 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProGraph: Temporally-alignable Probability Guided Graph Topological Modeling for 3D Human Reconstruction
Nov 07, 2024



Current 3D human motion reconstruction methods from monocular videos rely on features within the current reconstruction window, leading to distortion and deformations in the human structure under local occlusions or blurriness in video frames. To estimate realistic 3D human mesh sequences based on incomplete features, we propose Temporally-alignable Probability Guided Graph Topological Modeling for 3D Human Reconstruction (ProGraph). For missing parts recovery, we exploit the explicit topological-aware probability distribution across the entire motion sequence. To restore the complete human, Graph Topological Modeling (GTM) learns the underlying topological structure, focusing on the relationships inherent in the individual parts. Next, to generate blurred motion parts, Temporal-alignable Probability Distribution (TPDist) utilizes the GTM to predict features based on distribution. This interactive mechanism facilitates motion consistency, allowing the restoration of human parts. Furthermore, Hierarchical Human Loss (HHLoss) constrains the probability distribution errors of inter-frame features during topological structure variation. Our Method achieves superior results than other SOTA methods in addressing occlusions and blurriness on 3DPW.
NieR: Normal-Based Lighting Scene Rendering
May 21, 2024



In real-world road scenes, diverse material properties lead to complex light reflection phenomena, making accurate color reproduction crucial for enhancing the realism and safety of simulated driving environments. However, existing methods often struggle to capture the full spectrum of lighting effects, particularly in dynamic scenarios where viewpoint changes induce significant material color variations. To address this challenge, we introduce NieR (Normal-Based Lighting Scene Rendering), a novel framework that takes into account the nuances of light reflection on diverse material surfaces, leading to more precise rendering. To simulate the lighting synthesis process, we present the LD (Light Decomposition) module, which captures the lighting reflection characteristics on surfaces. Furthermore, to address dynamic lighting scenes, we propose the HNGD (Hierarchical Normal Gradient Densification) module to overcome the limitations of sparse Gaussian representation. Specifically, we dynamically adjust the Gaussian density based on normal gradients. Experimental evaluations demonstrate that our method outperforms state-of-the-art (SOTA) methods in terms of visual quality and exhibits significant advantages in performance indicators. Codes are available at https://wanghongsheng01.github.io/NieR/.
Gaussian Control with Hierarchical Semantic Graphs in 3D Human Recovery
May 21, 2024



Although 3D Gaussian Splatting (3DGS) has recently made progress in 3D human reconstruction, it primarily relies on 2D pixel-level supervision, overlooking the geometric complexity and topological relationships of different body parts. To address this gap, we introduce the Hierarchical Graph Human Gaussian Control (HUGS) framework for achieving high-fidelity 3D human reconstruction. Our approach involves leveraging explicitly semantic priors of body parts to ensure the consistency of geometric topology, thereby enabling the capture of the complex geometrical and topological associations among body parts. Additionally, we disentangle high-frequency features from global human features to refine surface details in body parts. Extensive experiments demonstrate that our method exhibits superior performance in human body reconstruction, particularly in enhancing surface details and accurately reconstructing body part junctions. Codes are available at https://wanghongsheng01.github.io/HUGS/.
NOVA-3D: Non-overlapped Views for 3D Anime Character Reconstruction
May 21, 2024



In the animation industry, 3D modelers typically rely on front and back non-overlapped concept designs to guide the 3D modeling of anime characters. However, there is currently a lack of automated approaches for generating anime characters directly from these 2D designs. In light of this, we explore a novel task of reconstructing anime characters from non-overlapped views. This presents two main challenges: existing multi-view approaches cannot be directly applied due to the absence of overlapping regions, and there is a scarcity of full-body anime character data and standard benchmarks. To bridge the gap, we present Non-Overlapped Views for 3D \textbf{A}nime Character Reconstruction (NOVA-3D), a new framework that implements a method for view-aware feature fusion to learn 3D-consistent features effectively and synthesizes full-body anime characters from non-overlapped front and back views directly. To facilitate this line of research, we collected the NOVA-Human dataset, which comprises multi-view images and accurate camera parameters for 3D anime characters. Extensive experiments demonstrate that the proposed method outperforms baseline approaches, achieving superior reconstruction of anime characters with exceptional detail fidelity. In addition, to further verify the effectiveness of our method, we applied it to the animation head reconstruction task and improved the state-of-the-art baseline to 94.453 in SSIM, 7.726 in LPIPS, and 19.575 in PSNR on average. Codes and datasets are available at https://wanghongsheng01.github.io/NOVA-3D/.
RemoCap: Disentangled Representation Learning for Motion Capture
May 21, 2024



