 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSE: Boosting Vision-based Roadside 3D Object Detection with Scene Cues
Apr 08, 2024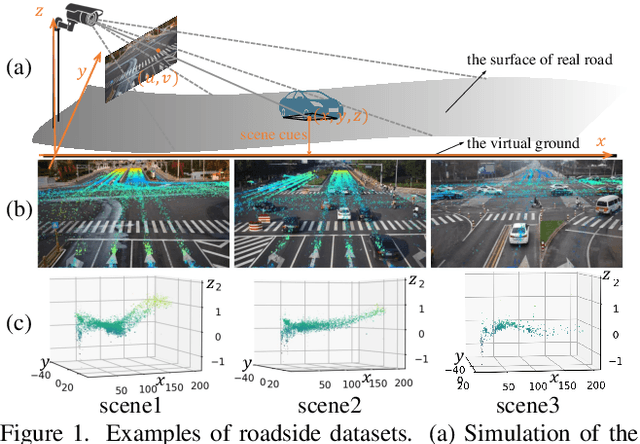
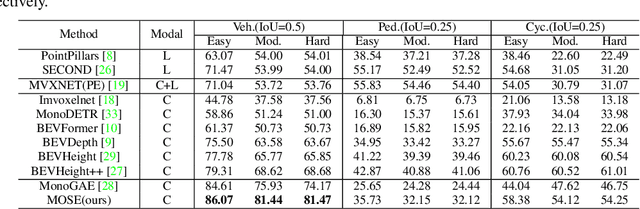
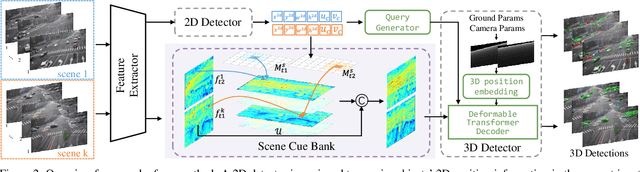
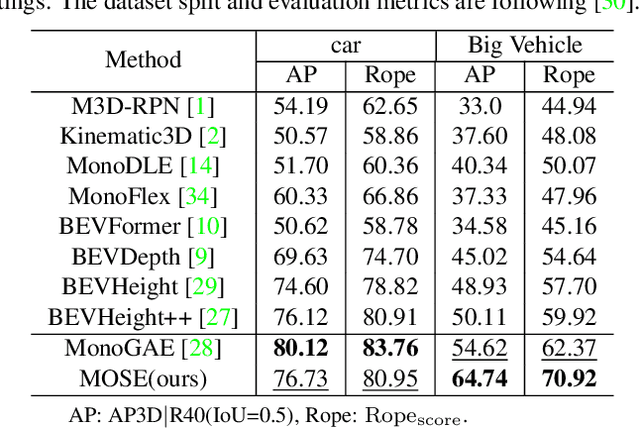
3D object detection based on roadside cameras is an additional way for autonomous driving to alleviate the challenges of occlusion and short perception range from vehicle cameras. Previous methods for roadside 3D object detection mainly focus on modeling the depth or height of objects, neglecting the stationary of cameras and the characteristic of inter-frame consistency. In this work, we propose a novel framework, namely MOSE, for MOnocular 3D object detection with Scene cuEs. The scene cues are the frame-invariant scene-specific features, which are crucial for object localization and can be intuitively regarded as the height between the surface of the real road and the virtual ground plane. In the proposed framework, a scene cue bank is designed to aggregate scene cues from multiple frames of the same scene with a carefully designed extrinsic augmentation strategy. Then, a transformer-based decoder lifts the aggregated scene cues as well as the 3D position embeddings for 3D object location, which boosts generalization ability in heterologous scenes. The extensive experiment results on two public benchmarks demonstrate the state-of-the-art performance of the proposed method, which surpasses the existing methods by a large margin.
