 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAT: Supervisor Regularization and Animation Augmentation for Two-process Monocular Texture 3D Human Reconstruction
Aug 27, 2025


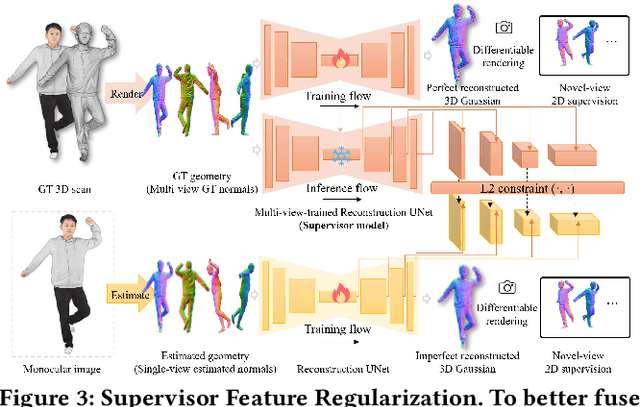
Monocular texture 3D human reconstruction aims to create a complete 3D digital avatar from just a single front-view human RGB image. However, the geometric ambiguity inherent in a single 2D image and the scarcity of 3D human training data are the main obstacles limiting progress in this field. To address these issues, current methods employ prior geometric estimation networks to derive various human geometric forms, such as the SMPL model and normal maps. However, they struggle to integrate these modalities effectively, leading to view inconsistencies, such as facial distortions. To this end, we propose a two-process 3D human reconstruction framework, SAT, which seamlessly learns various prior geometries in a unified manner and reconstructs high-quality textured 3D avatars as the final output. To further facilitate geometry learning, we introduce a Supervisor Feature Regularization module. By employing a multi-view network with the same structure to provide intermediate features as training supervision, these varied geometric priors can be better fused. To tackle data scarcity and further improve reconstruction quality, we also propose an Online Animation Augmentation module. By building a one-feed-forward animation network, we augment a massive number of samples from the original 3D human data online for model training. Extensive experiments on two benchmarks show the superiority of our approach compared to state-of-the-art methods.
SMPL Normal Map Is All You Need for Single-view Textured Human Reconstruction
Jun 15, 2025Single-view textured human reconstruction aims to reconstruct a clothed 3D digital human by inputting a monocular 2D image. Existing approaches include feed-forward methods, limited by scarce 3D human data, and diffusion-based methods, prone to erroneous 2D hallucinations. To address these issues, we propose a novel SMPL normal map Equipped 3D Human Reconstruction (SEHR) framework, integrating a pretrained large 3D reconstruction model with human geometry prior. SEHR performs single-view human reconstruction without using a preset diffusion model in one forward propagation. Concretely, SEHR consists of two key components: SMPL Normal Map Guidance (SNMG) and SMPL Normal Map Constraint (SNMC). SNMG incorporates SMPL normal maps into an auxiliary network to provide improved body shape guidance. SNMC enhances invisible body parts by constraining the model to predict an extra SMPL normal Gaussians. Extensive experiments on two benchmark datasets demonstrate that SEHR outperforms existing state-of-the-art methods.
Unify3D: An Augmented Holistic End-to-end Monocular 3D Human Reconstruction via Anatomy Shaping and Twins Negotiating
Apr 25, 2025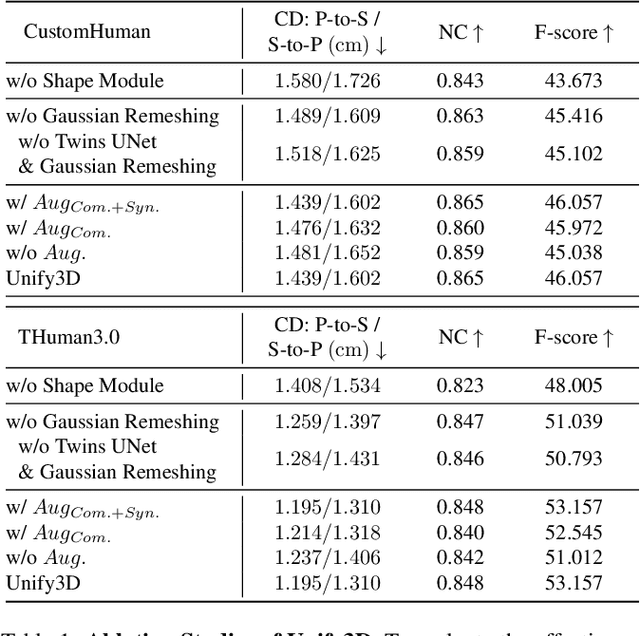
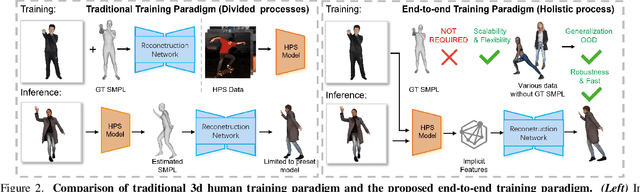
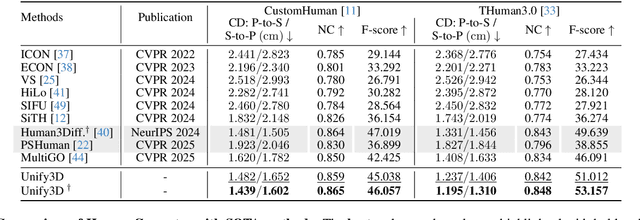
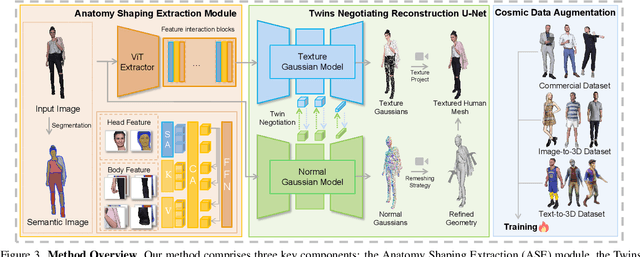
Monocular 3D clothed human reconstruction aims to create a complete 3D avatar from a single image. To tackle the human geometry lacking in one RGB image, current methods typically resort to a preceding model for an explicit geometric representation. For the reconstruction itself, focus is on modeling both it and the input image. This routine is constrained by the preceding model, and overlooks the integrity of the reconstruction task. To address this, this paper introduces a novel paradigm that treats human reconstruction as a holistic process, utilizing an end-to-end network for direct prediction from 2D image to 3D avatar, eliminating any explicit intermediate geometry display. Based on this, we further propose a novel reconstruction framework consisting of two core components: the Anatomy Shaping Extraction module, which captures implicit shape features taking into account the specialty of human anatomy, and the Twins Negotiating Reconstruction U-Net, which enhances reconstruction through feature interaction between two U-Nets of different modalities. Moreover, we propose a Comic Data Augmentation strategy and construct 15k+ 3D human scans to bolster model performance in more complex case input. Extensive experiments on two test sets and many in-the-wild cases show the superiority of our method over SOTA methods. Our demos can be found in : https://e2e3dgsrecon.github.io/e2e3dgsrecon/.
MultiGO: Towards Multi-level Geometry Learning for Monocular 3D Textured Human Reconstruction
Dec 04, 2024



