 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSX-Stitch: An Efficient VMS-UNet Based Framework for Intraoperative Scoliosis X-Ray Image Stitching
Sep 09, 2024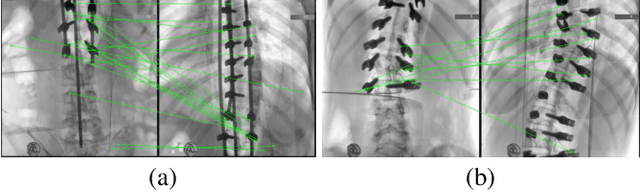
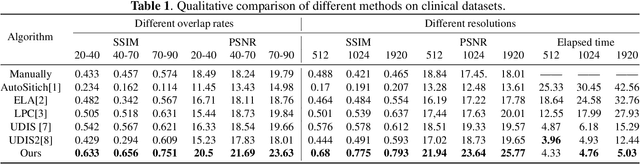
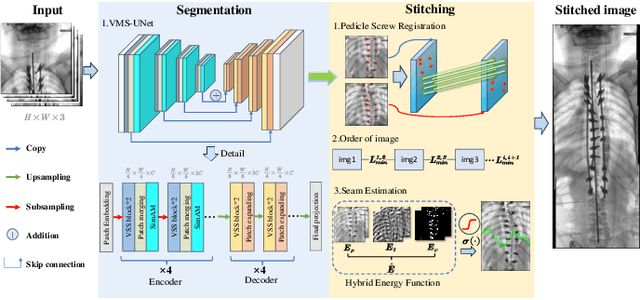
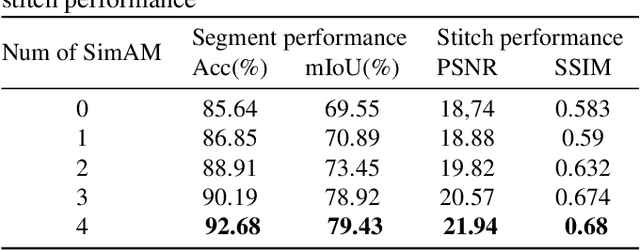
In scoliosis surgery, the limited field of view of the C-arm X-ray machine restricts the surgeons' holistic analysis of spinal structures .This paper presents an end-to-end efficient and robust intraoperative X-ray image stitching method for scoliosis surgery,named SX-Stitch. The method is divided into two stages:segmentation and stitching. In the segmentation stage, We propose a medical image segmentation model named Vision Mamba of Spine-UNet (VMS-UNet), which utilizes the state space Mamba to capture long-distance contextual information while maintaining linear computational complexity, and incorporates the SimAM attention mechanism, significantly improving the segmentation performance.In the stitching stage, we simplify the alignment process between images to the minimization of a registration energy function. The total energy function is then optimized to order unordered images, and a hybrid energy function is introduced to optimize the best seam, effectively eliminating parallax artifacts. On the clinical dataset, Sx-Stitch demonstrates superiority over SOTA schemes both qualitatively and quantitatively.
Aligning Knowledge Graph with Visual Perception for Object-goal Navigation
Feb 29, 2024Object-goal navigation is a challenging task that requires guiding an agent to specific objects based on first-person visual observations. The ability of agent to comprehend its surroundings plays a crucial role in achieving successful object finding. However, existing knowledge-graph-based navigators often rely on discrete categorical one-hot vectors and vote counting strategy to construct graph representation of the scenes, which results in misalignment with visual images. To provide more accurate and coherent scene descriptions and address this misalignment issue, we propose the Aligning Knowledge Graph with Visual Perception (AKGVP) method for object-goal navigation. Technically, our approach introduces continuous modeling of the hierarchical scene architecture and leverages visual-language pre-training to align natural language description with visual perception. The integration of a continuous knowledge graph architecture and multimodal feature alignment empowers the navigator with a remarkable zero-shot navigation capability. We extensively evaluate our method using the AI2-THOR simulator and conduct a series of experiments to demonstrate the effectiveness and efficiency of our navigator. Code available: https://github.com/nuoxu/AKGVP.
