 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastFLUX: Pruning FLUX with Block-wise Replacement and Sandwich Training
Jun 10, 2025Recent advancements in text-to-image (T2I) generation have led to the emergence of highly expressive models such as diffusion transformers (DiTs), exemplified by FLUX. However, their massive parameter sizes lead to slow inference, high memory usage, and poor deployability. Existing acceleration methods (e.g., single-step distillation and attention pruning) often suffer from significant performance degradation and incur substantial training costs. To address these limitations, we propose FastFLUX, an architecture-level pruning framework designed to enhance the inference efficiency of FLUX. At its core is the Block-wise Replacement with Linear Layers (BRLL) method, which replaces structurally complex residual branches in ResBlocks with lightweight linear layers while preserving the original shortcut connections for stability. Furthermore, we introduce Sandwich Training (ST), a localized fine-tuning strategy that leverages LoRA to supervise neighboring blocks, mitigating performance drops caused by structural replacement. Experiments show that our FastFLUX maintains high image quality under both qualitative and quantitative evaluations, while significantly improving inference speed, even with 20\% of the hierarchy pruned. Our code will be available soon.
Reasoning with OmniThought: A Large CoT Dataset with Verbosity and Cognitive Difficulty Annotations
May 16, 2025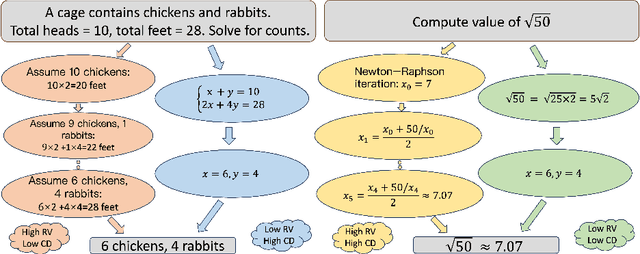



The emergence of large reasoning models (LRMs) has transformed Natural Language Processing by excelling in complex tasks such as mathematical problem-solving and code generation. These models leverage chain-of-thought (CoT) processes, enabling them to emulate human-like reasoning strategies. However, the advancement of LRMs is hindered by the lack of comprehensive CoT datasets. Current resources often fail to provide extensive reasoning problems with coherent CoT processes distilled from multiple teacher models and do not account for multifaceted properties describing the internal characteristics of CoTs. To address these challenges, we introduce OmniThought, a large-scale dataset featuring 2 million CoT processes generated and validated by two powerful LRMs as teacher models. Each CoT process in OmniThought is annotated with novel Reasoning Verbosity (RV) and Cognitive Difficulty (CD) scores, which describe the appropriateness of CoT verbosity and cognitive difficulty level for models to comprehend these reasoning processes. We further establish a self-reliant pipeline to curate this dataset. Extensive experiments using Qwen2.5 models of various sizes demonstrate the positive impact of our proposed scores on LRM training effectiveness. Based on the proposed OmniThought dataset, we further train and release a series of high-performing LRMs, specifically equipped with stronger reasoning abilities and optimal CoT output length and difficulty level. Our contributions significantly enhance the development and training of LRMs for solving complex tasks.
Training Small Reasoning LLMs with Cognitive Preference Alignment
Apr 14, 2025The reasoning capabilities of large language models (LLMs), such as OpenAI's o1 and DeepSeek-R1, have seen substantial advancements through deep thinking. However, these enhancements come with significant resource demands, underscoring the need to explore strategies to train effective reasoning LLMs with far fewer parameters. A critical challenge is that smaller models have different capacities and cognitive trajectories than their larger counterparts. Hence, direct distillation of chain-of-thought (CoT) results from large LLMs to smaller ones can be sometimes ineffective and requires a huge amount of annotated data. In this paper, we introduce a novel framework called Critique-Rethink-Verify (CRV), designed for training smaller yet powerful reasoning LLMs. Our CRV framework consists of multiple LLM agents, each specializing in unique abilities: (i) critiquing the CoTs according to the cognitive capabilities of smaller models, (ii) rethinking and refining these CoTs based on the critiques, and (iii) verifying the correctness of the refined results. We further propose the cognitive preference optimization (CogPO) algorithm to enhance the reasoning abilities of smaller models by aligning thoughts of these models with their cognitive capacities. Comprehensive evaluations on challenging reasoning benchmarks demonstrate the efficacy of CRV and CogPO, which outperforms other training methods by a large margin.
Learning Quantized Adaptive Conditions for Diffusion Models
Sep 26, 2024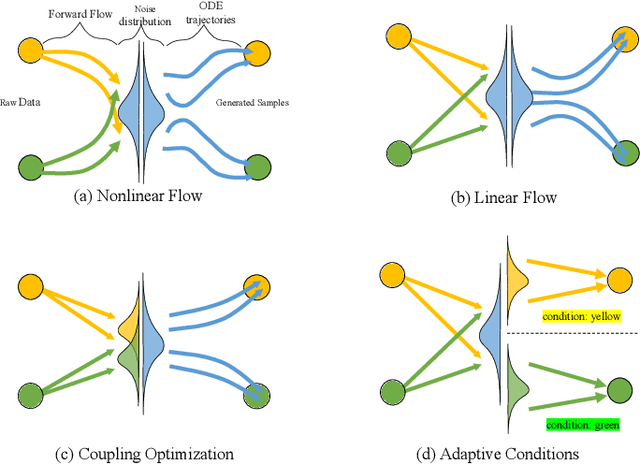