STGIN: Spatial-Temporal Graph Interaction Network for Large-scale POI Recommendation
Sep 05, 2023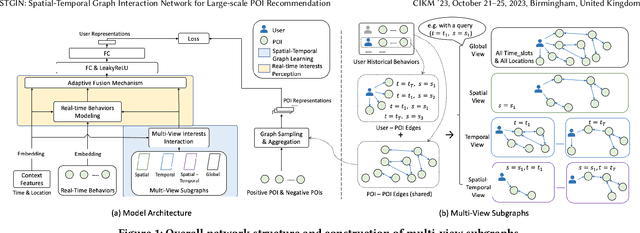
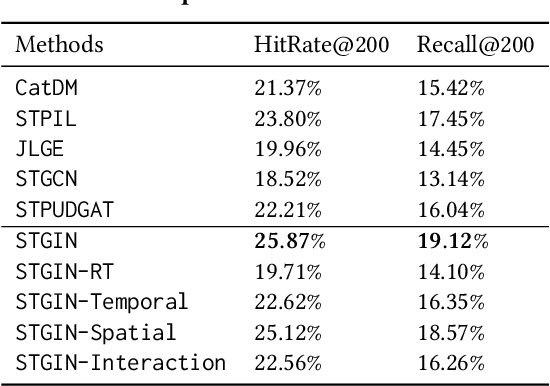

In Location-Based Services, Point-Of-Interest(POI) recommendation plays a crucial role in both user experience and business opportunities. Graph neural networks have been proven effective in providing personalized POI recommendation services. However, there are still two critical challenges. First, existing graph models attempt to capture users' diversified interests through a unified graph, which limits their ability to express interests in various spatial-temporal contexts. Second, the efficiency limitations of graph construction and graph sampling in large-scale systems make it difficult to adapt quickly to new real-time interests. To tackle the above challenges, we propose a novel Spatial-Temporal Graph Interaction Network. Specifically, we construct subgraphs of spatial, temporal, spatial-temporal, and global views respectively to precisely characterize the user's interests in various contexts. In addition, we design an industry-friendly framework to track the user's latest interests. Extensive experiments on the real-world dataset show that our method outperforms state-of-the-art models. This work has been successfully deployed in a large e-commerce platform, delivering a 1.1% CTR and 6.3% RPM improvement.
AutoHEnsGNN: Winning Solution to AutoGraph Challenge for KDD Cup 2020
Nov 25, 2021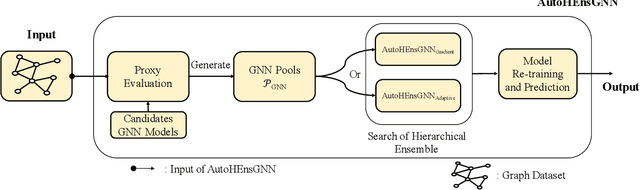
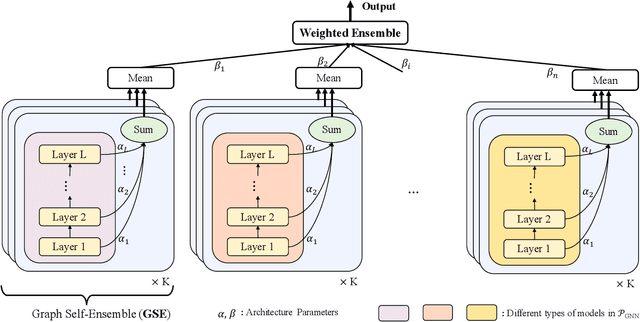
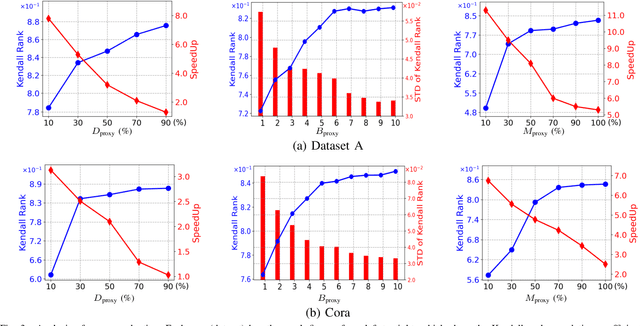
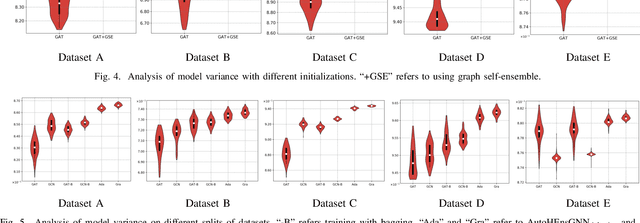
Graph Neural Networks (GNNs) have become increasingly popular and achieved impressive results in many graph-based applications. However, extensive manual work and domain knowledge are required to design effective architectures, and the results of GNN models have high variance with different training setups, which limits the application of existing GNN models. In this paper, we present AutoHEnsGNN, a framework to build effective and robust models for graph tasks without any human intervention. AutoHEnsGNN won first place in the AutoGraph Challenge for KDD Cup 2020, and achieved the best rank score of five real-life datasets in the final phase. Given a task, AutoHEnsGNN first applies a fast proxy evaluation to automatically select a pool of promising GNN models. Then it builds a hierarchical ensemble framework: 1) We propose graph self-ensemble (GSE), which can reduce the variance of weight initialization and efficiently exploit the information of local and global neighborhoods; 2) Based on GSE, a weighted ensemble of different types of GNN models is used to effectively learn more discriminative node representations. To efficiently search the architectures and ensemble weights, we propose AutoHEnsGNN$_{\text{Gradient}}$, which treats the architectures and ensemble weights as architecture parameters and uses gradient-based architecture search to obtain optimal configurations, and AutoHEnsGNN$_{\text{Adaptive}}$, which can adaptively adjust the ensemble weight based on the model accuracy. Extensive experiments on node classification, graph classification, edge prediction and KDD Cup challenge demonstrate the effectiveness and generality of AutoHEnsGNN
AutoSmart: An Efficient and Automatic Machine Learning framework for Temporal Relational Data
Sep 09, 2021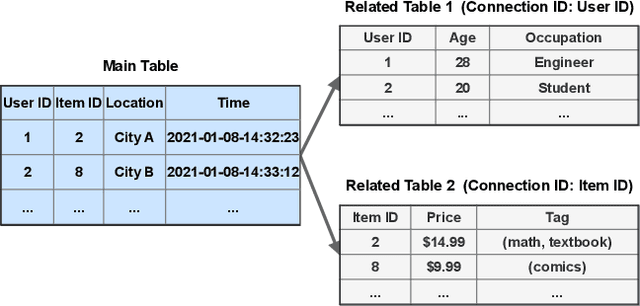

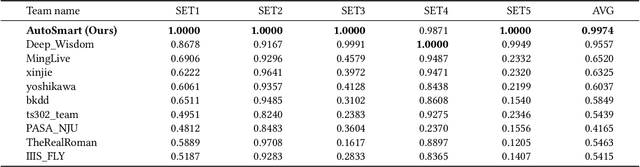
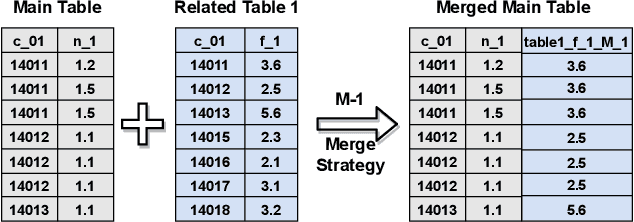
Temporal relational data, perhaps the most commonly used data type in industrial machine learning applications, needs labor-intensive feature engineering and data analyzing for giving precise model predictions. An automatic machine learning framework is needed to ease the manual efforts in fine-tuning the models so that the experts can focus more on other problems that really need humans' engagement such as problem definition, deployment, and business services. However, there are three main challenges for building automatic solutions for temporal relational data: 1) how to effectively and automatically mining useful information from the multiple tables and the relations from them? 2) how to be self-adjustable to control the time and memory consumption within a certain budget? and 3) how to give generic solutions to a wide range of tasks? In this work, we propose our solution that successfully addresses the above issues in an end-to-end automatic way. The proposed framework, AutoSmart, is the winning solution to the KDD Cup 2019 of the AutoML Track, which is one of the largest AutoML competition to date (860 teams with around 4,955 submissions). The framework includes automatic data processing, table merging, feature engineering, and model tuning, with a time\&memory controller for efficiently and automatically formulating the models. The proposed framework outperforms the baseline solution significantly on several datasets in various domains.
