black-box sampling access to the pretrained model, LCBs implement a form of rejection sampling with adaptively selected acceptance probabilities, which allows fine-grained control over inference-compute scaling. We establish total-variation guarantees to the ideal aligned model, and demonstrate in both continuous and discrete diffusion settings that LCB sampling closely matches ideal rejection sampling while using substantially fewer queries to the pretrained model.
DiC: Rethinking Conv3x3 Designs in Diffusion Models
Dec 31, 2024



Diffusion models have shown exceptional performance in visual generation tasks. Recently, these models have shifted from traditional U-Shaped CNN-Attention hybrid structures to fully transformer-based isotropic architectures. While these transformers exhibit strong scalability and performance, their reliance on complicated self-attention operation results in slow inference speeds. Contrary to these works, we rethink one of the simplest yet fastest module in deep learning, 3x3 Convolution, to construct a scaled-up purely convolutional diffusion model. We first discover that an Encoder-Decoder Hourglass design outperforms scalable isotropic architectures for Conv3x3, but still under-performing our expectation. Further improving the architecture, we introduce sparse skip connections to reduce redundancy and improve scalability. Based on the architecture, we introduce conditioning improvements including stage-specific embeddings, mid-block condition injection, and conditional gating. These improvements lead to our proposed Diffusion CNN (DiC), which serves as a swift yet competitive diffusion architecture baseline. Experiments on various scales and settings show that DiC surpasses existing diffusion transformers by considerable margins in terms of performance while keeping a good speed advantage. Project page: https://github.com/YuchuanTian/DiC
Theory on Score-Mismatched Diffusion Models and Zero-Shot Conditional Samplers
Oct 17, 2024

The denoising diffusion model has recently emerged as a powerful generative technique, capable of transforming noise into meaningful data. While theoretical convergence guarantees for diffusion models are well established when the target distribution aligns with the training distribution, practical scenarios often present mismatches. One common case is in zero-shot conditional diffusion sampling, where the target conditional distribution is different from the (unconditional) training distribution. These score-mismatched diffusion models remain largely unexplored from a theoretical perspective. In this paper, we present the first performance guarantee with explicit dimensional dependencies for general score-mismatched diffusion samplers, focusing on target distributions with finite second moments. We show that score mismatches result in an asymptotic distributional bias between the target and sampling distributions, proportional to the accumulated mismatch between the target and training distributions. This result can be directly applied to zero-shot conditional samplers for any conditional model, irrespective of measurement noise. Interestingly, the derived convergence upper bound offers useful guidance for designing a novel bias-optimal zero-shot sampler in linear conditional models that minimizes the asymptotic bias. For such bias-optimal samplers, we further establish convergence guarantees with explicit dependencies on dimension and conditioning, applied to several interesting target distributions, including those with bounded support and Gaussian mixtures. Our findings are supported by numerical studies.
Learning Quantized Adaptive Conditions for Diffusion Models
Sep 26, 2024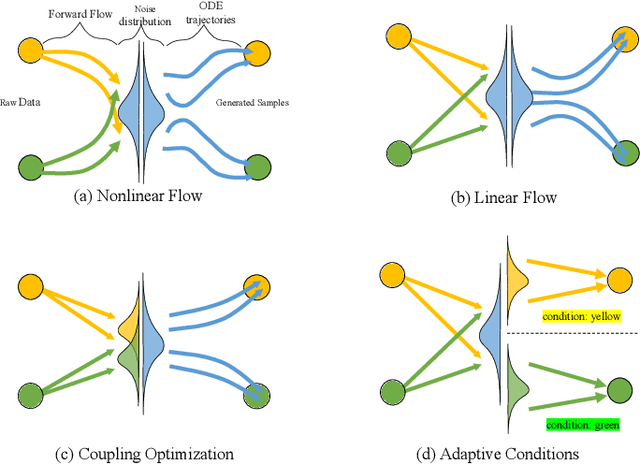

