 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity and Long-Duration Human Image Animation with Diffusion Transformer
Dec 26, 2025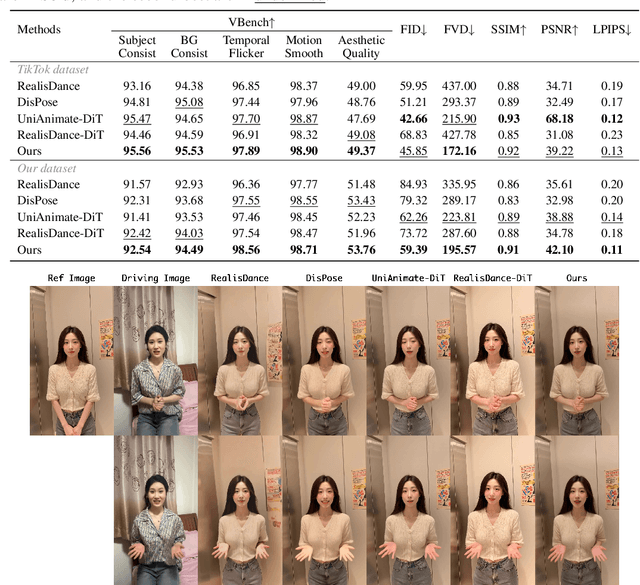

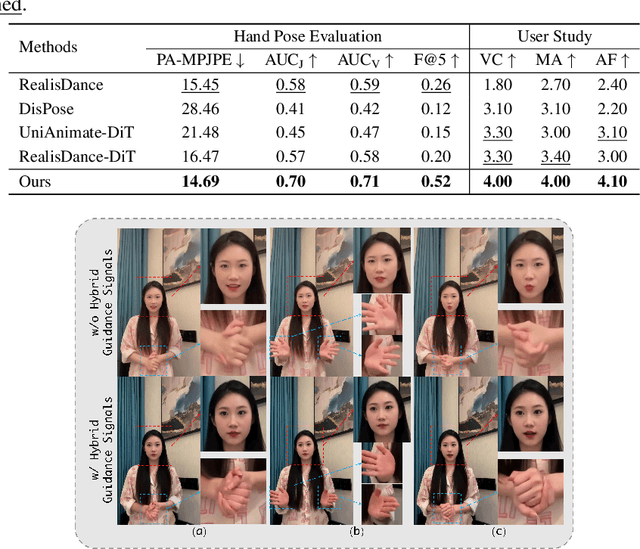
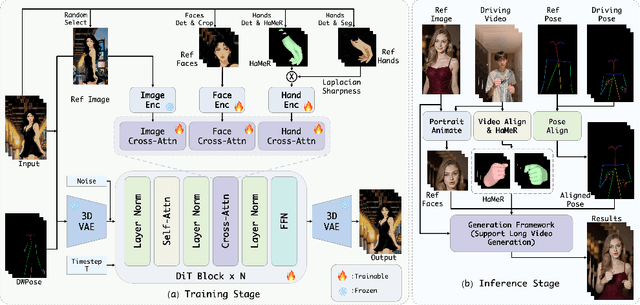
Recent progress in diffusion models has significantly advanced the field of human image animation. While existing methods can generate temporally consistent results for short or regular motions, significant challenges remain, particularly in generating long-duration videos. Furthermore, the synthesis of fine-grained facial and hand details remains under-explored, limiting the applicability of current approaches in real-world, high-quality applications. To address these limitations, we propose a diffusion transformer (DiT)-based framework which focuses on generating high-fidelity and long-duration human animation videos. First, we design a set of hybrid implicit guidance signals and a sharpness guidance factor, enabling our framework to additionally incorporate detailed facial and hand features as guidance. Next, we incorporate the time-aware position shift fusion module, modify the input format within the DiT backbone, and refer to this mechanism as the Position Shift Adaptive Module, which enables video generation of arbitrary length. Finally, we introduce a novel data augmentation strategy and a skeleton alignment model to reduce the impact of human shape variations across different identities. Experimental results demonstrate that our method outperforms existing state-of-the-art approaches, achieving superior performance in both high-fidelity and long-duration human image animation.
GaussianProperty: Integrating Physical Properties to 3D Gaussians with LMMs
Dec 15, 2024Estimating physical properties for visual data is a crucial task in computer vision, graphics, and robotics, underpinning applications such as augmented reality, physical simulation, and robotic grasping. However, this area remains under-explored due to the inherent ambiguities in physical property estimation. To address these challenges, we introduce GaussianProperty, a training-free framework that assigns physical properties of materials to 3D Gaussians. Specifically, we integrate the segmentation capability of SAM with the recognition capability of GPT-4V(ision) to formulate a global-local physical property reasoning module for 2D images. Then we project the physical properties from multi-view 2D images to 3D Gaussians using a voting strategy. We demonstrate that 3D Gaussians with physical property annotations enable applications in physics-based dynamic simulation and robotic grasping. For physics-based dynamic simulation, we leverage the Material Point Method (MPM) for realistic dynamic simulation. For robot grasping, we develop a grasping force prediction strategy that estimates a safe force range required for object grasping based on the estimated physical properties. Extensive experiments on material segmentation, physics-based dynamic simulation, and robotic grasping validate the effectiveness of our proposed method, highlighting its crucial role in understanding physical properties from visual data. Online demo, code, more cases and annotated datasets are available on \href{https://Gaussian-Property.github.io}{this https URL}.
Human Multi-View Synthesis from a Single-View Model:Transferred Body and Face Representations
Dec 04, 2024



Generating multi-view human images from a single view is a complex and significant challenge. Although recent advancements in multi-view object generation have shown impressive results with diffusion models, novel view synthesis for humans remains constrained by the limited availability of 3D human datasets. Consequently, many existing models struggle to produce realistic human body shapes or capture fine-grained facial details accurately. To address these issues, we propose an innovative framework that leverages transferred body and facial representations for multi-view human synthesis. Specifically, we use a single-view model pretrained on a large-scale human dataset to develop a multi-view body representation, aiming to extend the 2D knowledge of the single-view model to a multi-view diffusion model. Additionally, to enhance the model's detail restoration capability, we integrate transferred multimodal facial features into our trained human diffusion model. Experimental evaluations on benchmark datasets demonstrate that our approach outperforms the current state-of-the-art methods, achieving superior performance in multi-view human synthesis.
MultiGO: Towards Multi-level Geometry Learning for Monocular 3D Textured Human Reconstruction
Dec 04, 2024



This paper investigates the research task of reconstructing the 3D clothed human body from a monocular image. Due to the inherent ambiguity of single-view input, existing approaches leverage pre-trained SMPL(-X) estimation models or generative models to provide auxiliary information for human reconstruction. However, these methods capture only the general human body geometry and overlook specific geometric details, leading to inaccurate skeleton reconstruction, incorrect joint positions, and unclear cloth wrinkles. In response to these issues, we propose a multi-level geometry learning framework. Technically, we design three key components: skeleton-level enhancement, joint-level augmentation, and wrinkle-level refinement modules. Specifically, we effectively integrate the projected 3D Fourier features into a Gaussian reconstruction model, introduce perturbations to improve joint depth estimation during training, and refine the human coarse wrinkles by resembling the de-noising process of diffusion model. Extensive quantitative and qualitative experiments on two out-of-distribution test sets show the superior performance of our approach compared to state-of-the-art (SOTA) methods.