Memory-Constrained Semantic Segmentation for Ultra-High Resolution UAV Imagery
Oct 07, 2023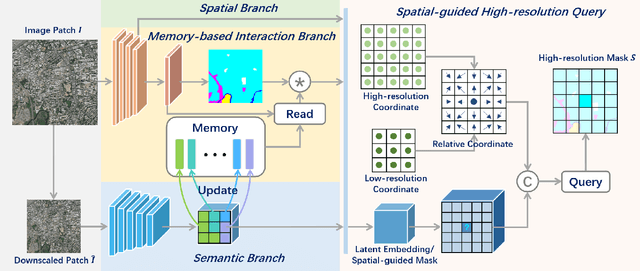
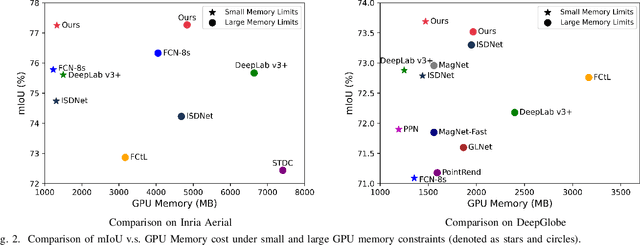
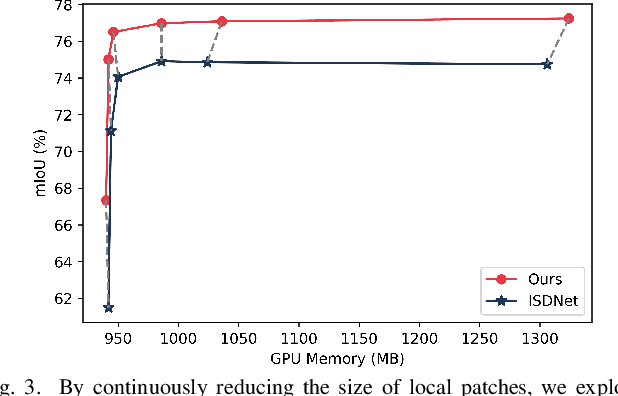

Amidst the swift advancements in photography and sensor technologies, high-definition cameras have become commonplace in the deployment of Unmanned Aerial Vehicles (UAVs) for diverse operational purposes. Within the domain of UAV imagery analysis, the segmentation of ultra-high resolution images emerges as a substantial and intricate challenge, especially when grappling with the constraints imposed by GPU memory-restricted computational devices. This paper delves into the intricate problem of achieving efficient and effective segmentation of ultra-high resolution UAV imagery, while operating under stringent GPU memory limitation. The strategy of existing approaches is to downscale the images to achieve computationally efficient segmentation. However, this strategy tends to overlook smaller, thinner, and curvilinear regions. To address this problem, we propose a GPU memory-efficient and effective framework for local inference without accessing the context beyond local patches. In particular, we introduce a novel spatial-guided high-resolution query module, which predicts pixel-wise segmentation results with high quality only by querying nearest latent embeddings with the guidance of high-resolution information. Additionally, we present an efficient memory-based interaction scheme to correct potential semantic bias of the underlying high-resolution information by associating cross-image contextual semantics. For evaluation of our approach, we perform comprehensive experiments over public benchmarks and achieve superior performance under both conditions of small and large GPU memory usage limitations. We will release the model and codes in the future.
Subtractor-Based CNN Inference Accelerator
Oct 02, 2023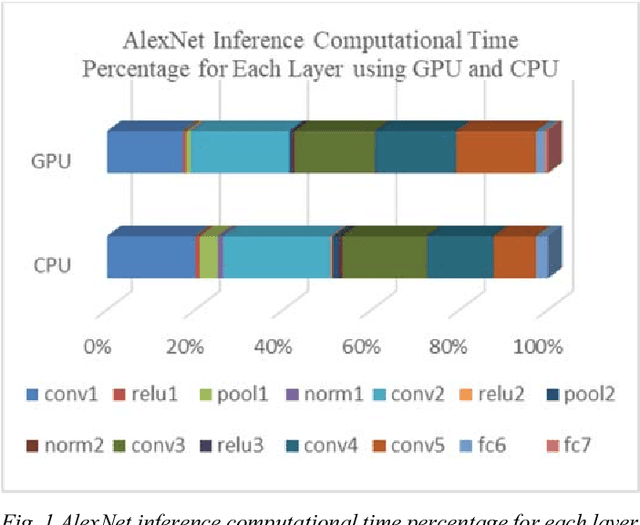
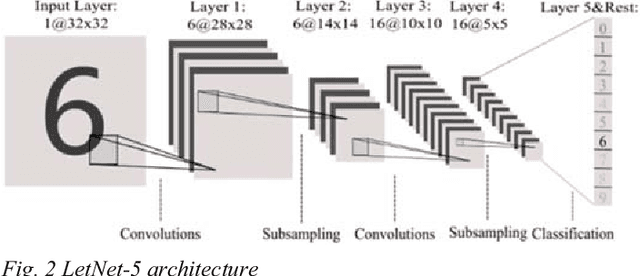
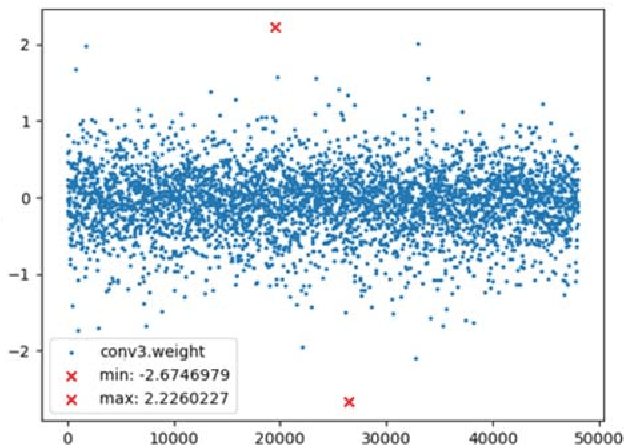
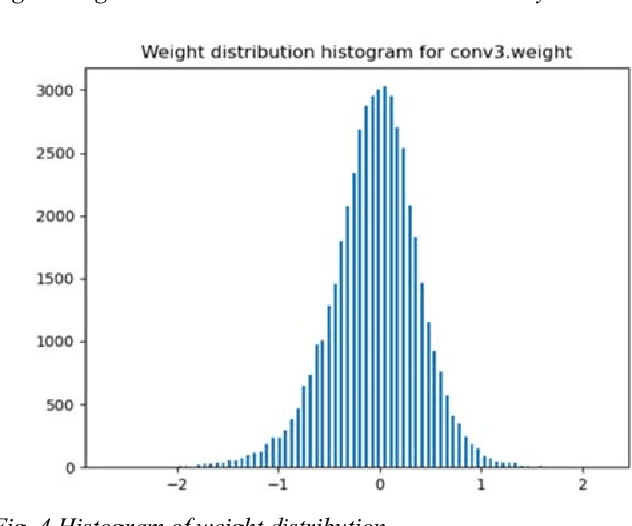