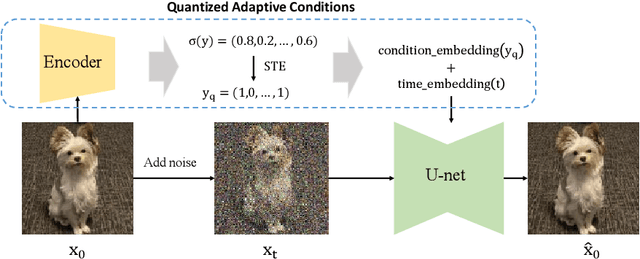

The curvature of ODE trajectories in diffusion models hinders their ability to generate high-quality images in a few number of function evaluations (NFE). In this paper, we propose a novel and effective approach to reduce trajectory curvature by utilizing adaptive conditions. By employing a extremely light-weight quantized encoder, our method incurs only an additional 1% of training parameters, eliminates the need for extra regularization terms, yet achieves significantly better sample quality. Our approach accelerates ODE sampling while preserving the downstream task image editing capabilities of SDE techniques. Extensive experiments verify that our method can generate high quality results under extremely limited sampling costs. With only 6 NFE, we achieve 5.14 FID on CIFAR-10, 6.91 FID on FFHQ 64x64 and 3.10 FID on AFHQv2.
Non-asymptotic Convergence of Discrete-time Diffusion Models: New Approach and Improved Rate
Feb 21, 2024

The denoising diffusion model emerges recently as a powerful generative technique that converts noise into data. Theoretical convergence guarantee has been mainly studied for continuous-time diffusion models, and has been obtained for discrete-time diffusion models only for distributions with bounded support in the literature. In this paper, we establish the convergence guarantee for substantially larger classes of distributions under discrete-time diffusion models and further improve the convergence rate for distributions with bounded support. In particular, we first establish the convergence rates for both smooth and general (possibly non-smooth) distributions having finite second moment. We then specialize our results to a number of interesting classes of distributions with explicit parameter dependencies, including distributions with Lipschitz scores, Gaussian mixture distributions, and distributions with bounded support. We further propose a novel accelerated sampler and show that it improves the convergence rates of the corresponding regular sampler by orders of magnitude with respect to all system parameters. For distributions with bounded support, our result improves the dimensional dependence of the previous convergence rate by orders of magnitude. Our study features a novel analysis technique that constructs tilting factor representation of the convergence error and exploits Tweedie's formula for handling Taylor expansion power terms.
Less is More: Physical-enhanced Radar-Inertial Odometry
Feb 03, 2024Radar offers the advantage of providing additional physical properties related to observed objects. In this study, we design a physical-enhanced radar-inertial odometry system that capitalizes on the Doppler velocities and radar cross-section information. The filter for static radar points, correspondence estimation, and residual functions are all strengthened by integrating the physical properties. We conduct experiments on both public datasets and our self-collected data, with different mobile platforms and sensor types. Our quantitative results demonstrate that the proposed radar-inertial odometry system outperforms alternative methods using the physical-enhanced components. Our findings also reveal that using the physical properties results in fewer radar points for odometry estimation, but the performance is still guaranteed and even improved, thus aligning with the ``less is more'' principle.
Quickest Change Detection with Post-Change Density Estimation
Nov 25, 2023