Deep Position-wise Interaction Network for CTR Prediction
Jun 17, 2021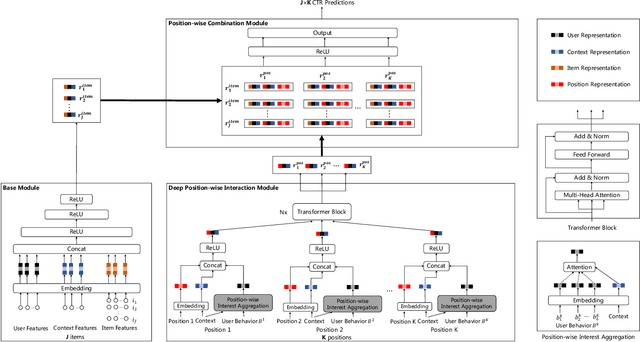
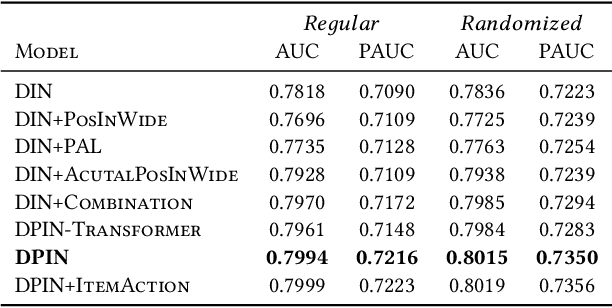
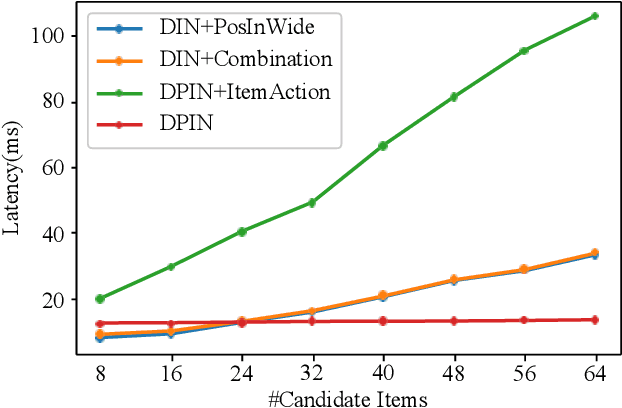
Click-through rate (CTR) prediction plays an important role in online advertising and recommender systems. In practice, the training of CTR models depends on click data which is intrinsically biased towards higher positions since higher position has higher CTR by nature. Existing methods such as actual position training with fixed position inference and inverse propensity weighted training with no position inference alleviate the bias problem to some extend. However, the different treatment of position information between training and inference will inevitably lead to inconsistency and sub-optimal online performance. Meanwhile, the basic assumption of these methods, i.e., the click probability is the product of examination probability and relevance probability, is oversimplified and insufficient to model the rich interaction between position and other information. In this paper, we propose a Deep Position-wise Interaction Network (DPIN) to efficiently combine all candidate items and positions for estimating CTR at each position, achieving consistency between offline and online as well as modeling the deep non-linear interaction among position, user, context and item under the limit of serving performance. Following our new treatment to the position bias in CTR prediction, we propose a new evaluation metrics named PAUC (position-wise AUC) that is suitable for measuring the ranking quality at a given position. Through extensive experiments on a real world dataset, we show empirically that our method is both effective and efficient in solving position bias problem. We have also deployed our method in production and observed statistically significant improvement over a highly optimized baseline in a rigorous A/B test.