This paper presents a novel method to boost the performance of CNN inference accelerators by utilizing subtractors. The proposed CNN preprocessing accelerator relies on sorting, grouping, and rounding the weights to create combinations that allow for the replacement of one multiplication operation and addition operation by a single subtraction operation when applying convolution during inference. Given the high cost of multiplication in terms of power and area, replacing it with subtraction allows for a performance boost by reducing power and area. The proposed method allows for controlling the trade-off between performance gains and accuracy loss through increasing or decreasing the usage of subtractors. With a rounding size of 0.05 and by utilizing LeNet-5 with the MNIST dataset, the proposed design can achieve 32.03% power savings and a 24.59% reduction in area at the cost of only 0.1% in terms of accuracy loss.
End-To-End Audiovisual Feature Fusion for Active Speaker Detection
Jul 27, 2022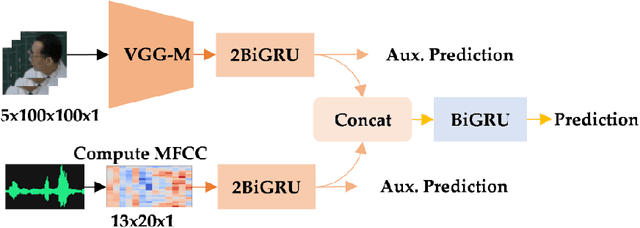
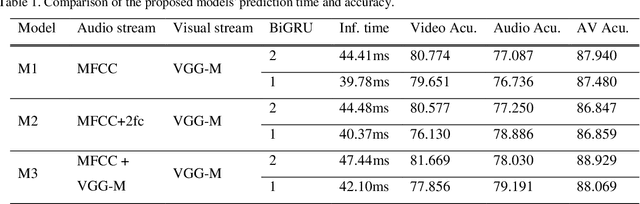
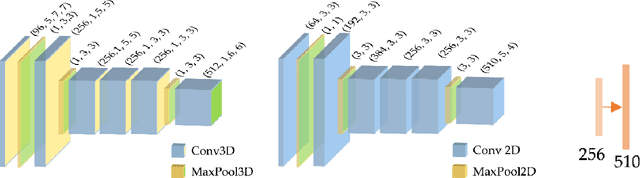

Active speaker detection plays a vital role in human-machine interaction. Recently, a few end-to-end audiovisual frameworks emerged. However, these models' inference time was not explored and are not applicable for real-time applications due to their complexity and large input size. In addition, they explored a similar feature extraction strategy that employs the ConvNet on audio and visual inputs. This work presents a novel two-stream end-to-end framework fusing features extracted from images via VGG-M with raw Mel Frequency Cepstrum Coefficients features extracted from the audio waveform. The network has two BiGRU layers attached to each stream to handle each stream's temporal dynamic before fusion. After fusion, one BiGRU layer is attached to model the joint temporal dynamics. The experiment result on the AVA-ActiveSpeaker dataset indicates that our new feature extraction strategy shows more robustness to noisy signals and better inference time than models that employed ConvNet on both modalities. The proposed model predicts within 44.41 ms, which is fast enough for real-time applications. Our best-performing model attained 88.929% accuracy, nearly the same detection result as state-of-the-art -work.
