 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom UAV Imagery to Agronomic Reasoning: A Multimodal LLM Benchmark for Plant Phenotyping
Apr 10, 2026To improve crop genetics, high-throughput, effective and comprehensive phenotyping is a critical prerequisite. While such tasks were traditionally performed manually, recent advances in multimodal foundation models, especially in vision-language models (VLMs), have enabled more automated and robust phenotypic analysis. However, plant science remains a particularly challenging domain for foundation models because it requires domain-specific knowledge, fine-grained visual interpretation, and complex biological and agronomic reasoning. To address this gap, we develop PlantXpert, an evidence-grounded multimodal reasoning benchmark for soybean and cotton phenotyping. Our benchmark provides a structured and reproducible framework for agronomic adaptation of VLMs, and enables controlled comparison between base models and their domain-adapted counterparts. We constructed a dataset comprising 385 digital images and more than 3,000 benchmark samples spanning key plant science domains including disease, pest control, weed management, and yield. The benchmark can assess diverse capabilities including visual expertise, quantitative reasoning, and multi-step agronomic reasoning. A total of 11 state-of-the-art VLMs were evaluated. The results indicate that task-specific fine-tuning leads to substantial improvement in accuracy, with models such as Qwen3-VL-4B and Qwen3-VL-30B achieving up to 78%. At the same time, gains from model scaling diminish beyond a certain capacity, generalization across soybean and cotton remains uneven, and quantitative as well as biologically grounded reasoning continue to pose substantial challenges. These findings suggest that PlantXpert can serve as a foundation for assessing evidence-grounded agronomic reasoning and for advancing multimodal model development in plant science.
RePose: A Real-Time 3D Human Pose Estimation and Biomechanical Analysis Framework for Rehabilitation
Jan 02, 2026We propose a real-time 3D human pose estimation and motion analysis method termed RePose for rehabilitation training. It is capable of real-time monitoring and evaluation of patients'motion during rehabilitation, providing immediate feedback and guidance to assist patients in executing rehabilitation exercises correctly. Firstly, we introduce a unified pipeline for end-to-end real-time human pose estimation and motion analysis using RGB video input from multiple cameras which can be applied to the field of rehabilitation training. The pipeline can help to monitor and correct patients'actions, thus aiding them in regaining muscle strength and motor functions. Secondly, we propose a fast tracking method for medical rehabilitation scenarios with multiple-person interference, which requires less than 1ms for tracking for a single frame. Additionally, we modify SmoothNet for real-time posture estimation, effectively reducing pose estimation errors and restoring the patient's true motion state, making it visually smoother. Finally, we use Unity platform for real-time monitoring and evaluation of patients' motion during rehabilitation, and to display the muscle stress conditions to assist patients with their rehabilitation training.
Don't Waste It: Guiding Generative Recommenders with Structured Human Priors via Multi-head Decoding
Nov 16, 2025Optimizing recommender systems for objectives beyond accuracy, such as diversity, novelty, and personalization, is crucial for long-term user satisfaction. To this end, industrial practitioners have accumulated vast amounts of structured domain knowledge, which we term human priors (e.g., item taxonomies, temporal patterns). This knowledge is typically applied through post-hoc adjustments during ranking or post-ranking. However, this approach remains decoupled from the core model learning, which is particularly undesirable as the industry shifts to end-to-end generative recommendation foundation models. On the other hand, many methods targeting these beyond-accuracy objectives often require architecture-specific modifications and discard these valuable human priors by learning user intent in a fully unsupervised manner. Instead of discarding the human priors accumulated over years of practice, we introduce a backbone-agnostic framework that seamlessly integrates these human priors directly into the end-to-end training of generative recommenders. With lightweight, prior-conditioned adapter heads inspired by efficient LLM decoding strategies, our approach guides the model to disentangle user intent along human-understandable axes (e.g., interaction types, long- vs. short-term interests). We also introduce a hierarchical composition strategy for modeling complex interactions across different prior types. Extensive experiments on three large-scale datasets demonstrate that our method significantly enhances both accuracy and beyond-accuracy objectives. We also show that human priors allow the backbone model to more effectively leverage longer context lengths and larger model sizes.
