 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDavarOCR: A Toolbox for OCR and Multi-Modal Document Understanding
Jul 14, 2022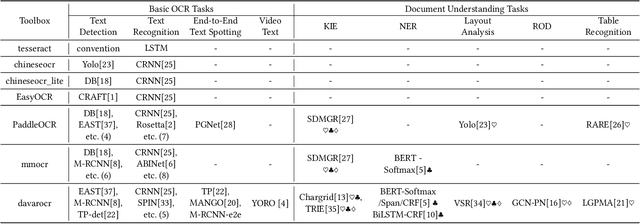


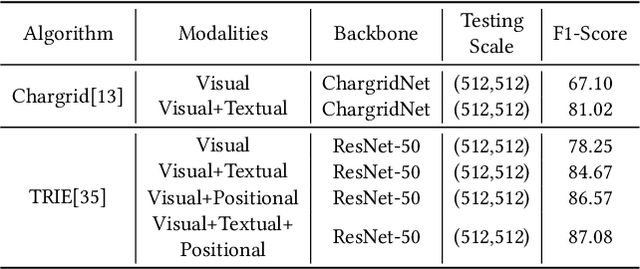
This paper presents DavarOCR, an open-source toolbox for OCR and document understanding tasks. DavarOCR currently implements 19 advanced algorithms, covering 9 different task forms. DavarOCR provides detailed usage instructions and the trained models for each algorithm. Compared with the previous opensource OCR toolbox, DavarOCR has relatively more complete support for the sub-tasks of the cutting-edge technology of document understanding. In order to promote the development and application of OCR technology in academia and industry, we pay more attention to the use of modules that different sub-domains of technology can share. DavarOCR is publicly released at https://github.com/hikopensource/Davar-Lab-OCR.
A Strong Baseline for Semi-Supervised Incremental Few-Shot Learning
Nov 04, 2021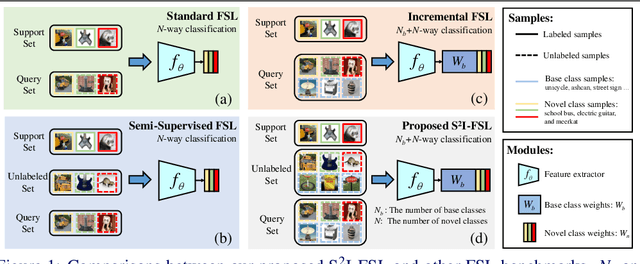
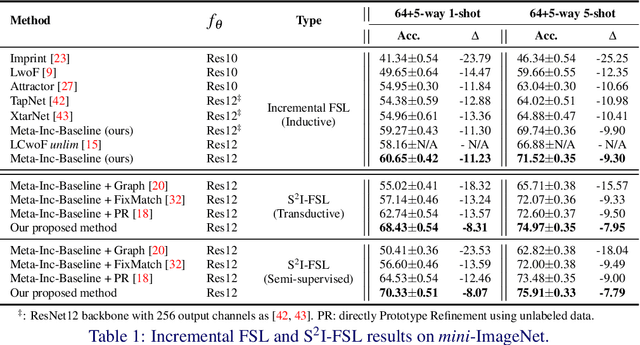
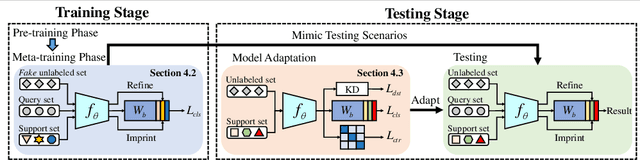
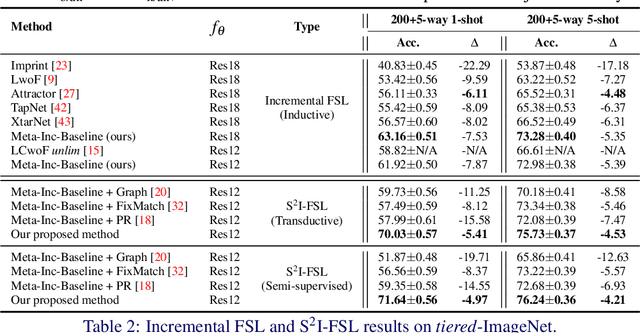
Few-shot learning (FSL) aims to learn models that generalize to novel classes with limited training samples. Recent works advance FSL towards a scenario where unlabeled examples are also available and propose semi-supervised FSL methods. Another line of methods also cares about the performance of base classes in addition to the novel ones and thus establishes the incremental FSL scenario. In this paper, we generalize the above two under a more realistic yet complex setting, named by Semi-Supervised Incremental Few-Shot Learning (S2 I-FSL). To tackle the task, we propose a novel paradigm containing two parts: (1) a well-designed meta-training algorithm for mitigating ambiguity between base and novel classes caused by unreliable pseudo labels and (2) a model adaptation mechanism to learn discriminative features for novel classes while preserving base knowledge using few labeled and all the unlabeled data. Extensive experiments on standard FSL, semi-supervised FSL, incremental FSL, and the firstly built S2 I-FSL benchmarks demonstrate the effectiveness of our proposed method.