BCOT: A Markerless High-Precision 3D Object Tracking Benchmark
Mar 25, 2022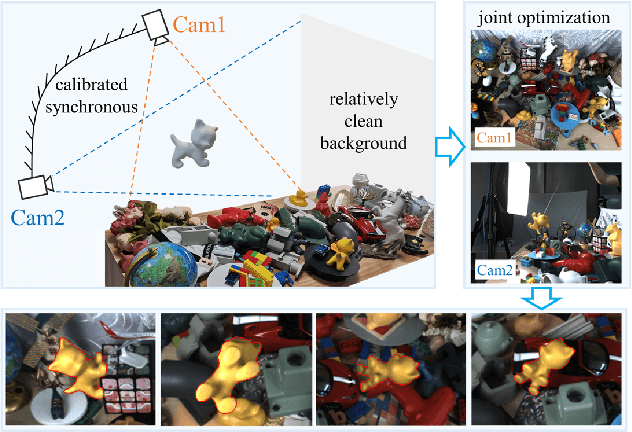
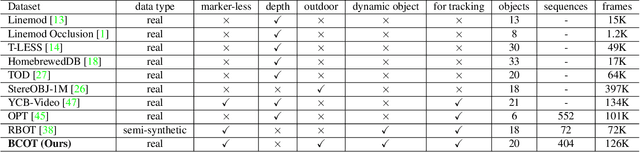


Template-based 3D object tracking still lacks a high-precision benchmark of real scenes due to the difficulty of annotating the accurate 3D poses of real moving video objects without using markers. In this paper, we present a multi-view approach to estimate the accurate 3D poses of real moving objects, and then use binocular data to construct a new benchmark for monocular textureless 3D object tracking. The proposed method requires no markers, and the cameras only need to be synchronous, relatively fixed as cross-view and calibrated. Based on our object-centered model, we jointly optimize the object pose by minimizing shape re-projection constraints in all views, which greatly improves the accuracy compared with the single-view approach, and is even more accurate than the depth-based method. Our new benchmark dataset contains 20 textureless objects, 22 scenes, 404 video sequences and 126K images captured in real scenes. The annotation error is guaranteed to be less than 2mm, according to both theoretical analysis and validation experiments. We re-evaluate the state-of-the-art 3D object tracking methods with our dataset, reporting their performance ranking in real scenes. Our BCOT benchmark and code can be found at https://ar3dv.github.io/BCOT-Benchmark/.