WeChat-YATT: A Simple, Scalable and Balanced RLHF Trainer
Aug 11, 2025Reinforcement Learning from Human Feedback (RLHF) has emerged as a prominent paradigm for training large language models and multimodal systems. Despite notable advances enabled by existing RLHF training frameworks, significant challenges remain in scaling to complex multimodal workflows and adapting to dynamic workloads. In particular, current systems often encounter limitations related to controller scalability when managing large models, as well as inefficiencies in orchestrating intricate RLHF pipelines, especially in scenarios that require dynamic sampling and resource allocation. In this paper, we introduce WeChat-YATT (Yet Another Transformer Trainer in WeChat), a simple, scalable, and balanced RLHF training framework specifically designed to address these challenges. WeChat-YATT features a parallel controller programming model that enables flexible and efficient orchestration of complex RLHF workflows, effectively mitigating the bottlenecks associated with centralized controller architectures and facilitating scalability in large-scale data scenarios. In addition, we propose a dynamic placement schema that adaptively partitions computational resources and schedules workloads, thereby significantly reducing hardware idle time and improving GPU utilization under variable training conditions. We evaluate WeChat-YATT across a range of experimental scenarios, demonstrating that it achieves substantial improvements in throughput compared to state-of-the-art RLHF training frameworks. Furthermore, WeChat-YATT has been successfully deployed to train models supporting WeChat product features for a large-scale user base, underscoring its effectiveness and robustness in real-world applications.
G-Core: A Simple, Scalable and Balanced RLHF Trainer
Jul 30, 2025Reinforcement Learning from Human Feedback (RLHF) has become an increasingly popular paradigm for training large language models (LLMs) and diffusion models. While existing RLHF training systems have enabled significant progress, they often face challenges in scaling to multi-modal and diffusion workflows and adapting to dynamic workloads. In particular, current approaches may encounter limitations in controller scalability, flexible resource placement, and efficient orchestration when handling complex RLHF pipelines, especially in scenarios involving dynamic sampling or generative