 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyphrase Extraction Using Neighborhood Knowledge Based on Word Embeddings
Paper and Code
Nov 13, 2021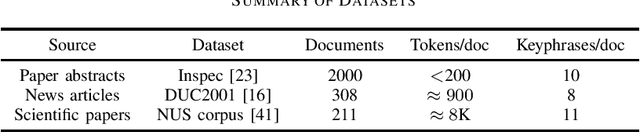
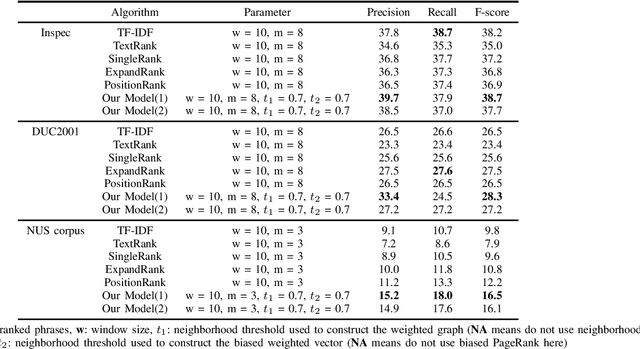
Keyphrase extraction is the task of finding several interesting phrases in a text document, which provide a list of the main topics within the document. Most existing graph-based models use co-occurrence links as cohesion indicators to model the relationship of syntactic elements. However, a word may have different forms of expression within the document, and may have several synonyms as well. Simply using co-occurrence information cannot capture this information. In this paper, we enhance the graph-based ranking model by leveraging word embeddings as background knowledge to add semantic information to the inter-word graph. Our approach is evaluated on established benchmark datasets and empirical results show that the word embedding neighborhood information improves the model performance.