The problem of quickest change detection in a sequence of independent observations is considered. The pre-change distribution is assumed to be known, while the post-change distribution is unknown. Two tests based on post-change density estimation are developed for this problem, the window-limited non-parametric generalized likelihood ratio (NGLR) CuSum test and the non-parametric window-limited adaptive (NWLA) CuSum test. Both tests do not assume any knowledge of the post-change distribution, except that the post-change density satisfies certain smoothness conditions that allows for efficient non-parametric estimation. Also, they do not require any pre-collected post-change training samples. Under certain convergence conditions on the density estimator, it is shown that both tests are first-order asymptotically optimal, as the false alarm rate goes to zero. The analysis is validated through numerical results, where both tests are compared with baseline tests that have distributional knowledge.
Energy Transformer
Feb 14, 2023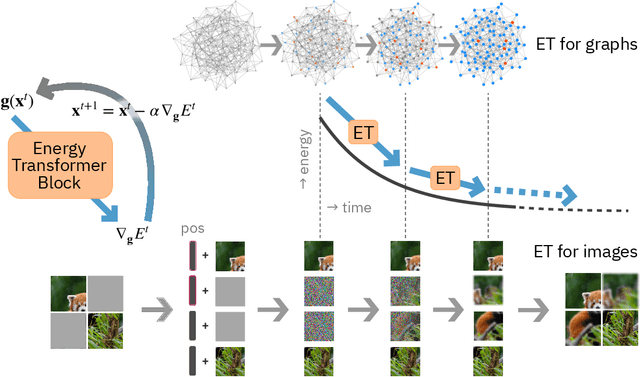
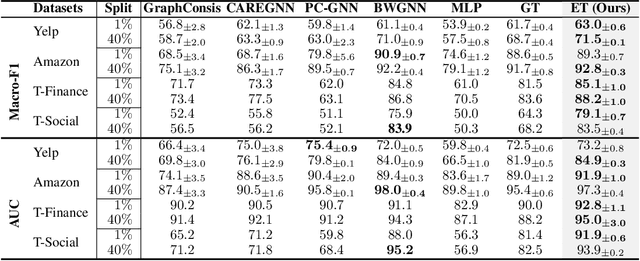
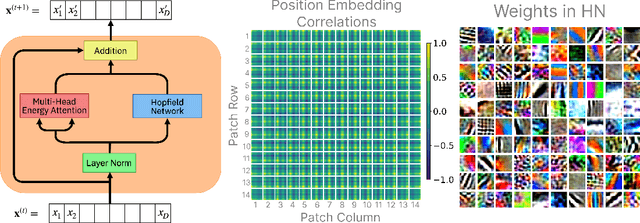

Transformers have become the de facto models of choice in machine learning, typically leading to impressive performance on many applications. At the same time, the architectural development in the transformer world is mostly driven by empirical findings, and the theoretical understanding of their architectural building blocks is rather limited. In contrast, Dense Associative Memory models or Modern Hopfield Networks have a well-established theoretical foundation, but have not yet demonstrated truly impressive practical results. We propose a transformer architecture that replaces the sequence of feedforward transformer blocks with a single large Associative Memory model. Our novel architecture, called Energy Transformer (or ET for short), has many of the familiar architectural primitives that are often used in the current generation of transformers. However, it is not identical to the existing architectures. The sequence of transformer layers in ET is purposely designed to minimize a specifically engineered energy function, which is responsible for representing the relationships between the tokens. As a consequence of this computational principle, the attention in ET is different from the conventional attention mechanism. In this work, we introduce the theoretical foundations of ET, explore it's empirical capabilities using the image completion task, and obtain strong quantitative results on the graph anomaly detection task.
Quickest Change Detection with Leave-one-out Density Estimation
Nov 04, 2022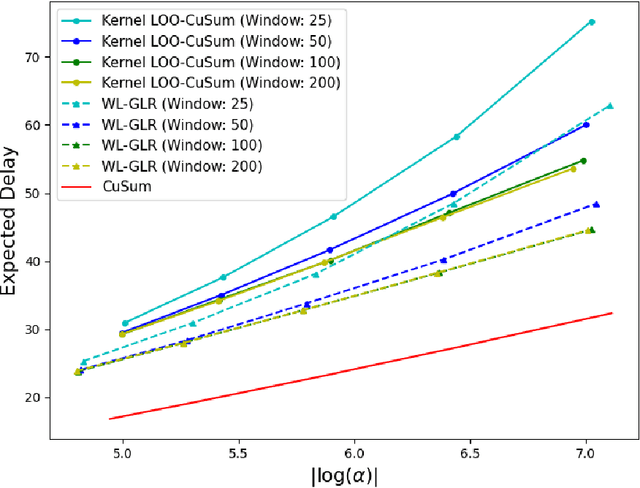
The problem of quickest change detection in a sequence of independent observations is considered. The pre-change distribution is assumed to be known, while the post-change distribution is completely unknown. A window-limited leave-one-out (LOO) CuSum test is developed, which does not assume any knowledge of the post-change distribution, and does not require any post-change training samples. It is shown that, with certain convergence conditions on the density estimator, the LOO-CuSum test is first-order asymptotically optimal, as the false alarm rate goes to zero. The analysis is validated through numerical results, where the LOO-CuSum test is compared with baseline tests that have distributional knowledge.