 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESP-MedSAM: Efficient Self-Prompting SAM for Universal Domain-Generalized Medical Image Segmentation
Jul 19, 2024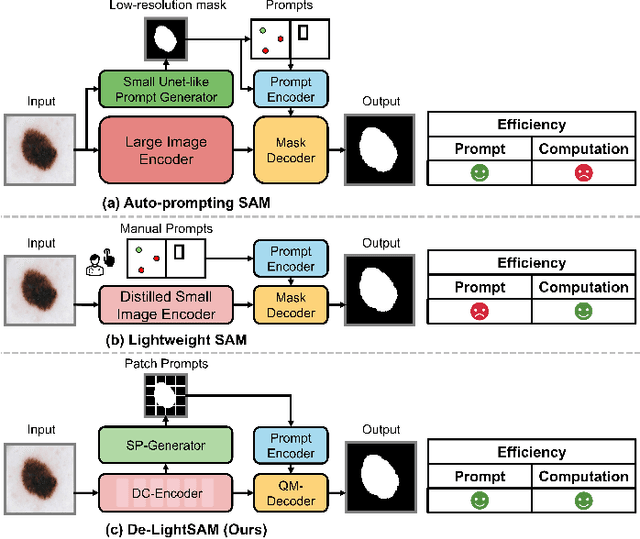
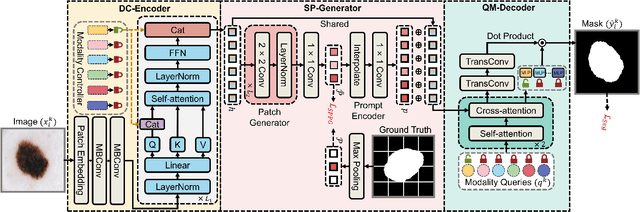
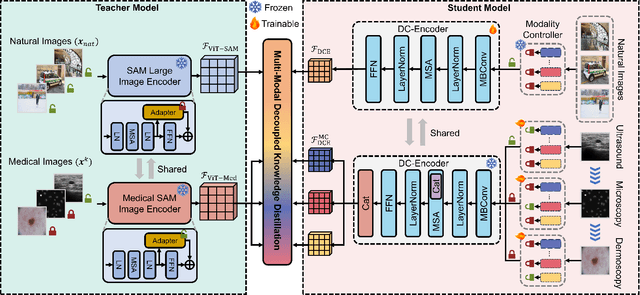
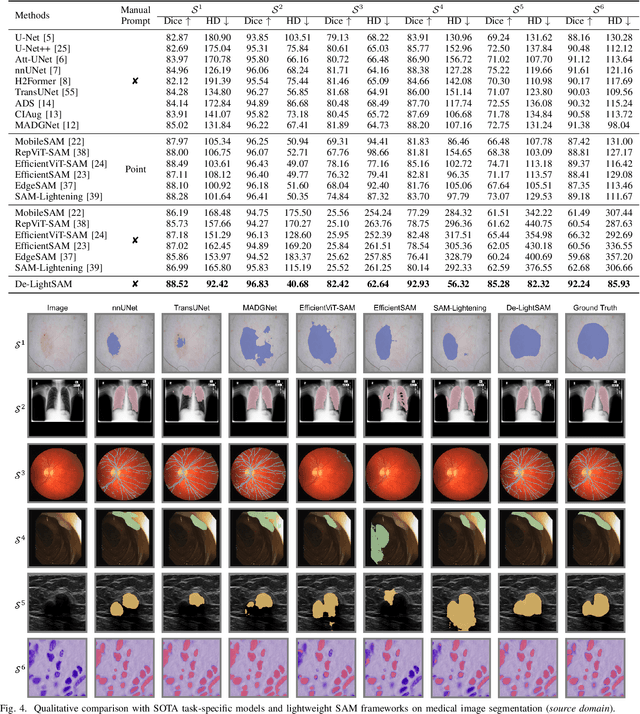
The Segment Anything Model (SAM) has demonstrated outstanding adaptation to medical image segmentation but still faces three major challenges. Firstly, the huge computational costs of SAM limit its real-world applicability. Secondly, SAM depends on manual annotations (e.g., points, boxes) as prompts, which are laborious and impractical in clinical scenarios. Thirdly, SAM handles all segmentation targets equally, which is suboptimal for diverse medical modalities with inherent heterogeneity. To address these issues, we propose an Efficient Self-Prompting SAM for universal medical image segmentation, named ESP-MedSAM. We devise a Multi-Modal Decoupled Knowledge Distillation (MMDKD) strategy to distil common image knowledge and domain-specific medical knowledge from the foundation model to train a lightweight image encoder and a modality controller. Further, they combine with the additionally introduced Self-Patch Prompt Generator (SPPG) and Query-Decoupled Modality Decoder (QDMD) to construct ESP-MedSAM. Specifically, SPPG aims to generate a set of patch prompts automatically and QDMD leverages a one-to-one strategy to provide an independent decoding channel for every modality. Extensive experiments indicate that ESP-MedSAM outperforms state-of-the-arts in diverse medical imaging segmentation takes, displaying superior zero-shot learning and modality transfer ability. Especially, our framework uses only 31.4% parameters compared to SAM-Base.