reward modeling. In this paper, we present \textbf{G-Core}, a simple, scalable, and balanced RLHF training framework designed to address these challenges. G-Core introduces a parallel controller programming model, enabling flexible and efficient orchestration of complex RLHF workflows without the bottlenecks of a single centralized controller. Furthermore, we propose a dynamic placement schema that adaptively partitions resources and schedules workloads, significantly reducing hardware idle time and improving utilization, even under highly variable training conditions. G-Core has successfully trained models that support WeChat product features serving a large-scale user base, demonstrating its effectiveness and robustness in real-world scenarios. Our results show that G-Core advances the state of the art in RLHF training, providing a solid foundation for future research and deployment of large-scale, human-aligned models.
Dual Attention Driven Lumbar Magnetic Resonance Image Feature Enhancement and Automatic Diagnosis of Herniation
Apr 28, 2025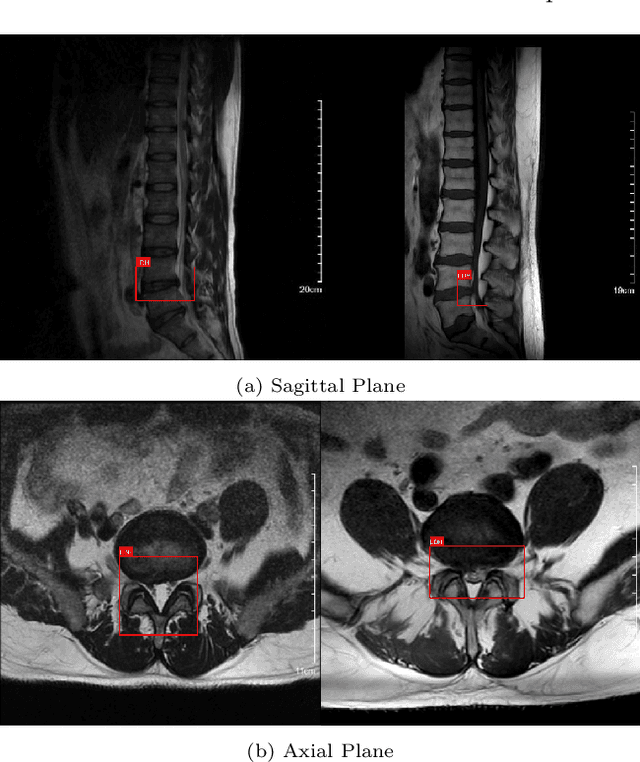
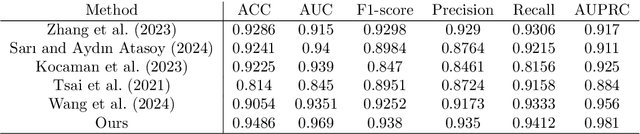
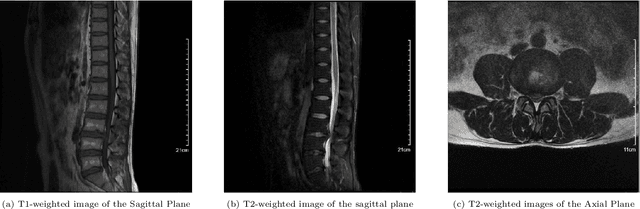
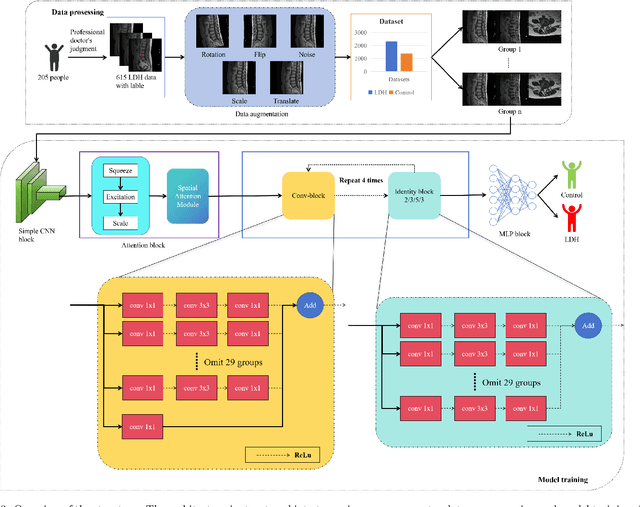
Lumbar disc herniation (LDH) is a common musculoskeletal disease that requires magnetic resonance imaging (MRI) for effective clinical management. However, the interpretation of MRI images heavily relies on the expertise of radiologists, leading to delayed diagnosis and high costs for training physicians. Therefore, this paper proposes an innovative automated LDH classification framework. To address these key issues, the framework utilizes T1-weighted and T2-weighted MRI images from 205 people. The framework extracts clinically actionable LDH features and generates standardized diagnostic outputs by leveraging data augmentation and channel and spatial attention mechanisms. These outputs can help physicians make confident and time-effective care decisions when needed. The proposed framework achieves an area under the receiver operating characteristic curve (AUC-ROC) of 0.969 and an accuracy of 0.9486 for LDH detection. The experimental results demonstrate the performance of the proposed framework. Our framework only requires a small number of datasets for training to demonstrate high diagnostic accuracy. This is expected to be a solution to enhance the LDH detection capabilities of primary hospitals.
