 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable Tube Network for Action Detection in Videos
Paper and Code
Jul 03, 2019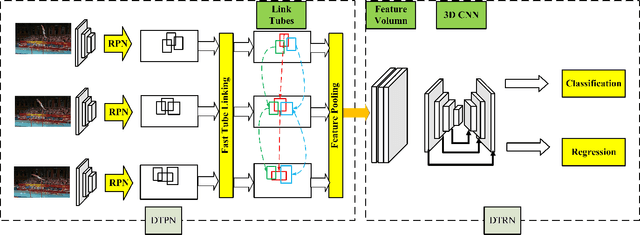
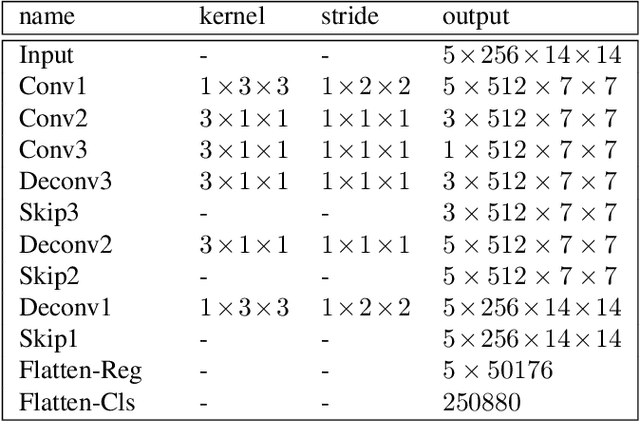

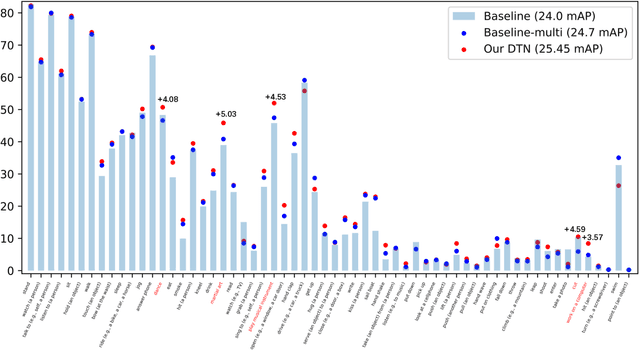
We address the problem of spatio-temporal action detection in videos. Existing methods commonly either ignore temporal context in action recognition and localization, or lack the modelling of flexible shapes of action tubes. In this paper, we propose a two-stage action detector called Deformable Tube Network (DTN), which is composed of a Deformation Tube Proposal Network (DTPN) and a Deformable Tube Recognition Network (DTRN) similar to the Faster R-CNN architecture. In DTPN, a fast proposal linking algorithm (FTL) is introduced to connect region proposals across frames to generate multiple deformable action tube proposals. To perform action detection, we design a 3D convolution network with skip connections for tube classification and regression. Modelling action proposals as deformable tubes explicitly considers the shape of action tubes compared to 3D cuboids. Moreover, 3D convolution based recognition network can learn temporal dynamics sufficiently for action detection. Our experimental results show that we significantly outperform the methods with 3D cuboids and obtain the state-of-the-art results on both UCF-Sports and AVA datasets.