 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
RoboEvolve: Co-Evolving Planner-Simulator for Robotic Manipulation with Limited Data
May 13, 2026The scalability of robotic manipulation is fundamentally bottlenecked by the scarcity of task-aligned physical interaction data. While vision-language models (VLMs) and video generation models (VGMs) hold promise for autonomous data synthesis, they suffer from semantic-spatial misalignment and physical hallucinations, respectively. To bridge this gap, we introduce RoboEvolve, a novel framework that couples a VLM planner and a VGM simulator into a mutually reinforcing co-evolutionary loop. Operating purely on unlabeled seed images, RoboEvolve leverages a cognitive-inspired dual-phase mechanism: (i) daytime exploration fosters physically grounded behavioral discovery through a semantic-controlled multi-granular reward, and (ii) nighttime consolidation mines "near-miss" failures to stabilize policy optimization. Guided by an autonomous progressive curriculum, the system naturally scales from simple atomic actions to complex tasks. Extensive experiments demonstrate that RoboEvolve (I) achieves superior effectiveness, elevating base planners by 30 absolute points and amplifying simulator success by 48% on average; (II) exhibits extreme data efficiency, surpassing fully supervised baselines with merely 500 unlabeled seeds--a 50x reduction; and (III) demonstrates robust continual learning without catastrophic forgetting.
A Mechanistic View on Video Generation as World Models: State and Dynamics
Jan 22, 2026Large-scale video generation models have demonstrated emergent physical coherence, positioning them as potential world models. However, a gap remains between contemporary "stateless" video architectures and classic state-centric world model theories. This work bridges this gap by proposing a novel taxonomy centered on two pillars: State Construction and Dynamics Modeling. We categorize state construction into implicit paradigms (context management) and explicit paradigms (latent compression), while dynamics modeling is analyzed through knowledge integration and architectural reformulation. Furthermore, we advocate for a transition in evaluation from visual fidelity to functional benchmarks, testing physical persistence and causal reasoning. We conclude by identifying two critical frontiers: enhancing persistence via data-driven memory and compressed fidelity, and advancing causality through latent factor decoupling and reasoning-prior integration. By addressing these challenges, the field can evolve from generating visually plausible videos to building robust, general-purpose world simulators.
CamPilot: Improving Camera Control in Video Diffusion Model with Efficient Camera Reward Feedback
Jan 22, 2026Recent advances in camera-controlled video diffusion models have significantly improved video-camera alignment. However, the camera controllability still remains limited. In this work, we build upon Reward Feedback Learning and aim to further improve camera controllability. However, directly borrowing existing ReFL approaches faces several challenges. First, current reward models lack the capacity to assess video-camera alignment. Second, decoding latent into RGB videos for reward computation introduces substantial computational overhead. Third, 3D geometric information is typically neglected during video decoding. To address these limitations, we introduce an efficient camera-aware 3D decoder that decodes video latent into 3D representations for reward quantization. Specifically, video latent along with the camera pose are decoded into 3D Gaussians. In this process, the camera pose not only acts as input, but also serves as a projection parameter. Misalignment between the video latent and camera pose will cause geometric distortions in the 3D structure, resulting in blurry renderings. Based on this property, we explicitly optimize pixel-level consistency between the rendered novel views and ground-truth ones as reward. To accommodate the stochastic nature, we further introduce a visibility term that selectively supervises only deterministic regions derived via geometric warping. Extensive experiments conducted on RealEstate10K and WorldScore benchmarks demonstrate the effectiveness of our proposed method. Project page: \href{https://a-bigbao.github.io/CamPilot/}{CamPilot Page}.
StereoPilot: Learning Unified and Efficient Stereo Conversion via Generative Priors
Dec 18, 2025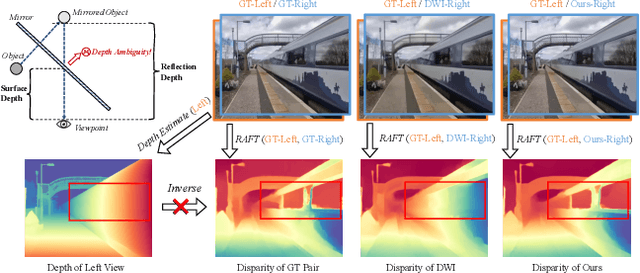