A Multi-Behavior Planning Framework for Robot Guide
Jan 07, 2022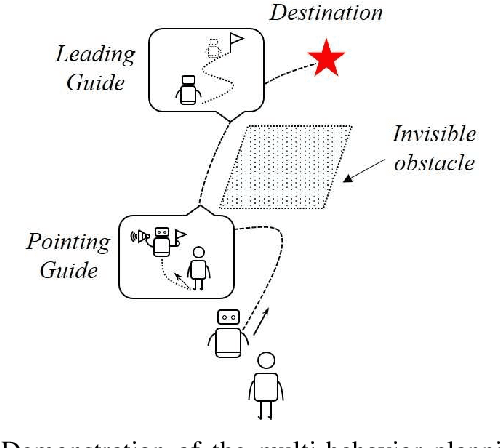
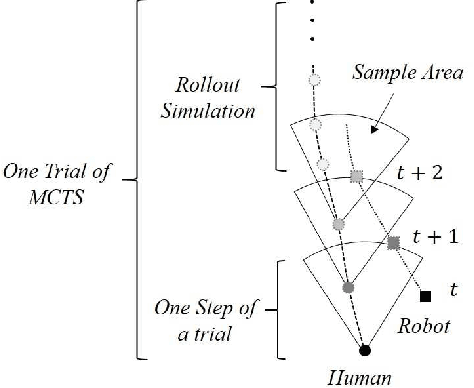
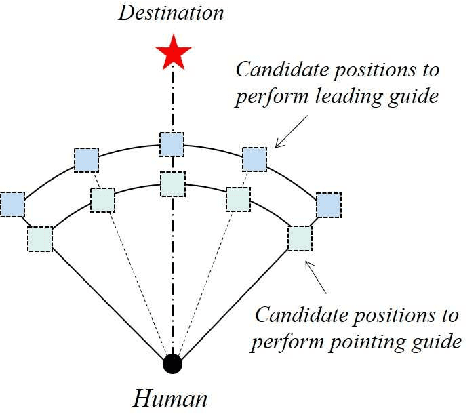
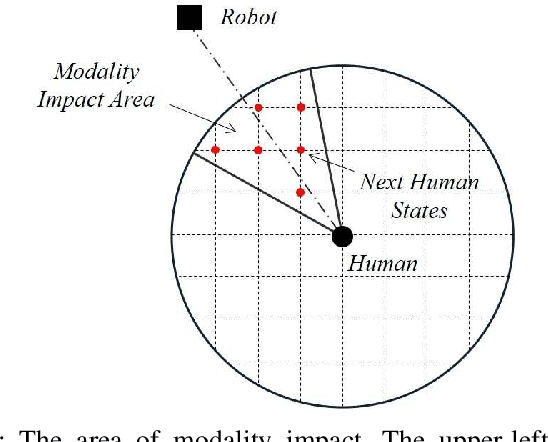
The guiding task of a mobile robot requires not only human-aware navigation, but also appropriate yet timely interaction for active instruction. State-of-the-art tour-guide models limit their socially-aware consideration to adapting to users' motion, ignoring the interactive behavior planning to fulfill the communicative demands. We propose a multi-behavior planning framework based on Monte Carlo Tree Search to better assist users to understand confusing scene contexts, select proper paths and timely arrive at the destination. To provide proactive guidance, we construct a sampling-based probability model of human motion to consider the interrelated effects between robots and humans. We validate our method both in simulation and real-world experiments along with performance comparison with state-of-the-art models.
RSI-Net: Two-Stream Deep Neural Network Integrating GCN and Atrous CNN for Semantic Segmentation of High-resolution Remote Sensing Images
Sep 19, 2021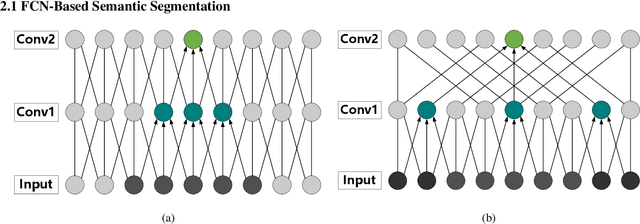
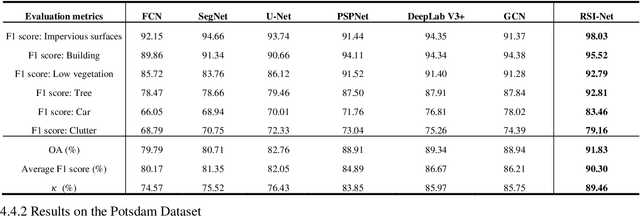
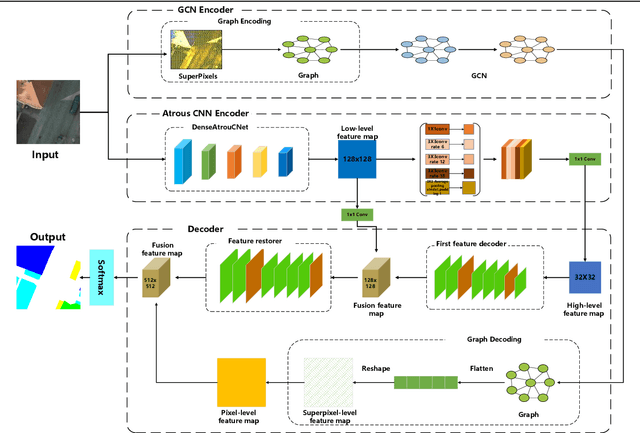
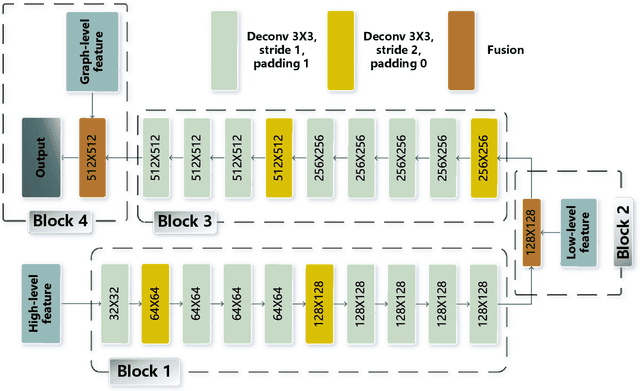
For semantic segmentation of remote sensing images (RSI), trade-off between representation power and location accuracy is quite important. How to get the trade-off effectively is an open question, where current approaches of utilizing attention schemes or very deep models result in complex models with large memory consumption. Compared with the popularly-used convolutional neural network (CNN) with fixed square kernels, graph convolutional network (GCN) can explicitly utilize correlations between adjacent land covers and conduct flexible convolution on arbitrarily irregular image regions. However, the problems of large variations of target scales and blurred boundary cannot be easily solved by GCN, while densely connected atrous convolution network (DenseAtrousCNet) with multi-scale atrous convolution can expand the receptive fields and obtain image global information. Inspired by the advantages of both GCN and Atrous CNN, a two-stream deep neural network for semantic segmentation of RSI (RSI-Net) is proposed in this paper to obtain improved performance through modeling and propagating spatial contextual structure effectively and a novel decoding scheme with image-level and graph-level combination. Extensive experiments are implemented on the Vaihingen, Potsdam and Gaofen RSI datasets, where the comparison results demonstrate the superior performance of RSI-Net in terms of overall accuracy, F1 score and kappa coefficient when compared with six state-of-the-art RSI semantic segmentation methods.