Learning a Domain Classifier Bank for Unsupervised Adaptive Object Detection
Jul 06, 2020
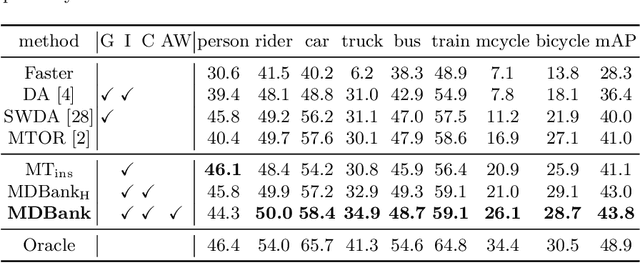
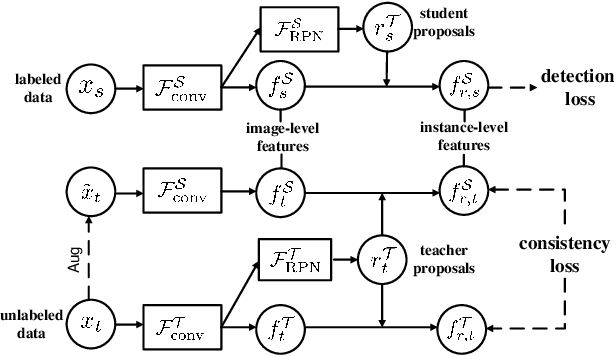
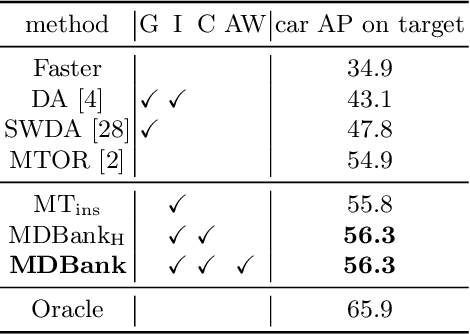
In real applications, object detectors based on deep networks still face challenges of the large domain gap between the labeled training data and unlabeled testing data. To reduce the gap, recent techniques are proposed by aligning the image/instance-level features between source and unlabeled target domains. However, these methods suffer from the suboptimal problem mainly because of ignoring the category information of object instances. To tackle this issue, we develop a fine-grained domain alignment approach with a well-designed domain classifier bank that achieves the instance-level alignment respecting to their categories. Specifically, we first employ the mean teacher paradigm to generate pseudo labels for unlabeled samples. Then we implement the class-level domain classifiers and group them together, called domain classifier bank, in which each domain classifier is responsible for aligning features of a specific class. We assemble the bare object detector with the proposed fine-grained domain alignment mechanism as the adaptive detector, and optimize it with a developed crossed adaptive weighting mechanism. Extensive experiments on three popular transferring benchmarks demonstrate the effectiveness of our method and achieve the new remarkable state-of-the-arts.
Deformable Tube Network for Action Detection in Videos
Jul 03, 2019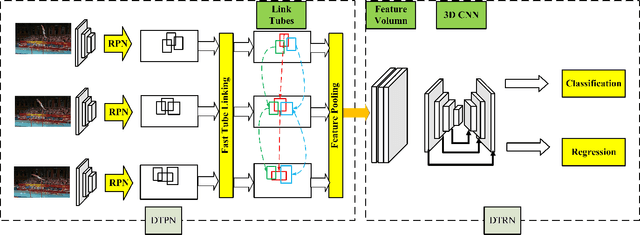
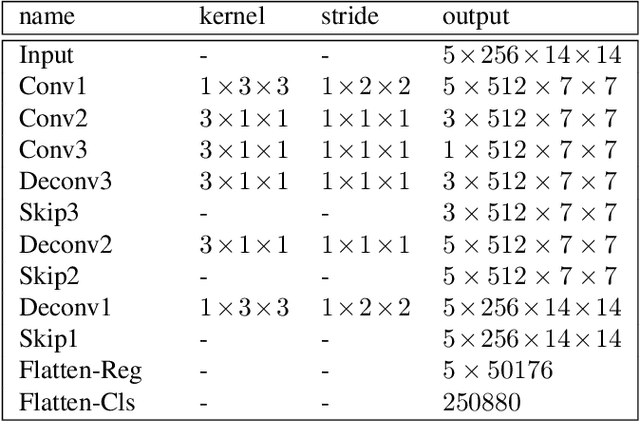

We address the problem of spatio-temporal action detection in videos. Existing methods commonly either ignore temporal context in action recognition and localization, or lack the modelling of flexible shapes of action tubes. In this paper, we propose a two-stage action detector called Deformable Tube Network (DTN), which is composed of a Deformation Tube Proposal Network (DTPN) and a Deformable Tube Recognition Network (DTRN) similar to the Faster R-CNN architecture. In DTPN, a fast proposal linking algorithm (FTL) is introduced to connect region proposals across frames to generate multiple deformable action tube proposals. To perform action detection, we design a 3D convolution network with skip connections for tube classification and regression. Modelling action proposals as deformable tubes explicitly considers the shape of action tubes compared to 3D cuboids. Moreover, 3D convolution based recognition network can learn temporal dynamics sufficiently for action detection. Our experimental results show that we significantly outperform the methods with 3D cuboids and obtain the state-of-the-art results on both UCF-Sports and AVA datasets.