Full-Resolution Encoder-Decoder Networks with Multi-Scale Feature Fusion for Human Pose Estimation
Jun 01, 2021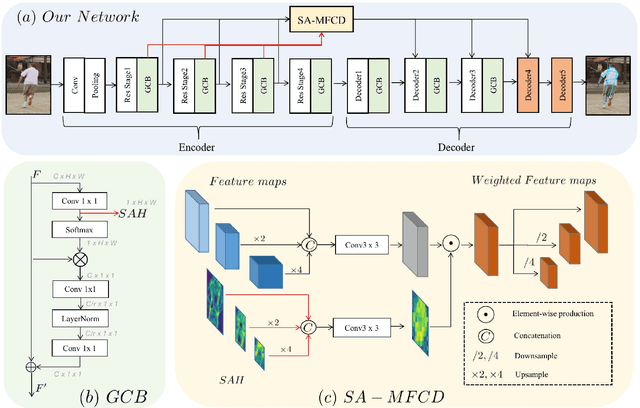

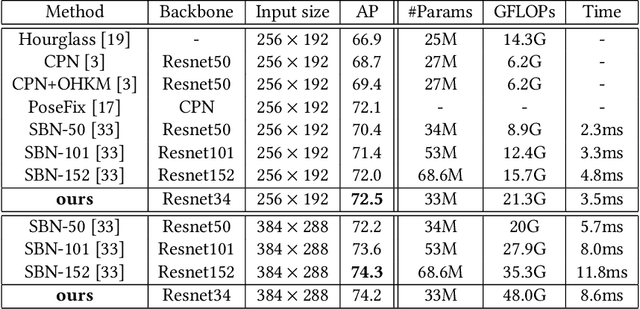
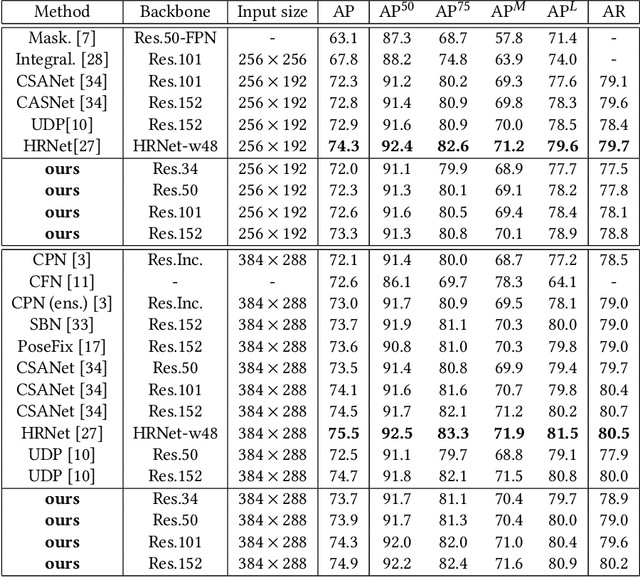
To achieve more accurate 2D human pose estimation, we extend the successful encoder-decoder network, simple baseline network (SBN), in three ways. To reduce the quantization errors caused by the large output stride size, two more decoder modules are appended to the end of the simple baseline network to get full output resolution. Then, the global context blocks (GCBs) are added to the encoder and decoder modules to enhance them with global context features. Furthermore, we propose a novel spatial-attention-based multi-scale feature collection and distribution module (SA-MFCD) to fuse and distribute multi-scale features to boost the pose estimation. Experimental results on the MS COCO dataset indicate that our network can remarkably improve the accuracy of human pose estimation over SBN, our network using ResNet34 as the backbone network can even achieve the same accuracy as SBN with ResNet152, and our networks can achieve superior results with big backbone networks.
