 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSE: Boosting Vision-based Roadside 3D Object Detection with Scene Cues
Apr 08, 2024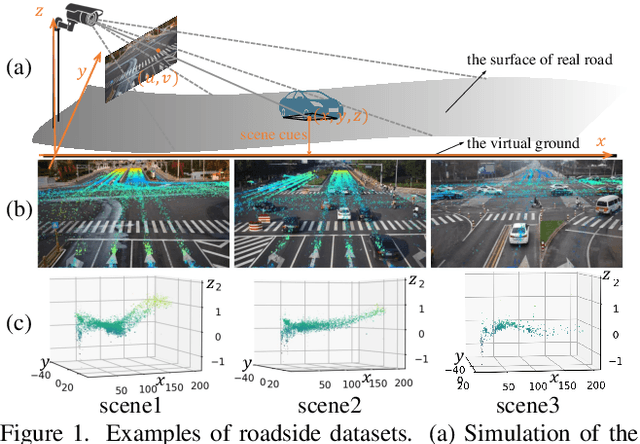
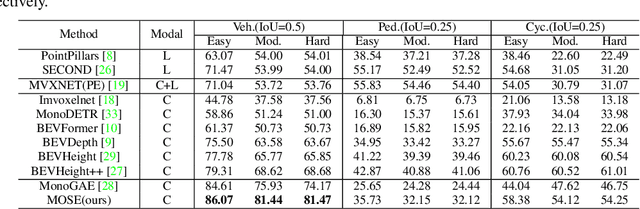
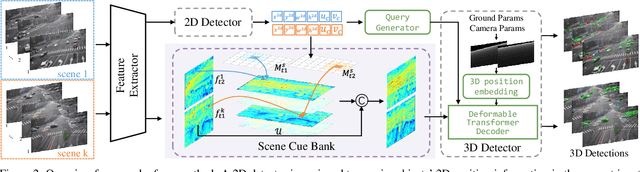
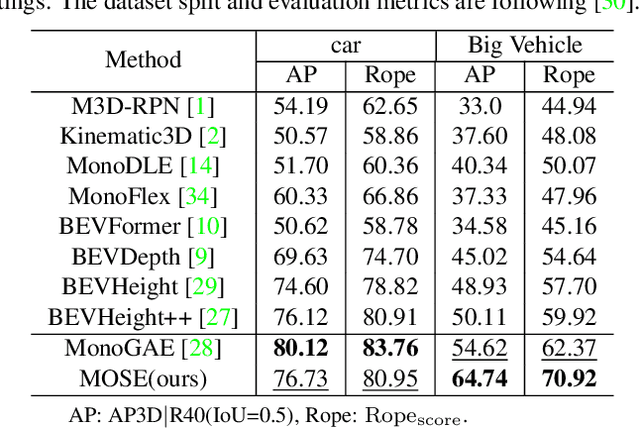
3D object detection based on roadside cameras is an additional way for autonomous driving to alleviate the challenges of occlusion and short perception range from vehicle cameras. Previous methods for roadside 3D object detection mainly focus on modeling the depth or height of objects, neglecting the stationary of cameras and the characteristic of inter-frame consistency. In this work, we propose a novel framework, namely MOSE, for MOnocular 3D object detection with Scene cuEs. The scene cues are the frame-invariant scene-specific features, which are crucial for object localization and can be intuitively regarded as the height between the surface of the real road and the virtual ground plane. In the proposed framework, a scene cue bank is designed to aggregate scene cues from multiple frames of the same scene with a carefully designed extrinsic augmentation strategy. Then, a transformer-based decoder lifts the aggregated scene cues as well as the 3D position embeddings for 3D object location, which boosts generalization ability in heterologous scenes. The extensive experiment results on two public benchmarks demonstrate the state-of-the-art performance of the proposed method, which surpasses the existing methods by a large margin.