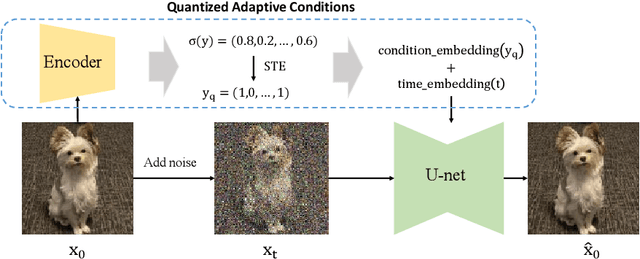

The curvature of ODE trajectories in diffusion models hinders their ability to generate high-quality images in a few number of function evaluations (NFE). In this paper, we propose a novel and effective approach to reduce trajectory curvature by utilizing adaptive conditions. By employing a extremely light-weight quantized encoder, our method incurs only an additional 1% of training parameters, eliminates the need for extra regularization terms, yet achieves significantly better sample quality. Our approach accelerates ODE sampling while preserving the downstream task image editing capabilities of SDE techniques. Extensive experiments verify that our method can generate high quality results under extremely limited sampling costs. With only 6 NFE, we achieve 5.14 FID on CIFAR-10, 6.91 FID on FFHQ 64x64 and 3.10 FID on AFHQv2.
Probabilistic Results on the Architecture of Mathematical Reasoning Aligned by Cognitive Alternation
Aug 17, 2023


We envision a machine capable of solving mathematical problems. Dividing the quantitative reasoning system into two parts: thought processes and cognitive processes, we provide probabilistic descriptions of the architecture.
Im2Oil: Stroke-Based Oil Painting Rendering with Linearly Controllable Fineness Via Adaptive Sampling
Sep 27, 2022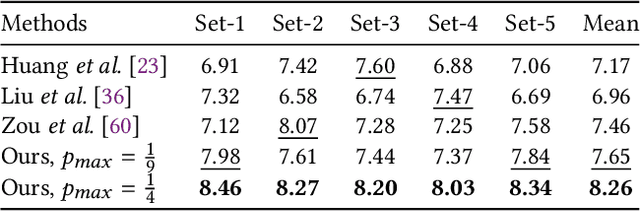