AdaSpeech: Adaptive Text to Speech for Custom Voice
Mar 01, 2021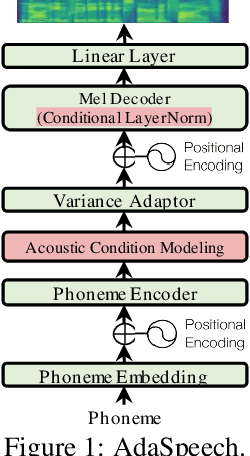
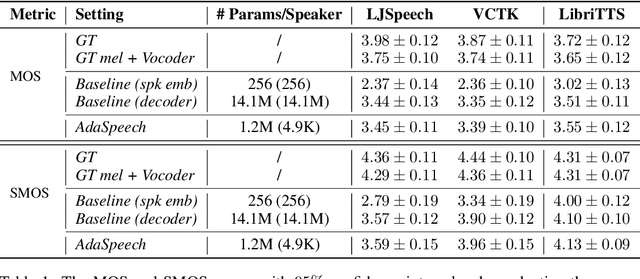
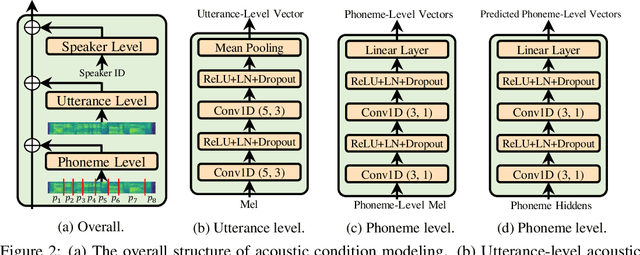
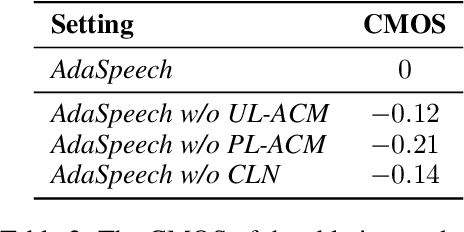
Custom voice, a specific text to speech (TTS) service in commercial speech platforms, aims to adapt a source TTS model to synthesize personal voice for a target speaker using few speech data. Custom voice presents two unique challenges for TTS adaptation: 1) to support diverse customers, the adaptation model needs to handle diverse acoustic conditions that could be very different from source speech data, and 2) to support a large number of customers, the adaptation parameters need to be small enough for each target speaker to reduce memory usage while maintaining high voice quality. In this work, we propose AdaSpeech, an adaptive TTS system for high-quality and efficient customization of new voices. We design several techniques in AdaSpeech to address the two challenges in custom voice: 1) To handle different acoustic conditions, we use two acoustic encoders to extract an utterance-level vector and a sequence of phoneme-level vectors from the target speech during training; in inference, we extract the utterance-level vector from a reference speech and use an acoustic predictor to predict the phoneme-level vectors. 2) To better trade off the adaptation parameters and voice quality, we introduce conditional layer normalization in the mel-spectrogram decoder of AdaSpeech, and fine-tune this part in addition to speaker embedding for adaptation. We pre-train the source TTS model on LibriTTS datasets and fine-tune it on VCTK and LJSpeech datasets (with different acoustic conditions from LibriTTS) with few adaptation data, e.g., 20 sentences, about 1 minute speech. Experiment results show that AdaSpeech achieves much better adaptation quality than baseline methods, with only about 5K specific parameters for each speaker, which demonstrates its effectiveness for custom voice. Audio samples are available at https://speechresearch.github.io/adaspeech/.