A Comparative Study on Machine Learning Algorithms for the Control of a Wall Following Robot
Dec 26, 2019



A comparison of the performance of various machine learning models to predict the direction of a wall following robot is presented in this paper. The models were trained using an open-source dataset that contains 24 ultrasound sensors readings and the corresponding direction for each sample. This dataset was captured using SCITOS G5 mobile robot by placing the sensors on the robot waist. In addition to the full format with 24 sensors per record, the dataset has two simplified formats with 4 and 2 input sensor readings per record. Several control models were proposed previously for this dataset using all three dataset formats. In this paper, two primary research contributions are presented. First, presenting machine learning models with accuracies higher than all previously proposed models for this dataset using all three formats. A perfect solution for the 4 and 2 inputs sensors formats is presented using Decision Tree Classifier by achieving a mean accuracy of 100%. On the other hand, a mean accuracy of 99.82% was achieves using the 24 sensor inputs by employing the Gradient Boost Classifier. Second, presenting a comparative study on the performance of different machine learning and deep learning algorithms on this dataset. Therefore, providing an overall insight on the performance of these algorithms for similar sensor fusion problems. All the models in this paper were evaluated using Monte-Carlo cross-validation.
Deep Learning Training with Simulated Approximate Multipliers
Dec 26, 2019



This paper presents by simulation how approximate multipliers can be utilized to enhance the training performance of convolutional neural networks (CNNs). Approximate multipliers have significantly better performance in terms of speed, power, and area compared to exact multipliers. However, approximate multipliers have an inaccuracy which is defined in terms of the Mean Relative Error (MRE). To assess the applicability of approximate multipliers in enhancing CNN training performance, a simulation for the impact of approximate multipliers error on CNN training is presented. The paper demonstrates that using approximate multipliers for CNN training can significantly enhance the performance in terms of speed, power, and area at the cost of a small negative impact on the achieved accuracy. Additionally, the paper proposes a hybrid training method which mitigates this negative impact on the accuracy. Using the proposed hybrid method, the training can start using approximate multipliers then switches to exact multipliers for the last few epochs. Using this method, the performance benefits of approximate multipliers in terms of speed, power, and area can be attained for a large portion of the training stage. On the other hand, the negative impact on the accuracy is diminished by using the exact multipliers for the last epochs of training.