Distilling Object Detectors With Global Knowledge
Oct 17, 2022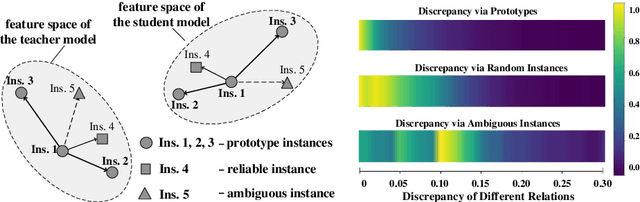
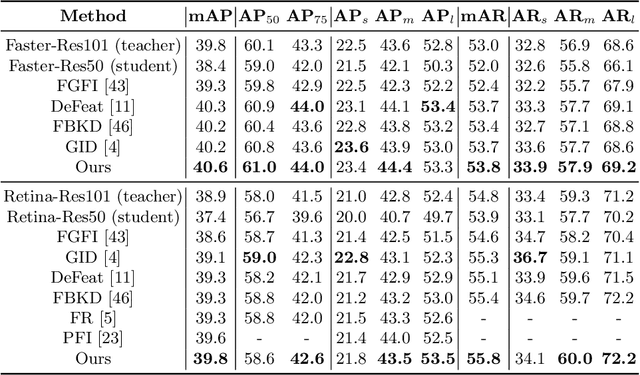
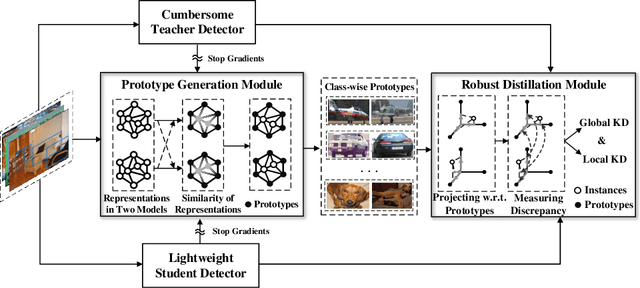
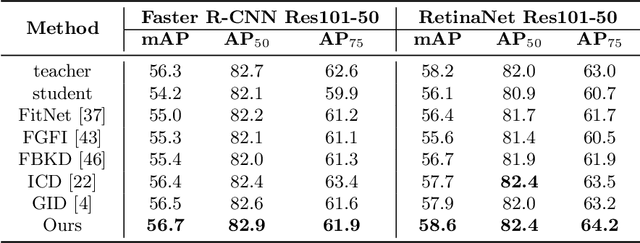
Knowledge distillation learns a lightweight student model that mimics a cumbersome teacher. Existing methods regard the knowledge as the feature of each instance or their relations, which is the instance-level knowledge only from the teacher model, i.e., the local knowledge. However, the empirical studies show that the local knowledge is much noisy in object detection tasks, especially on the blurred, occluded, or small instances. Thus, a more intrinsic approach is to measure the representations of instances w.r.t. a group of common basis vectors in the two feature spaces of the teacher and the student detectors, i.e., global knowledge. Then, the distilling algorithm can be applied as space alignment. To this end, a novel prototype generation module (PGM) is proposed to find the common basis vectors, dubbed prototypes, in the two feature spaces. Then, a robust distilling module (RDM) is applied to construct the global knowledge based on the prototypes and filtrate noisy global and local knowledge by measuring the discrepancy of the representations in two feature spaces. Experiments with Faster-RCNN and RetinaNet on PASCAL and COCO datasets show that our method achieves the best performance for distilling object detectors with various backbones, which even surpasses the performance of the teacher model. We also show that the existing methods can be easily combined with global knowledge and obtain further improvement. Code is available: https://github.com/hikvision-research/DAVAR-Lab-ML.