MultiSpeech: Multi-Speaker Text to Speech with Transformer
Jun 08, 2020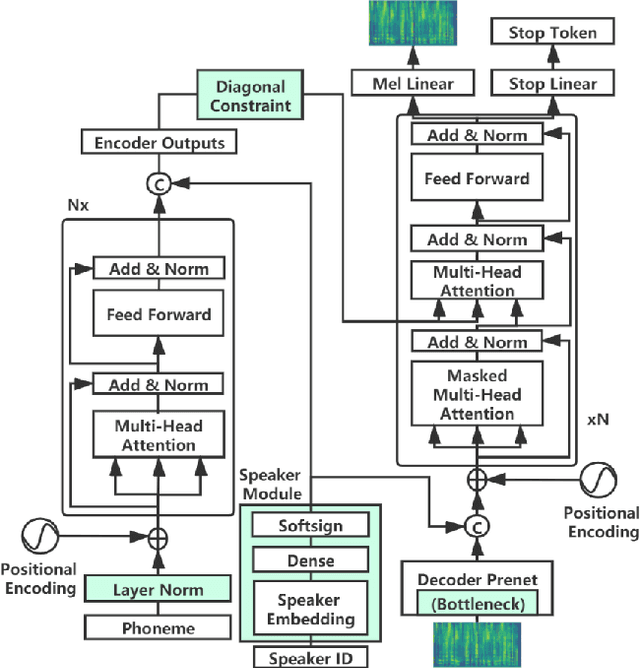
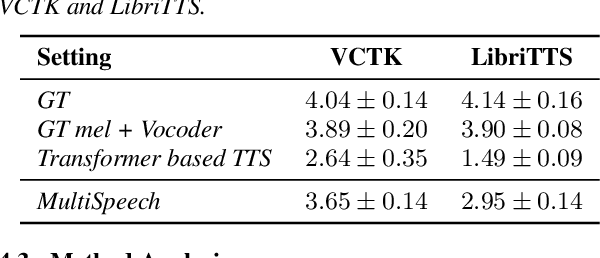
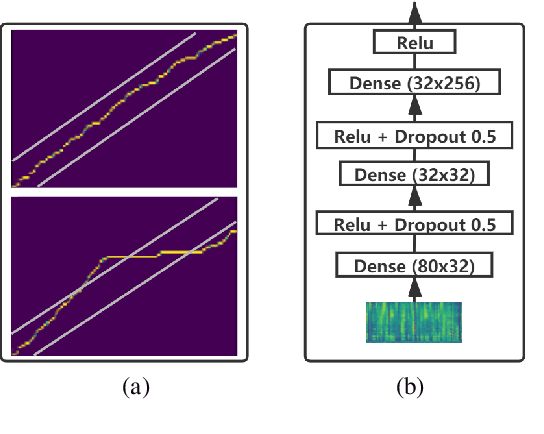
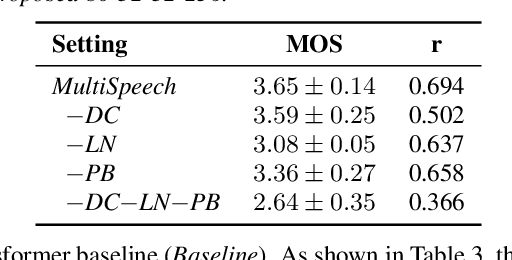
Transformer-based text to speech (TTS) model (e.g., Transformer TTS~\cite{li2019neural}, FastSpeech~\cite{ren2019fastspeech}) has shown the advantages of training and inference efficiency over RNN-based model (e.g., Tacotron~\cite{shen2018natural}) due to its parallel computation in training and/or inference. However, the parallel computation increases the difficulty while learning the alignment between text and speech in Transformer, which is further magnified in the multi-speaker scenario with noisy data and diverse speakers, and hinders the applicability of Transformer for multi-speaker TTS. In this paper, we develop a robust and high-quality multi-speaker Transformer TTS system called MultiSpeech, with several specially designed components/techniques to improve text-to-speech alignment: 1) a diagonal constraint on the weight matrix of encoder-decoder attention in both training and inference; 2) layer normalization on phoneme embedding in encoder to better preserve position information; 3) a bottleneck in decoder pre-net to prevent copy between consecutive speech frames. Experiments on VCTK and LibriTTS multi-speaker datasets demonstrate the effectiveness of MultiSpeech: 1) it synthesizes more robust and better quality multi-speaker voice than naive Transformer based TTS; 2) with a MutiSpeech model as the teacher, we obtain a strong multi-speaker FastSpeech model with almost zero quality degradation while enjoying extremely fast inference speed.
