 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Knowledge Graph with Visual Perception for Object-goal Navigation
Feb 29, 2024Object-goal navigation is a challenging task that requires guiding an agent to specific objects based on first-person visual observations. The ability of agent to comprehend its surroundings plays a crucial role in achieving successful object finding. However, existing knowledge-graph-based navigators often rely on discrete categorical one-hot vectors and vote counting strategy to construct graph representation of the scenes, which results in misalignment with visual images. To provide more accurate and coherent scene descriptions and address this misalignment issue, we propose the Aligning Knowledge Graph with Visual Perception (AKGVP) method for object-goal navigation. Technically, our approach introduces continuous modeling of the hierarchical scene architecture and leverages visual-language pre-training to align natural language description with visual perception. The integration of a continuous knowledge graph architecture and multimodal feature alignment empowers the navigator with a remarkable zero-shot navigation capability. We extensively evaluate our method using the AI2-THOR simulator and conduct a series of experiments to demonstrate the effectiveness and efficiency of our navigator. Code available: https://github.com/nuoxu/AKGVP.
End-To-End Audiovisual Feature Fusion for Active Speaker Detection
Jul 27, 2022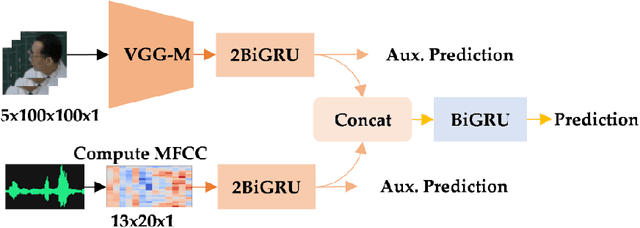
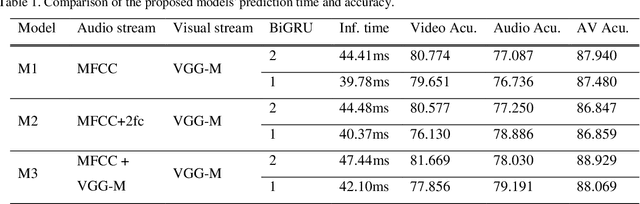
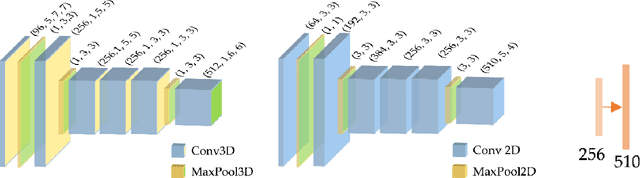

Active speaker detection plays a vital role in human-machine interaction. Recently, a few end-to-end audiovisual frameworks emerged. However, these models' inference time was not explored and are not applicable for real-time applications due to their complexity and large input size. In addition, they explored a similar feature extraction strategy that employs the ConvNet on audio and visual inputs. This work presents a novel two-stream end-to-end framework fusing features extracted from images via VGG-M with raw Mel Frequency Cepstrum Coefficients features extracted from the audio waveform. The network has two BiGRU layers attached to each stream to handle each stream's temporal dynamic before fusion. After fusion, one BiGRU layer is attached to model the joint temporal dynamics. The experiment result on the AVA-ActiveSpeaker dataset indicates that our new feature extraction strategy shows more robustness to noisy signals and better inference time than models that employed ConvNet on both modalities. The proposed model predicts within 44.41 ms, which is fast enough for real-time applications. Our best-performing model attained 88.929% accuracy, nearly the same detection result as state-of-the-art -work.
TGRMPT: A Head-Shoulder Aided Multi-Person Tracker and a New Large-Scale Dataset for Tour-Guide Robot
Jul 08, 2022

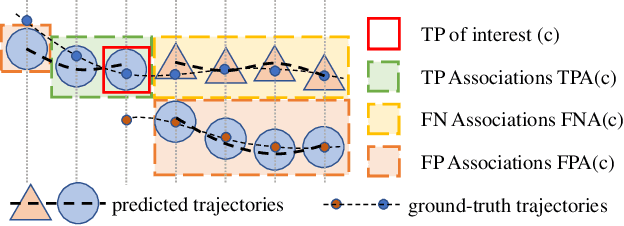
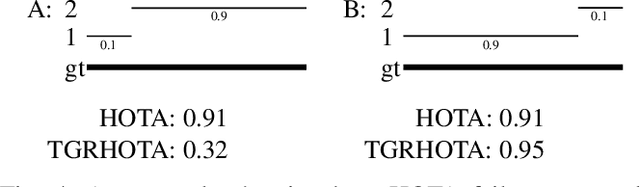
A service robot serving safely and politely needs to track the surrounding people robustly, especially for Tour-Guide Robot (TGR). However, existing multi-object tracking (MOT) or multi-person tracking (MPT) methods are not applicable to TGR for the following reasons: 1. lacking relevant large-scale datasets; 2. lacking applicable metrics to evaluate trackers. In this work, we target the visual perceptual tasks for TGR and present the TGRDB dataset, a novel large-scale multi-person tracking dataset containing roughly 5.6 hours of annotated videos and over 450 long-term trajectories. Besides, we propose a more applicable metric to evaluate trackers using our dataset. As part of our work, we present TGRMPT, a novel MPT system that incorporates information from head shoulder and whole body, and achieves state-of-the-art performance. We have released our codes and dataset in https://github.com/wenwenzju/TGRMPT.