 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometrical portrait of Multipath error propagation in GNSS Direct Position Estimation
Jul 24, 2025Direct Position Estimation (DPE) is a method that directly estimate position, velocity, and time (PVT) information from cross ambiguity function (CAF) of the GNSS signals, significantly enhancing receiver robustness in urban environments. However, there is still a lack of theoretical characterization on multipath errors in the context of DPE theory. Geometric observations highlight the unique characteristics of DPE errors stemming from multipath and thermal noise as estimation bias and variance respectively. Expanding upon the theoretical framework of DPE noise variance through geometric analysis, this paper focuses on a geometric representation of multipath errors by quantifying the deviations in CAF and PVT solutions caused by off-centering bias relative to the azimuth and elevation angles. A satellite circular multipath bias (SCMB) model is introduced, amalgamating CAF and PVT errors from multiple satellite channels. The boundaries for maximum or minimum PVT bias are established through discussions encompassing various multipath conditions. The correctness of the multipath geometrical portrait is confirmed through both Monte Carlo simulations and urban canyon tests. The findings indicate that the maximum PVT bias depends on the largest multipath errors observed across various satellite channels. Additionally, the PVT bias increases with satellite elevation angles, influenced by the CAF multipath bias projection. This serves as a reference for selecting DPE satellites from a geometric standpoint, underscoring the importance of choosing a balanced combination of high and low elevation angles to achieve an optimal satellite geometry configuration.
Falcon: A Remote Sensing Vision-Language Foundation Model
Mar 14, 2025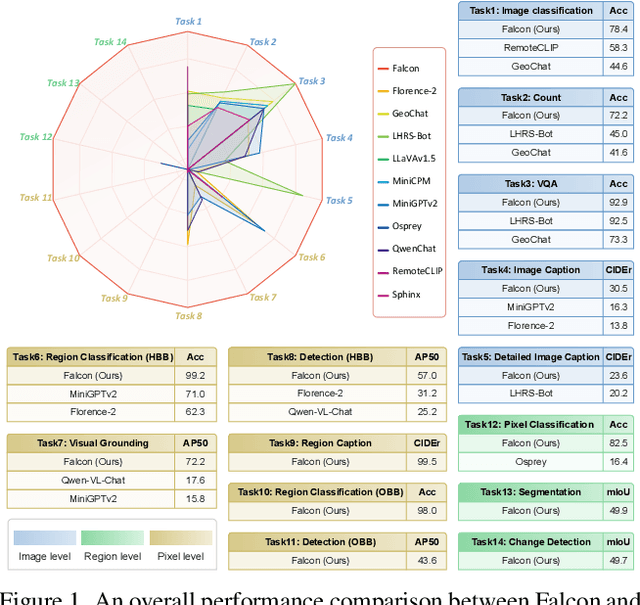

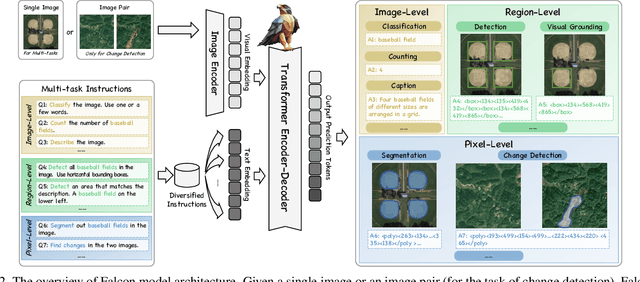
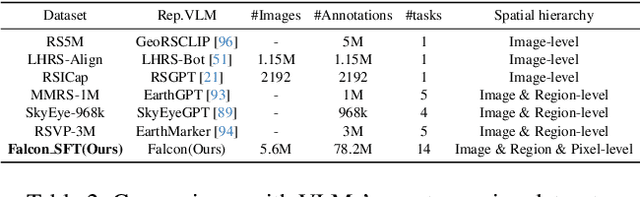
This paper introduces a holistic vision-language foundation model tailored for remote sensing, named Falcon. Falcon offers a unified, prompt-based paradigm that effectively executes comprehensive and complex remote sensing tasks. Falcon demonstrates powerful understanding and reasoning abilities at the image, region, and pixel levels. Specifically, given simple natural language instructions and remote sensing images, Falcon can produce impressive results in text form across 14 distinct tasks, i.e., image classification, object detection, segmentation, image captioning, and etc. To facilitate Falcon's training and empower its representation capacity to encode rich spatial and semantic information, we developed Falcon_SFT, a large-scale, multi-task, instruction-tuning dataset in the field of remote sensing. The Falcon_SFT dataset consists of approximately 78 million high-quality data samples, covering 5.6 million multi-spatial resolution and multi-view remote sensing images with diverse instructions. It features hierarchical annotations and undergoes manual sampling verification to ensure high data quality and reliability. Extensive comparative experiments are conducted, which verify that Falcon achieves remarkable performance over 67 datasets and 14 tasks, despite having only 0.7B parameters. We release the complete dataset, code, and model weights at https://github.com/TianHuiLab/Falcon, hoping to help further develop the open-source community.
Aligning Knowledge Graph with Visual Perception for Object-goal Navigation
Feb 29, 2024Object-goal navigation is a challenging task that requires guiding an agent to specific objects based on first-person visual observations. The ability of agent to comprehend its surroundings plays a crucial role in achieving successful object finding. However, existing knowledge-graph-based navigators often rely on discrete categorical one-hot vectors and vote counting strategy to construct graph representation of the scenes, which results in misalignment with visual images. To provide more accurate and coherent scene descriptions and address this misalignment issue, we propose the Aligning Knowledge Graph with Visual Perception (AKGVP) method for object-goal navigation. Technically, our approach introduces continuous modeling of the hierarchical scene architecture and leverages visual-language pre-training to align natural language description with visual perception. The integration of a continuous knowledge graph architecture and multimodal feature alignment empowers the navigator with a remarkable zero-shot navigation capability. We extensively evaluate our method using the AI2-THOR simulator and conduct a series of experiments to demonstrate the effectiveness and efficiency of our navigator. Code available: https://github.com/nuoxu/AKGVP.