This paper investigates the research task of reconstructing the 3D clothed human body from a monocular image. Due to the inherent ambiguity of single-view input, existing approaches leverage pre-trained SMPL(-X) estimation models or generative models to provide auxiliary information for human reconstruction. However, these methods capture only the general human body geometry and overlook specific geometric details, leading to inaccurate skeleton reconstruction, incorrect joint positions, and unclear cloth wrinkles. In response to these issues, we propose a multi-level geometry learning framework. Technically, we design three key components: skeleton-level enhancement, joint-level augmentation, and wrinkle-level refinement modules. Specifically, we effectively integrate the projected 3D Fourier features into a Gaussian reconstruction model, introduce perturbations to improve joint depth estimation during training, and refine the human coarse wrinkles by resembling the de-noising process of diffusion model. Extensive quantitative and qualitative experiments on two out-of-distribution test sets show the superior performance of our approach compared to state-of-the-art (SOTA) methods.
NOVA-3D: Non-overlapped Views for 3D Anime Character Reconstruction
May 21, 2024



In the animation industry, 3D modelers typically rely on front and back non-overlapped concept designs to guide the 3D modeling of anime characters. However, there is currently a lack of automated approaches for generating anime characters directly from these 2D designs. In light of this, we explore a novel task of reconstructing anime characters from non-overlapped views. This presents two main challenges: existing multi-view approaches cannot be directly applied due to the absence of overlapping regions, and there is a scarcity of full-body anime character data and standard benchmarks. To bridge the gap, we present Non-Overlapped Views for 3D \textbf{A}nime Character Reconstruction (NOVA-3D), a new framework that implements a method for view-aware feature fusion to learn 3D-consistent features effectively and synthesizes full-body anime characters from non-overlapped front and back views directly. To facilitate this line of research, we collected the NOVA-Human dataset, which comprises multi-view images and accurate camera parameters for 3D anime characters. Extensive experiments demonstrate that the proposed method outperforms baseline approaches, achieving superior reconstruction of anime characters with exceptional detail fidelity. In addition, to further verify the effectiveness of our method, we applied it to the animation head reconstruction task and improved the state-of-the-art baseline to 94.453 in SSIM, 7.726 in LPIPS, and 19.575 in PSNR on average. Codes and datasets are available at https://wanghongsheng01.github.io/NOVA-3D/.