Reconstructing 3D human bodies from realistic motion sequences remains a challenge due to pervasive and complex occlusions. Current methods struggle to capture the dynamics of occluded body parts, leading to model penetration and distorted motion. RemoCap leverages Spatial Disentanglement (SD) and Motion Disentanglement (MD) to overcome these limitations. SD addresses occlusion interference between the target human body and surrounding objects. It achieves this by disentangling target features along the dimension axis. By aligning features based on their spatial positions in each dimension, SD isolates the target object's response within a global window, enabling accurate capture despite occlusions. The MD module employs a channel-wise temporal shuffling strategy to simulate diverse scene dynamics. This process effectively disentangles motion features, allowing RemoCap to reconstruct occluded parts with greater fidelity. Furthermore, this paper introduces a sequence velocity loss that promotes temporal coherence. This loss constrains inter-frame velocity errors, ensuring the predicted motion exhibits realistic consistency. Extensive comparisons with state-of-the-art (SOTA) methods on benchmark datasets demonstrate RemoCap's superior performance in 3D human body reconstruction. On the 3DPW dataset, RemoCap surpasses all competitors, achieving the best results in MPVPE (81.9), MPJPE (72.7), and PA-MPJPE (44.1) metrics. Codes are available at https://wanghongsheng01.github.io/RemoCap/.
MOSS: Motion-based 3D Clothed Human Synthesis from Monocular Video
May 21, 2024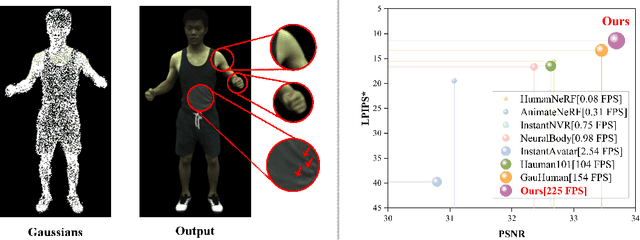
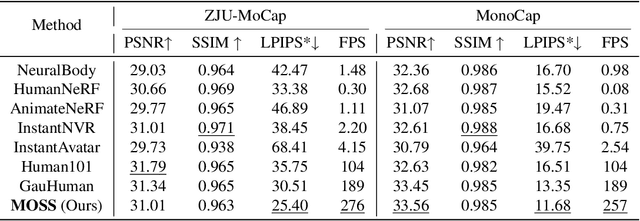
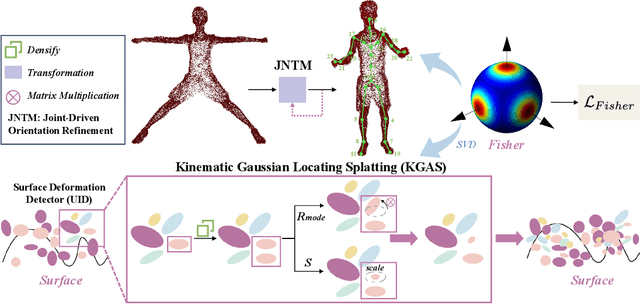

Single-view clothed human reconstruction holds a central position in virtual reality applications, especially in contexts involving intricate human motions. It presents notable challenges in achieving realistic clothing deformation. Current methodologies often overlook the influence of motion on surface deformation, resulting in surfaces lacking the constraints imposed by global motion. To overcome these limitations, we introduce an innovative framework, Motion-Based 3D Clothed Humans Synthesis (MOSS), which employs kinematic information to achieve motion-aware Gaussian split on the human surface. Our framework consists of two modules: Kinematic Gaussian Locating Splatting (KGAS) and Surface Deformation Detector (UID). KGAS incorporates matrix-Fisher distribution to propagate global motion across the body surface. The density and rotation factors of this distribution explicitly control the Gaussians, thereby enhancing the realism of the reconstructed surface. Additionally, to address local occlusions in single-view, based on KGAS, UID identifies significant surfaces, and geometric reconstruction is performed to compensate for these deformations. Experimental results demonstrate that MOSS achieves state-of-the-art visual quality in 3D clothed human synthesis from monocular videos. Notably, we improve the Human NeRF and the Gaussian Splatting by 33.94% and 16.75% in LPIPS* respectively. Codes are available at https://wanghongsheng01.github.io/MOSS/.
Few-Shot Segmentation via Rich Prototype Generation and Recurrent Prediction Enhancement
Oct 03, 2022

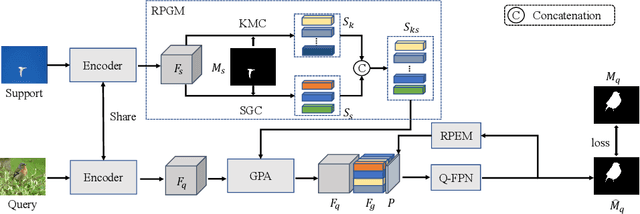

Prototype learning and decoder construction are the keys for few-shot segmentation. However, existing methods use only a single prototype generation mode, which can not cope with the intractable problem of objects with various scales. Moreover, the one-way forward propagation adopted by previous methods may cause information dilution from registered features during the decoding process. In this research, we propose a rich prototype generation module (RPGM) and a recurrent prediction enhancement module (RPEM) to reinforce the prototype learning paradigm and build a unified memory-augmented decoder for few-shot segmentation, respectively. Specifically, the RPGM combines superpixel and K-means clustering to generate rich prototype features with complementary scale relationships and adapt the scale gap between support and query images. The RPEM utilizes the recurrent mechanism to design a round-way propagation decoder. In this way, registered features can provide object-aware information continuously. Experiments show that our method consistently outperforms other competitors on two popular benchmarks PASCAL-${{5}^{i}}$ and COCO-${{20}^{i}}$.