Learning a Domain Classifier Bank for Unsupervised Adaptive Object Detection
Jul 06, 2020
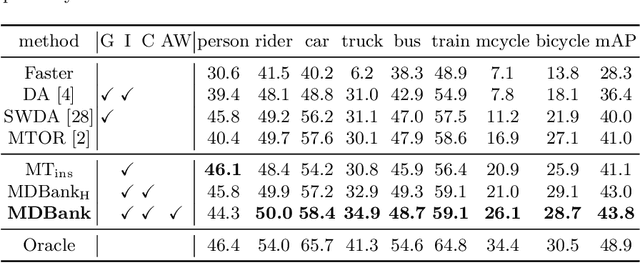
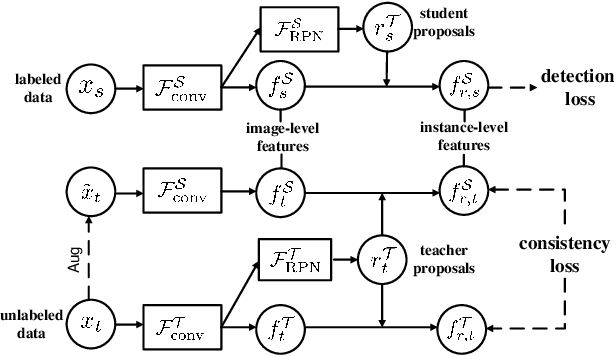
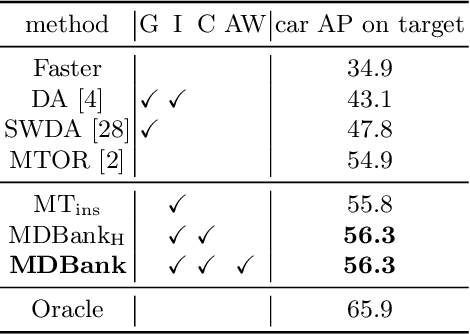
In real applications, object detectors based on deep networks still face challenges of the large domain gap between the labeled training data and unlabeled testing data. To reduce the gap, recent techniques are proposed by aligning the image/instance-level features between source and unlabeled target domains. However, these methods suffer from the suboptimal problem mainly because of ignoring the category information of object instances. To tackle this issue, we develop a fine-grained domain alignment approach with a well-designed domain classifier bank that achieves the instance-level alignment respecting to their categories. Specifically, we first employ the mean teacher paradigm to generate pseudo labels for unlabeled samples. Then we implement the class-level domain classifiers and group them together, called domain classifier bank, in which each domain classifier is responsible for aligning features of a specific class. We assemble the bare object detector with the proposed fine-grained domain alignment mechanism as the adaptive detector, and optimize it with a developed crossed adaptive weighting mechanism. Extensive experiments on three popular transferring benchmarks demonstrate the effectiveness of our method and achieve the new remarkable state-of-the-arts.
Text Perceptron: Towards End-to-End Arbitrary-Shaped Text Spotting
Feb 17, 2020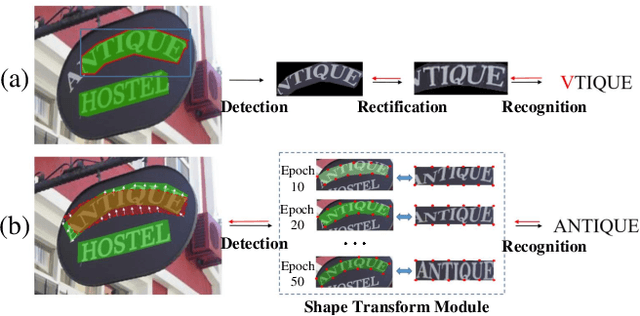
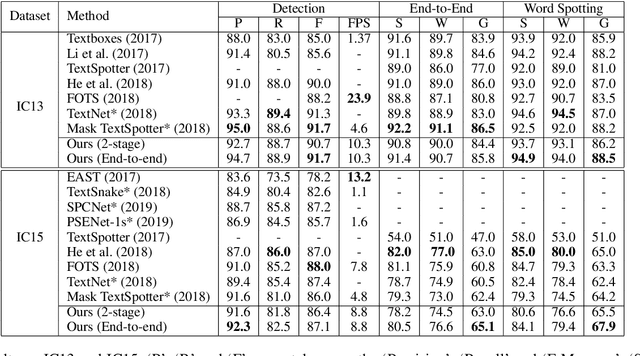
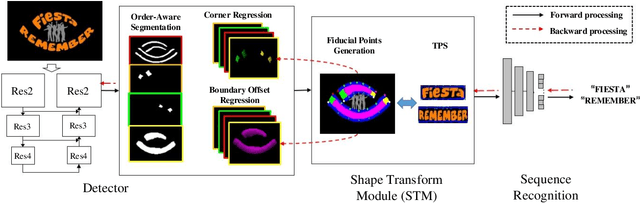
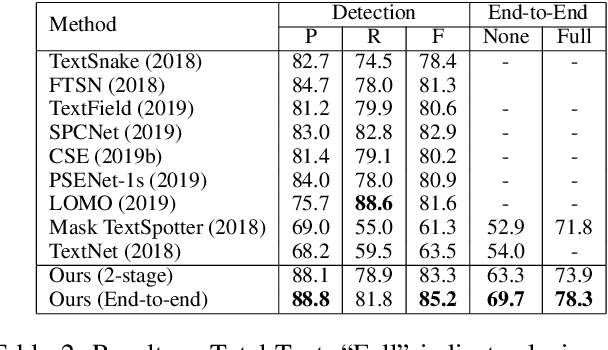
Many approaches have recently been proposed to detect irregular scene text and achieved promising results. However, their localization results may not well satisfy the following text recognition part mainly because of two reasons: 1) recognizing arbitrary shaped text is still a challenging task, and 2) prevalent non-trainable pipeline strategies