Hybrid Channel Based Pedestrian Detection
Jan 30, 2020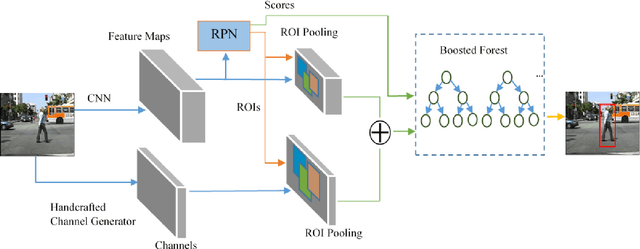



Pedestrian detection has achieved great improvements with the help of Convolutional Neural Networks (CNNs). CNN can learn high-level features from input images, but the insufficient spatial resolution of CNN feature channels (feature maps) may cause a loss of information, which is harmful especially to small instances. In this paper, we propose a new pedestrian detection framework, which extends the successful RPN+BF framework to combine handcrafted features and CNN features. RoI-pooling is used to extract features from both handcrafted channels (e.g. HOG+LUV, CheckerBoards or RotatedFilters) and CNN channels. Since handcrafted channels always have higher spatial resolution than CNN channels, we apply RoI-pooling with larger output resolution to handcrafted channels to keep more detailed information. Our ablation experiments show that the developed handcrafted features can reach better detection accuracy than the CNN features extracted from the VGG-16 net, and a performance gain can be achieved by combining them. Experimental results on Caltech pedestrian dataset with the original annotations and the improved annotations demonstrate the effectiveness of the proposed approach. When using a more advanced RPN in our framework, our approach can be further improved and get competitive results on both benchmarks.
AirwayNet: A Voxel-Connectivity Aware Approach for Accurate Airway Segmentation Using Convolutional Neural Networks
Jul 16, 2019
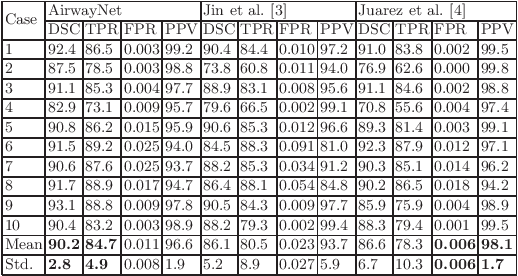
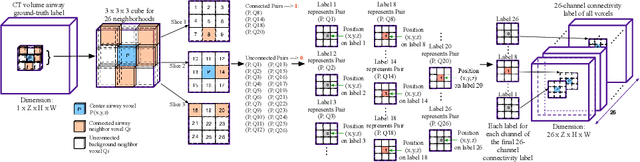
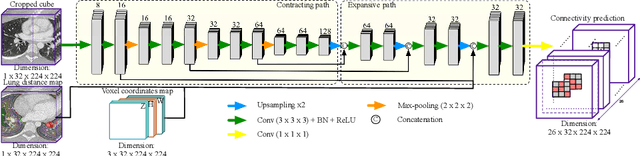
Airway segmentation on CT scans is critical for pulmonary disease diagnosis and endobronchial navigation. Manual extraction of airway requires strenuous efforts due to the complicated structure and various appearance of airway. For automatic airway extraction, convolutional neural networks (CNNs) based methods have recently become the state-of-the-art approach. However, there still remains a challenge for CNNs to perceive the tree-like pattern and comprehend the connectivity of airway. To address this, we propose a voxel-connectivity aware approach named AirwayNet for accurate airway segmentation. By connectivity modeling, conventional binary segmentation task is transformed into 26 tasks of connectivity prediction. Thus, our AirwayNet learns both airway structure and relationship between neighboring voxels. To take advantage of context knowledge, lung distance map and voxel coordinates are fed into AirwayNet as additional semantic information. Compared to existing approaches, AirwayNet achieved superior performance, demonstrating the effectiveness of the network's awareness of voxel connectivity.