This paper proposes a novel stroke-based rendering (SBR) method that translates images into vivid oil paintings. Previous SBR techniques usually formulate the oil painting problem as pixel-wise approximation. Different from this technique route, we treat oil painting creation as an adaptive sampling problem. Firstly, we compute a probability density map based on the texture complexity of the input image. Then we use the Voronoi algorithm to sample a set of pixels as the stroke anchors. Next, we search and generate an individual oil stroke at each anchor. Finally, we place all the strokes on the canvas to obtain the oil painting. By adjusting the hyper-parameter maximum sampling probability, we can control the oil painting fineness in a linear manner. Comparison with existing state-of-the-art oil painting techniques shows that our results have higher fidelity and more realistic textures. A user opinion test demonstrates that people behave more preference toward our oil paintings than the results of other methods. More interesting results and the code are in https://github.com/TZYSJTU/Im2Oil.
A Strong Baseline for Semi-Supervised Incremental Few-Shot Learning
Nov 04, 2021
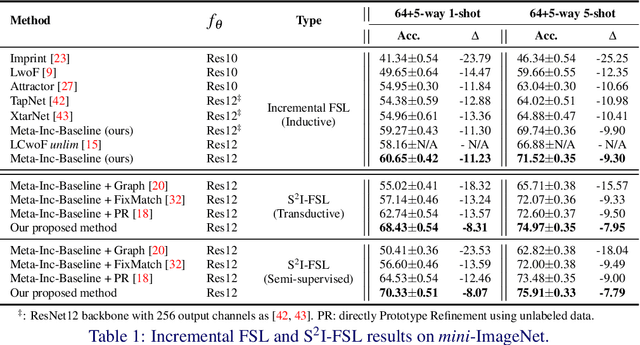
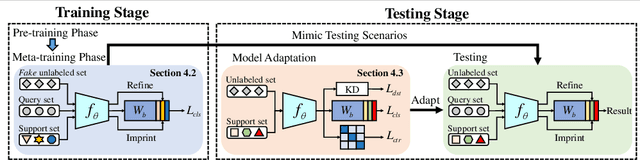
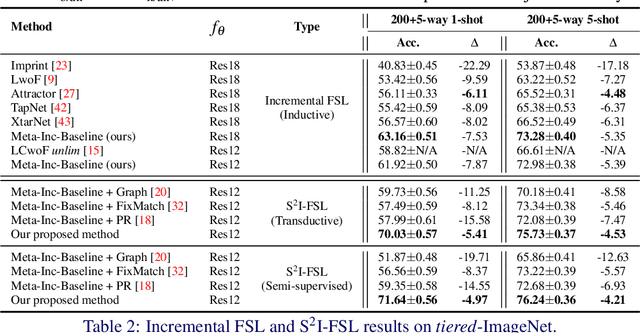
Few-shot learning (FSL) aims to learn models that generalize to novel classes with limited training samples. Recent works advance FSL towards a scenario where unlabeled examples are also available and propose semi-supervised FSL methods. Another line of methods also cares about the performance of base classes in addition to the novel ones and thus establishes the incremental FSL scenario. In this paper, we generalize the above two under a more realistic yet complex setting, named by Semi-Supervised Incremental Few-Shot Learning (S2 I-FSL). To tackle the task, we propose a novel paradigm containing two parts: (1) a well-designed meta-training algorithm for mitigating ambiguity between base and novel classes caused by unreliable pseudo labels and (2) a model adaptation mechanism to learn discriminative features for novel classes while preserving base knowledge using few labeled and all the unlabeled data. Extensive experiments on standard FSL, semi-supervised FSL, incremental FSL, and the firstly built S2 I-FSL benchmarks demonstrate the effectiveness of our proposed method.
Deformable Tube Network for Action Detection in Videos
Jul 03, 2019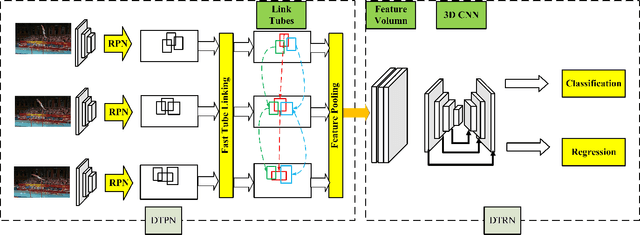
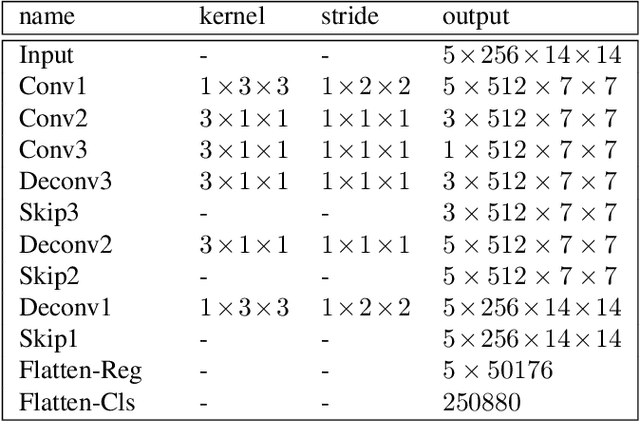