between text detection and text recognition will lead to suboptimal performances. To handle this incompatibility problem, in this paper we propose an end-to-end trainable text spotting approach named Text Perceptron. Concretely, Text Perceptron first employs an efficient segmentation-based text detector that learns the latent text reading order and boundary information. Then a novel Shape Transform Module (abbr. STM) is designed to transform the detected feature regions into regular morphologies without extra parameters. It unites text detection and the following recognition part into a whole framework, and helps the whole network achieve global optimization. Experiments show that our method achieves competitive performance on two standard text benchmarks, i.e., ICDAR 2013 and ICDAR 2015, and also obviously outperforms existing methods on irregular text benchmarks SCUT-CTW1500 and Total-Text.
Online PCB Defect Detector On A New PCB Defect Dataset
Feb 17, 2019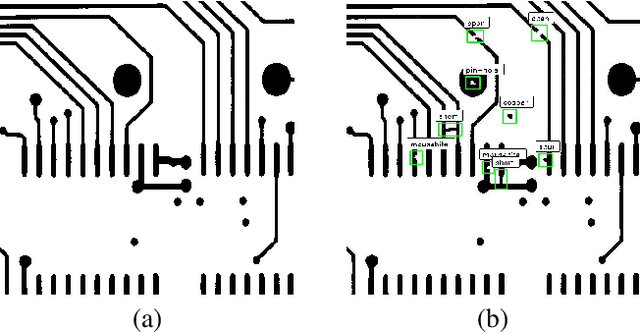
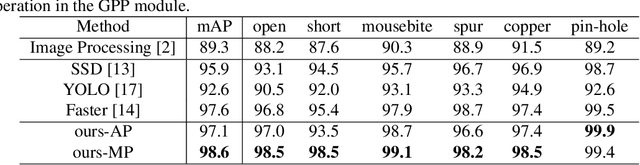
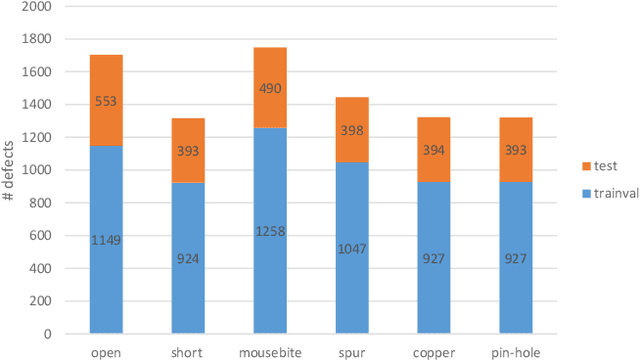

Previous works for PCB defect detection based on image difference and image processing techniques have already achieved promising performance. However, they sometimes fall short because of the unaccounted defect patterns or over-sensitivity about some hyper-parameters. In this work, we design a deep model that accurately detects PCB defects from an input pair of a detect-free template and a defective tested image. A novel group pyramid pooling module is proposed to efficiently extract features of a large range of resolutions, which are merged by group to predict PCB defect of corresponding scales. To train the deep model, a dataset is established, namely DeepPCB, which contains 1,500 image pairs with annotations including positions of 6 common types of PCB defects. Experiment results validate the effectiveness and efficiency of the proposed model by achieving $98.6\%$ mAP @ 62 FPS on DeepPCB dataset. This dataset is now available at: https://github.com/tangsanli5201/DeepPCB.