End-To-End Audiovisual Feature Fusion for Active Speaker Detection
Jul 27, 2022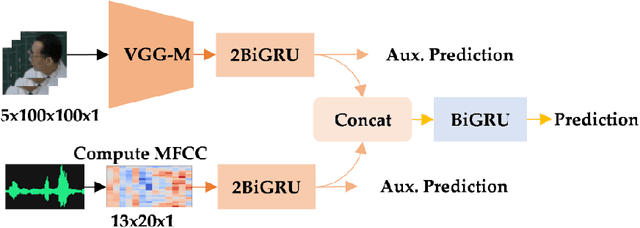
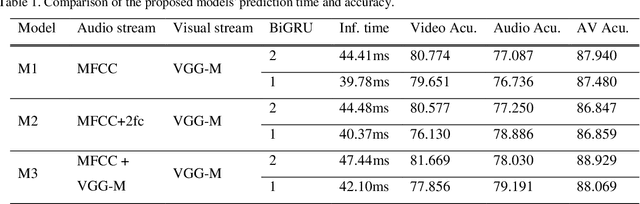
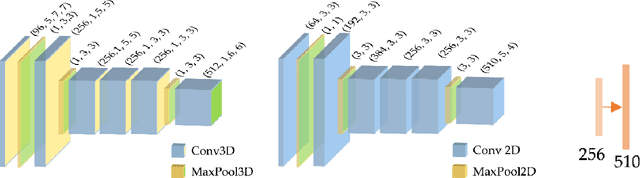

Active speaker detection plays a vital role in human-machine interaction. Recently, a few end-to-end audiovisual frameworks emerged. However, these models' inference time was not explored and are not applicable for real-time applications due to their complexity and large input size. In addition, they explored a similar feature extraction strategy that employs the ConvNet on audio and visual inputs. This work presents a novel two-stream end-to-end framework fusing features extracted from images via VGG-M with raw Mel Frequency Cepstrum Coefficients features extracted from the audio waveform. The network has two BiGRU layers attached to each stream to handle each stream's temporal dynamic before fusion. After fusion, one BiGRU layer is attached to model the joint temporal dynamics. The experiment result on the AVA-ActiveSpeaker dataset indicates that our new feature extraction strategy shows more robustness to noisy signals and better inference time than models that employed ConvNet on both modalities. The proposed model predicts within 44.41 ms, which is fast enough for real-time applications. Our best-performing model attained 88.929% accuracy, nearly the same detection result as state-of-the-art -work.
Hybrid Channel Based Pedestrian Detection
Jan 30, 2020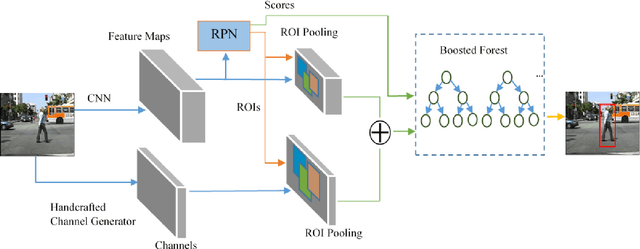



Pedestrian detection has achieved great improvements with the help of Convolutional Neural Networks (CNNs). CNN can learn high-level features from input images, but the insufficient spatial resolution of CNN feature channels (feature maps) may cause a loss of information, which is harmful especially to small instances. In this paper, we propose a new pedestrian detection framework, which extends the successful RPN+BF framework to combine handcrafted features and CNN features. RoI-pooling is used to extract features from both handcrafted channels (e.g. HOG+LUV, CheckerBoards or RotatedFilters) and CNN channels. Since handcrafted channels always have higher spatial resolution than CNN channels, we apply RoI-pooling with larger output resolution to handcrafted channels to keep more detailed information. Our ablation experiments show that the developed handcrafted features can reach better detection accuracy than the CNN features extracted from the VGG-16 net, and a performance gain can be achieved by combining them. Experimental results on Caltech pedestrian dataset with the original annotations and the improved annotations demonstrate the effectiveness of the proposed approach. When using a more advanced RPN in our framework, our approach can be further improved and get competitive results on both benchmarks.