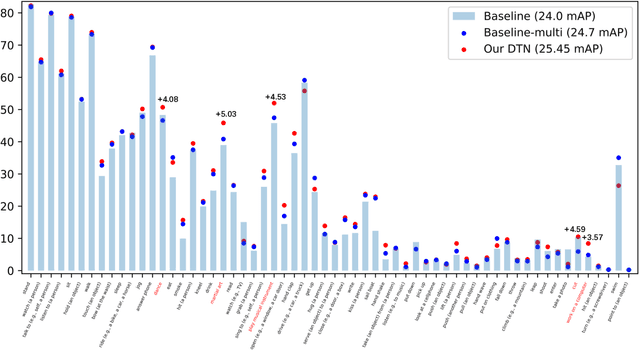
We address the problem of spatio-temporal action detection in videos. Existing methods commonly either ignore temporal context in action recognition and localization, or lack the modelling of flexible shapes of action tubes. In this paper, we propose a two-stage action detector called Deformable Tube Network (DTN), which is composed of a Deformation Tube Proposal Network (DTPN) and a Deformable Tube Recognition Network (DTRN) similar to the Faster R-CNN architecture. In DTPN, a fast proposal linking algorithm (FTL) is introduced to connect region proposals across frames to generate multiple deformable action tube proposals. To perform action detection, we design a 3D convolution network with skip connections for tube classification and regression. Modelling action proposals as deformable tubes explicitly considers the shape of action tubes compared to 3D cuboids. Moreover, 3D convolution based recognition network can learn temporal dynamics sufficiently for action detection. Our experimental results show that we significantly outperform the methods with 3D cuboids and obtain the state-of-the-art results on both UCF-Sports and AVA datasets.
Knowing Where to Look? Analysis on Attention of Visual Question Answering System
Oct 09, 2018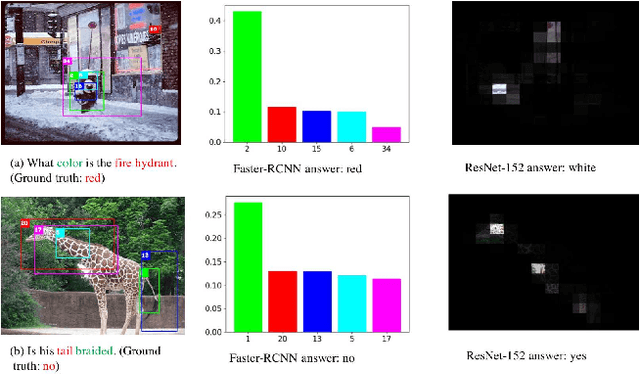
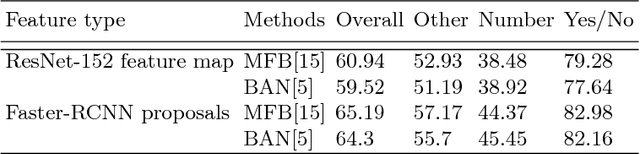
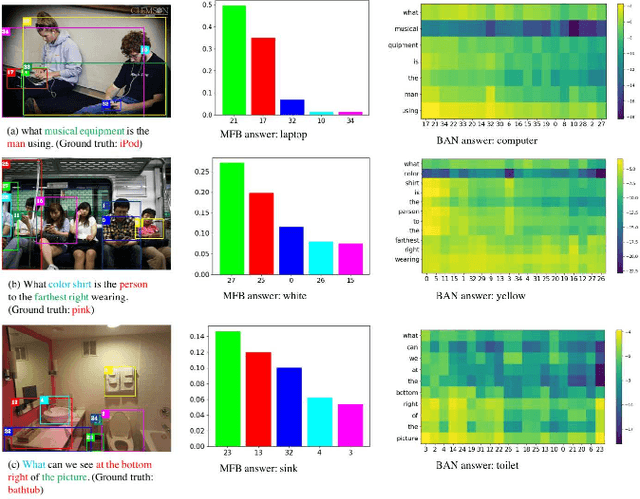

Attention mechanisms have been widely used in Visual Question Answering (VQA) solutions due to their capacity to model deep cross-domain interactions. Analyzing attention maps offers us a perspective to find out limitations of current VQA systems and an opportunity to further improve them. In this paper, we select two state-of-the-art VQA approaches with attention mechanisms to study their robustness and disadvantages by visualizing and analyzing their estimated attention maps. We find that both methods are sensitive to features, and simultaneously, they perform badly for counting and multi-object related questions. We believe that the findings and analytical method will help researchers identify crucial challenges on the way to improve their own VQA systems.