 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHALO:Closing Sim-to-Real Gap for Heavy-loaded Humanoid Agile Motion Skills via Differentiable Simulation
Mar 16, 2026Humanoid robots deployed in real-world scenarios often need to carry unknown payloads, which introduce significant mismatch and degrade the effectiveness of simulation-to-reality reinforcement learning methods. To address this challenge, we propose a two-stage gradient-based system identification framework built on the differentiable simulator MuJoCo XLA. The first stage calibrates the nominal robot model using real-world data to reduce intrinsic sim-to-real discrepancies, while the second stage further identifies the mass distribution of the unknown payload. By explicitly reducing structured model bias prior to policy training, our approach enables zero-shot transfer of reinforcement learning policies to hardware under heavy-load conditions. Extensive simulation and real-world experiments demonstrate more precise parameter identification, improved motion tracking accuracy, and substantially enhanced agility and robustness compared to existing baselines. Project Page: https://mwondering.github.io/halo-humanoid/
Intelligent Computing: The Latest Advances, Challenges and Future
Nov 21, 2022Computing is a critical driving force in the development of human civilization. In recent years, we have witnessed the emergence of intelligent computing, a new computing paradigm that is reshaping traditional computing and promoting digital revolution in the era of big data, artificial intelligence and internet-of-things with new computing theories, architectures, methods, systems, and applications. Intelligent computing has greatly broadened the scope of computing, extending it from traditional computing on data to increasingly diverse computing paradigms such as perceptual intelligence, cognitive intelligence, autonomous intelligence, and human-computer fusion intelligence. Intelligence and computing have undergone paths of different evolution and development for a long time but have become increasingly intertwined in recent years: intelligent computing is not only intelligence-oriented but also intelligence-driven. Such cross-fertilization has prompted the emergence and rapid advancement of intelligent computing. Intelligent computing is still in its infancy and an abundance of innovations in the theories, systems, and applications of intelligent computing are expected to occur soon. We present the first comprehensive survey of literature on intelligent computing, covering its theory fundamentals, the technological fusion of intelligence and computing, important applications, challenges, and future perspectives. We believe that this survey is highly timely and will provide a comprehensive reference and cast valuable insights into intelligent computing for academic and industrial researchers and practitioners.
End-To-End Audiovisual Feature Fusion for Active Speaker Detection
Jul 27, 2022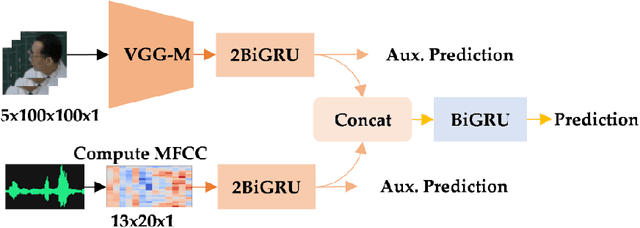
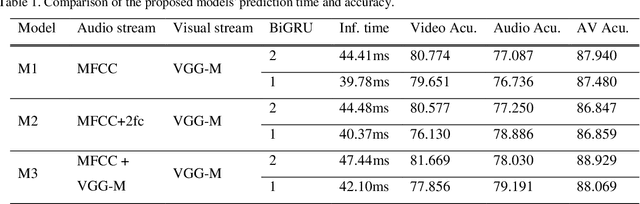
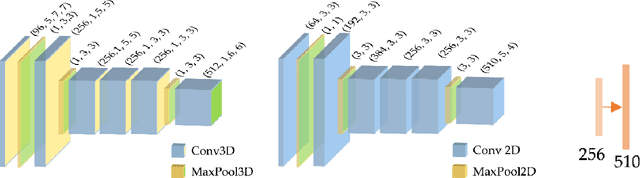

Active speaker detection plays a vital role in human-machine interaction. Recently, a few end-to-end audiovisual frameworks emerged. However, these models' inference time was not explored and are not applicable for real-time applications due to their complexity and large input size. In addition, they explored a similar feature extraction strategy that employs the ConvNet on audio and visual inputs. This work presents a novel two-stream end-to-end framework fusing features extracted from images via VGG-M with raw Mel Frequency Cepstrum Coefficients features extracted from the audio waveform. The network has two BiGRU layers attached to each stream to handle each stream's temporal dynamic before fusion. After fusion, one BiGRU layer is attached to model the joint temporal dynamics. The experiment result on the AVA-ActiveSpeaker dataset indicates that our new feature extraction strategy shows more robustness to noisy signals and better inference time than models that employed ConvNet on both modalities. The proposed model predicts within 44.41 ms, which is fast enough for real-time applications. Our best-performing model attained 88.929% accuracy, nearly the same detection result as state-of-the-art -work.
