 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSE: Boosting Vision-based Roadside 3D Object Detection with Scene Cues
Paper and Code
Apr 08, 2024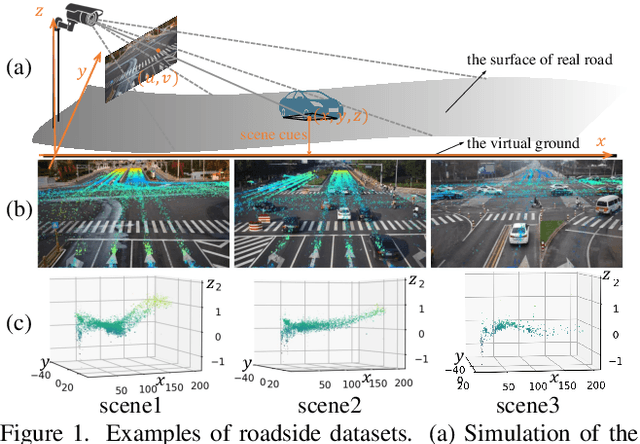
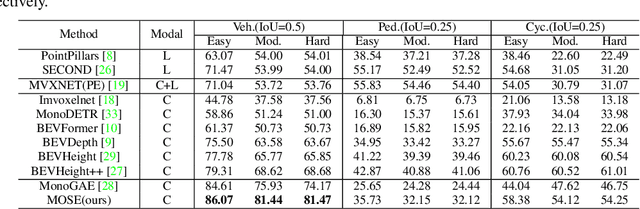
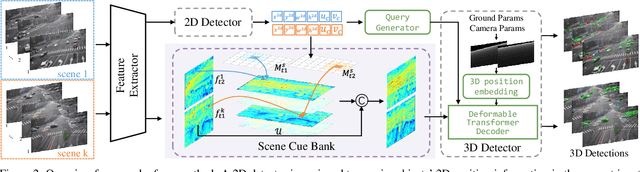
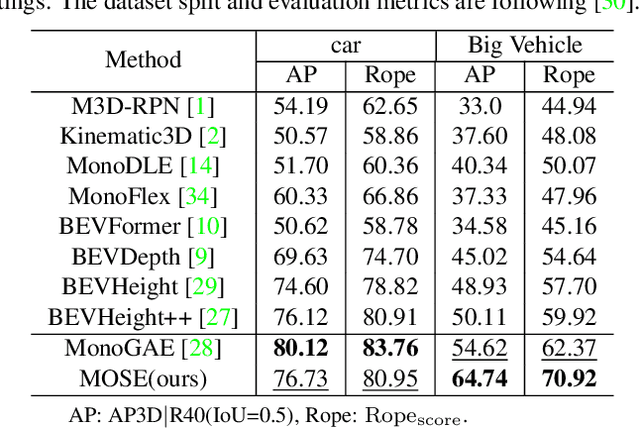
3D object detection based on roadside cameras is an additional way for autonomous driving to alleviate the challenges of occlusion and short perception range from vehicle cameras. Previous methods for roadside 3D object detection mainly focus on modeling the depth or height of objects, neglecting the stationary of cameras and the characteristic of inter-frame consistency. In this work, we propose a novel framework, namely MOSE, for MOnocular 3D object detection with Scene cuEs. The scene cues are the frame-invariant scene-specific features, which are crucial for object localization and can be intuitively regarded as the height between the surface of the real road and the virtual ground plane. In the proposed framework, a scene cue bank is designed to aggregate scene cues from multiple frames of the same scene with a carefully designed extrinsic augmentation strategy. Then, a transformer-based decoder lifts the aggregated scene cues as well as the 3D position embeddings for 3D object location, which boosts generalization ability in heterologous scenes. The extensive experiment results on two public benchmarks demonstrate the state-of-the-art performance of the proposed method, which surpasses the existing methods by a large margin.