 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBCOT: A Markerless High-Precision 3D Object Tracking Benchmark
Paper and Code
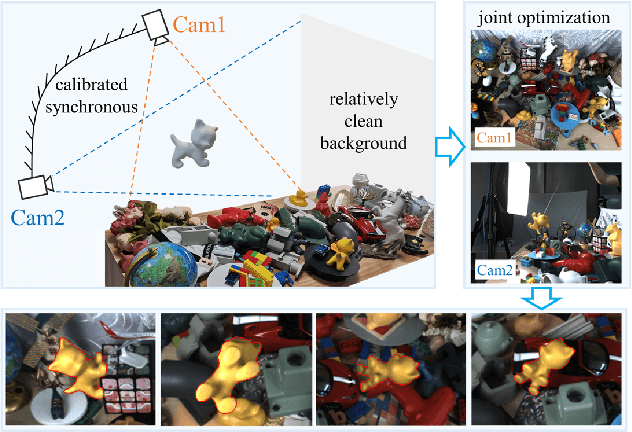
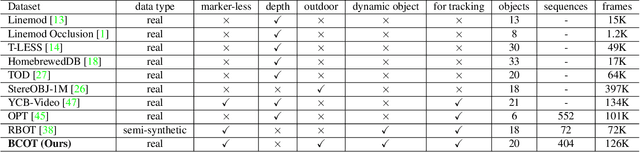


Template-based 3D object tracking still lacks a high-precision benchmark of real scenes due to the difficulty of annotating the accurate 3D poses of real moving video objects without using markers. In this paper, we present a multi-view approach to estimate the accurate 3D poses of real moving objects, and then use binocular data to construct a new benchmark for monocular textureless 3D object tracking. The proposed method requires no markers, and the cameras only need to be synchronous, relatively fixed as cross-view and calibrated. Based on our object-centered model, we jointly optimize the object pose by minimizing shape re-projection constraints in all views, which greatly improves the accuracy compared with the single-view approach, and is even more accurate than the depth-based method. Our new benchmark dataset contains 20 textureless objects, 22 scenes, 404 video sequences and 126K images captured in real scenes. The annotation error is guaranteed to be less than 2mm, according to both theoretical analysis and validation experiments. We re-evaluate the state-of-the-art 3D object tracking methods with our dataset, reporting their performance ranking in real scenes. Our BCOT benchmark and code can be found at https://ar3dv.github.io/BCOT-Benchmark/.