TGRMPT: A Head-Shoulder Aided Multi-Person Tracker and a New Large-Scale Dataset for Tour-Guide Robot
Jul 08, 2022

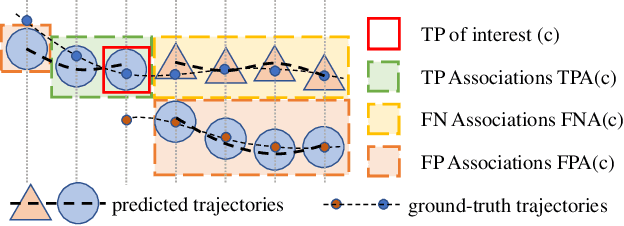
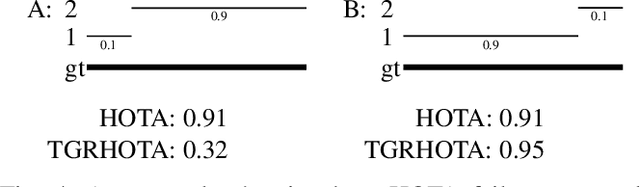
A service robot serving safely and politely needs to track the surrounding people robustly, especially for Tour-Guide Robot (TGR). However, existing multi-object tracking (MOT) or multi-person tracking (MPT) methods are not applicable to TGR for the following reasons: 1. lacking relevant large-scale datasets; 2. lacking applicable metrics to evaluate trackers. In this work, we target the visual perceptual tasks for TGR and present the TGRDB dataset, a novel large-scale multi-person tracking dataset containing roughly 5.6 hours of annotated videos and over 450 long-term trajectories. Besides, we propose a more applicable metric to evaluate trackers using our dataset. As part of our work, we present TGRMPT, a novel MPT system that incorporates information from head shoulder and whole body, and achieves state-of-the-art performance. We have released our codes and dataset in https://github.com/wenwenzju/TGRMPT.
BCOT: A Markerless High-Precision 3D Object Tracking Benchmark
Mar 25, 2022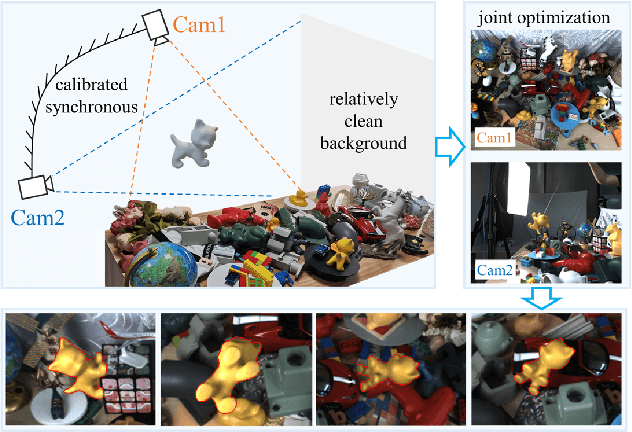
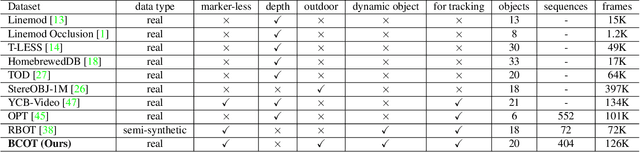


Template-based 3D object tracking still lacks a high-precision benchmark of real scenes due to the difficulty of annotating the accurate 3D poses of real moving video objects without using markers. In this paper, we present a multi-view approach to estimate the accurate 3D poses of real moving objects, and then use binocular data to construct a new benchmark for monocular textureless 3D object tracking. The proposed method requires no markers, and the cameras only need to be synchronous, relatively fixed as cross-view and calibrated. Based on our object-centered model, we jointly optimize the object pose by minimizing shape re-projection constraints in all views, which greatly improves the accuracy compared with the single-view approach, and is even more accurate than the depth-based method. Our new benchmark dataset contains 20 textureless objects, 22 scenes, 404 video sequences and 126K images captured in real scenes. The annotation error is guaranteed to be less than 2mm, according to both theoretical analysis and validation experiments. We re-evaluate the state-of-the-art 3D object tracking methods with our dataset, reporting their performance ranking in real scenes. Our BCOT benchmark and code can be found at https://ar3dv.github.io/BCOT-Benchmark/.