Adversarial Attack Type I: Generating False Positives
Sep 03, 2018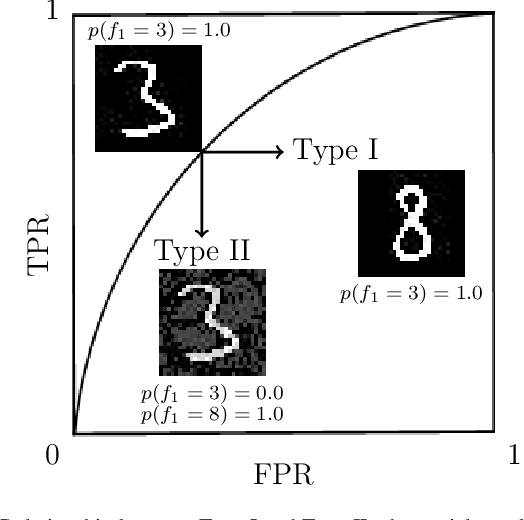
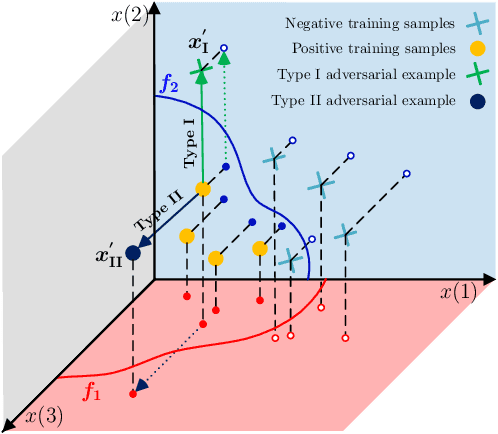
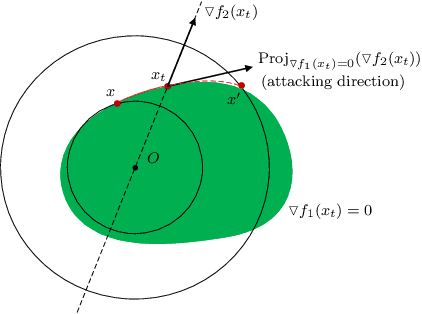
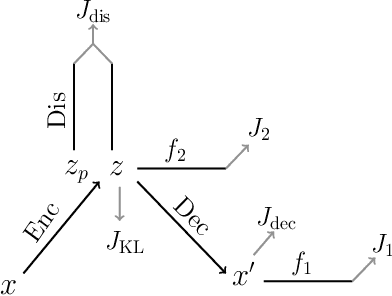
False positive and false negative rates are equally important for evaluating the performance of a classifier. Adversarial examples by increasing false negative rate have been studied in recent years. However, harming a classifier by increasing false positive rate is almost blank, since it is much more difficult to generate a new and meaningful positive than the negative. To generate false positives, a supervised generative framework is proposed in this paper. Experiment results show that our method is practical and effective to generate those adversarial examples on large-scale image datasets.