Transforming Future Data Center Operations and Management via Physical AI
Apr 07, 2025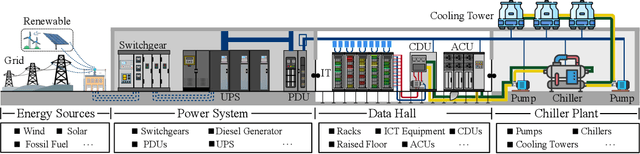
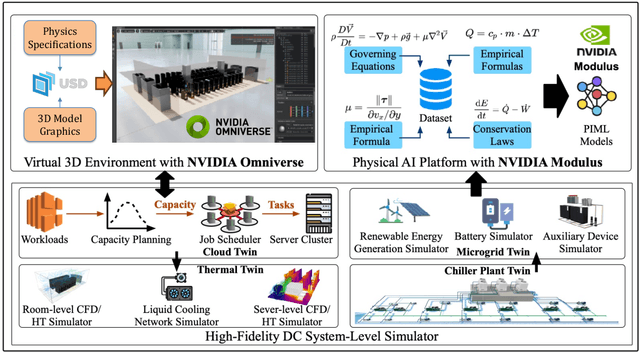
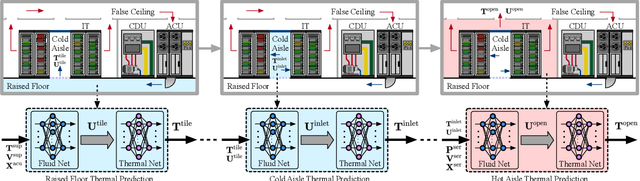
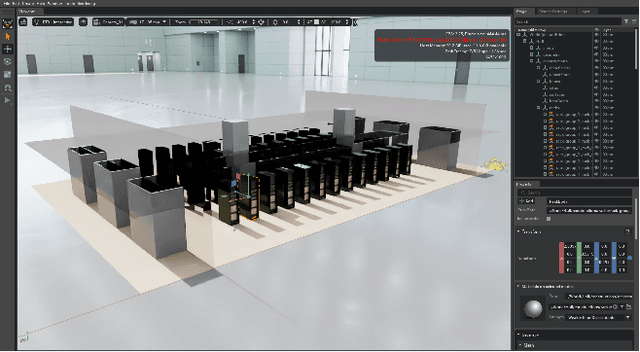
Data centers (DCs) as mission-critical infrastructures are pivotal in powering the growth of artificial intelligence (AI) and the digital economy. The evolution from Internet DC to AI DC has introduced new challenges in operating and managing data centers for improved business resilience and reduced total cost of ownership. As a result, new paradigms, beyond the traditional approaches based on best practices, must be in order for future data centers. In this research, we propose and develop a novel Physical AI (PhyAI) framework for advancing DC operations and management. Our system leverages the emerging capabilities of state-of-the-art industrial products and our in-house research and development. Specifically, it presents three core modules, namely: 1) an industry-grade in-house simulation engine to simulate DC operations in a highly accurate manner, 2) an AI engine built upon NVIDIA PhysicsNemo for the training and evaluation of physics-informed machine learning (PIML) models, and 3) a digital twin platform built upon NVIDIA Omniverse for our proposed 5-tier digital twin framework. This system presents a scalable and adaptable solution to digitalize, optimize, and automate future data center operations and management, by enabling real-time digital twins for future data centers. To illustrate its effectiveness, we present a compelling case study on building a surrogate model for predicting the thermal and airflow profiles of a large-scale DC in a real-time manner. Our results demonstrate its superior performance over traditional time-consuming Computational Fluid Dynamics/Heat Transfer (CFD/HT) simulation, with a median absolute temperature prediction error of 0.18 {\deg}C. This emerging approach would open doors to several potential research directions for advancing Physical AI in future DC operations.
RobuNFR: Evaluating the Robustness of Large Language Models on Non-Functional Requirements Aware Code Generation
Mar 28, 2025When using LLMs to address Non-Functional Requirements (NFRs), developers may behave differently (e.g., expressing the same NFR in different words). Robust LLMs should output consistent results across these variations; however, this aspect remains underexplored. We propose RobuNFR for evaluating the robustness of LLMs in NFR-aware code generation across four NFR dimensions: design, readability, reliability, and performance, using three methodologies: prompt variation, regression testing, and diverse workflows. Our experiments show that RobuNFR reveals robustness issues in the tested LLMs when considering NFRs in code generation. Specifically, under prompt variation, including NFRs leads to a decrease in Pass@1 by up to 39 percent and an increase in the standard deviation from 0.48 to 2.48 compared to the baseline without NFRs (i.e., Function-Only). While incorporating NFRs generally improves overall NFR metrics, it also results in higher prompt sensitivity. In regression settings, some LLMs exhibit differences across versions, with improvements in one aspect (e.g., reduced code smells) often accompanied by regressions in another (e.g., decreased correctness), revealing inconsistencies that challenge their robustness. When varying workflows, the tested LLMs show significantly different NFR-aware code generation capabilities between two workflows: (1) integrating NFRs and functional requirements into the initial prompt and (2) enhancing Function-Only-generated code with the same NFR.