Dynamic DNN Decomposition for Lossless Synergistic Inference
Jan 15, 2021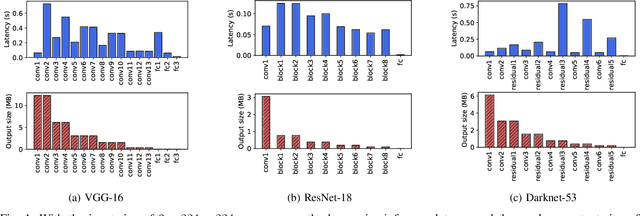


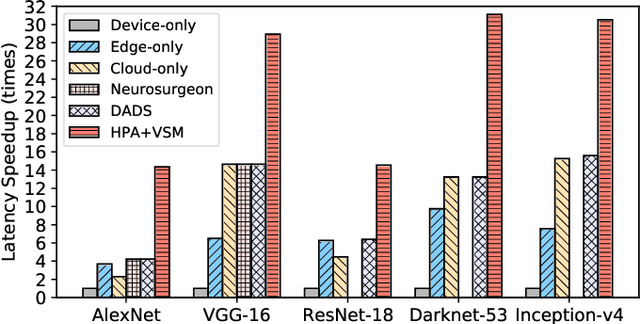
Deep neural networks (DNNs) sustain high performance in today's data processing applications. DNN inference is resource-intensive thus is difficult to fit into a mobile device. An alternative is to offload the DNN inference to a cloud server. However, such an approach requires heavy raw data transmission between the mobile device and the cloud server, which is not suitable for mission-critical and privacy-sensitive applications such as autopilot. To solve this problem, recent advances unleash DNN services using the edge computing paradigm. The existing approaches split a DNN into two parts and deploy the two partitions to computation nodes at two edge computing tiers. Nonetheless, these methods overlook collaborative device-edge-cloud computation resources. Besides, previous algorithms demand the whole DNN re-partitioning to adapt to computation resource changes and network dynamics. Moreover, for resource-demanding convolutional layers, prior works do not give a parallel processing strategy without loss of accuracy at the edge side. To tackle these issues, we propose D3, a dynamic DNN decomposition system for synergistic inference without precision loss. The proposed system introduces a heuristic algorithm named horizontal partition algorithm to split a DNN into three parts. The algorithm can partially adjust the partitions at run time according to processing time and network conditions. At the edge side, a vertical separation module separates feature maps into tiles that can be independently run on different edge nodes in parallel. Extensive quantitative evaluation of five popular DNNs illustrates that D3 outperforms the state-of-the-art counterparts up to 3.4 times in end-to-end DNN inference time and reduces backbone network communication overhead up to 3.68 times.