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Jan 21, 2025This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks. Experiments demonstrate its superior performance: UI-TARS achieves SOTA performance in 10+ GUI agent benchmarks evaluating perception, grounding, and GUI task execution. Notably, in the OSWorld benchmark, UI-TARS achieves scores of 24.6 with 50 steps and 22.7 with 15 steps, outperforming Claude (22.0 and 14.9 respectively). In AndroidWorld, UI-TARS achieves 46.6, surpassing GPT-4o (34.5). UI-TARS incorporates several key innovations: (1) Enhanced Perception: leveraging a large-scale dataset of GUI screenshots for context-aware understanding of UI elements and precise captioning; (2) Unified Action Modeling, which standardizes actions into a unified space across platforms and achieves precise grounding and interaction through large-scale action traces; (3) System-2 Reasoning, which incorporates deliberate reasoning into multi-step decision making, involving multiple reasoning patterns such as task decomposition, reflection thinking, milestone recognition, etc. (4) Iterative Training with Reflective Online Traces, which addresses the data bottleneck by automatically collecting, filtering, and reflectively refining new interaction traces on hundreds of virtual machines. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations with minimal human intervention. We also analyze the evolution path of GUI agents to guide the further development of this domain.
REO-VLM: Transforming VLM to Meet Regression Challenges in Earth Observation
Dec 21, 2024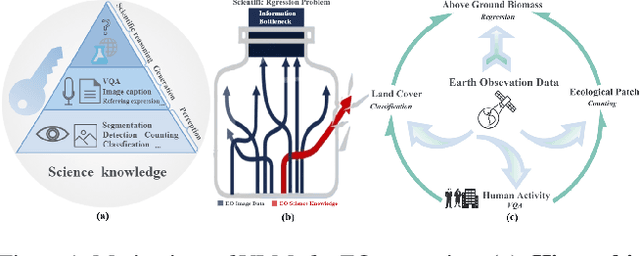


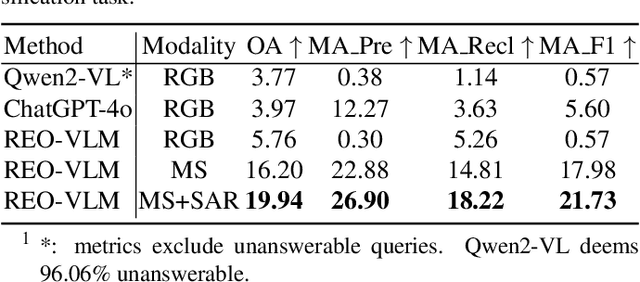
The rapid evolution of Vision Language Models (VLMs) has catalyzed significant advancements in artificial intelligence, expanding research across various disciplines, including Earth Observation (EO). While VLMs have enhanced image understanding and data processing within EO, their applications have predominantly focused on image content description. This limited focus overlooks their potential in geographic and scientific regression tasks, which are essential for diverse EO applications. To bridge this gap, this paper introduces a novel benchmark dataset, called \textbf{REO-Instruct} to unify regression and generation tasks specifically for the EO domain. Comprising 1.6 million multimodal EO imagery and language pairs, this dataset is designed to support both biomass regression and image content interpretation tasks. Leveraging this dataset, we develop \textbf{REO-VLM}, a groundbreaking model that seamlessly integrates regression capabilities with traditional generative functions. By utilizing language-driven reasoning to incorporate scientific domain knowledge, REO-VLM goes beyond solely relying on EO imagery, enabling comprehensive interpretation of complex scientific attributes from EO data. This approach establishes new performance benchmarks and significantly enhances the capabilities of environmental monitoring and resource management.