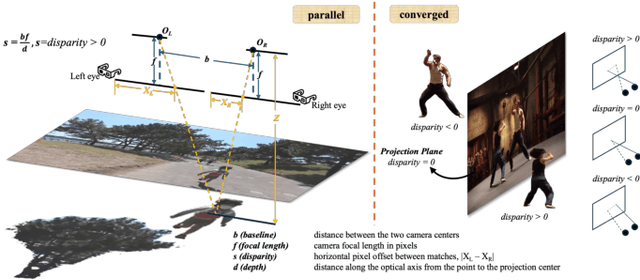

The rapid growth of stereoscopic displays, including VR headsets and 3D cinemas, has led to increasing demand for high-quality stereo video content. However, producing 3D videos remains costly and complex, while automatic Monocular-to-Stereo conversion is hindered by the limitations of the multi-stage ``Depth-Warp-Inpaint'' (DWI) pipeline. This paradigm suffers from error propagation, depth ambiguity, and format inconsistency between parallel and converged stereo configurations. To address these challenges, we introduce UniStereo, the first large-scale unified dataset for stereo video conversion, covering both stereo formats to enable fair benchmarking and robust model training. Building upon this dataset, we propose StereoPilot, an efficient feed-forward model that directly synthesizes the target view without relying on explicit depth maps or iterative diffusion sampling. Equipped with a learnable domain switcher and a cycle consistency loss, StereoPilot adapts seamlessly to different stereo formats and achieves improved consistency. Extensive experiments demonstrate that StereoPilot significantly outperforms state-of-the-art methods in both visual fidelity and computational efficiency. Project page: https://hit-perfect.github.io/StereoPilot/.
Matrix-3D: Omnidirectional Explorable 3D World Generation
Aug 11, 2025Explorable 3D world generation from a single image or text prompt forms a cornerstone of spatial intelligence. Recent works utilize video model to achieve wide-scope and generalizable 3D world generation. However, existing approaches often suffer from a limited scope in the generated scenes. In this work, we propose Matrix-3D, a framework that utilize panoramic representation for wide-coverage omnidirectional explorable 3D world generation that combines conditional video generation and panoramic 3D reconstruction. We first train a trajectory-guided panoramic video diffusion model that employs scene mesh renders as condition, to enable high-quality and geometrically consistent scene video generation. To lift the panorama scene video to 3D world, we propose two separate methods: (1) a feed-forward large panorama reconstruction model for rapid 3D scene reconstruction and (2) an optimization-based pipeline for accurate and detailed 3D scene reconstruction. To facilitate effective training, we also introduce the Matrix-Pano dataset, the first large-scale synthetic collection comprising 116K high-quality static panoramic video sequences with depth and trajectory annotations. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance in panoramic video generation and 3D world generation. See more in https://matrix-3d.github.io.
DiMeR: Disentangled Mesh Reconstruction Model
Apr 24, 2025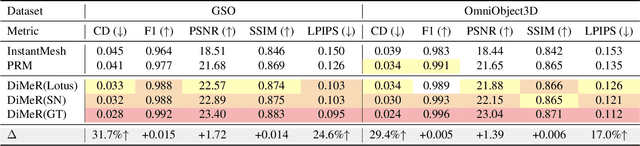

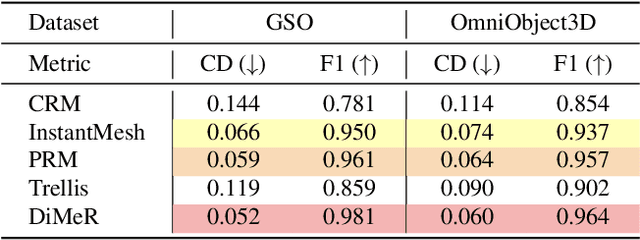
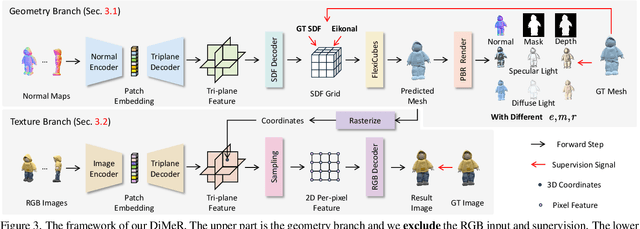
With the advent of large-scale 3D datasets, feed-forward 3D generative models, such as the Large Reconstruction Model (LRM), have gained significant attention and achieved remarkable success. However, we observe that RGB images often lead to conflicting training objectives and lack the necessary clarity for geometry reconstruction. In this paper, we revisit the inductive biases associated with mesh reconstruction and introduce DiMeR, a novel disentangled dual-stream feed-forward model for sparse-view mesh reconstruction. The key idea is to disentangle both the input and framework into geometry and texture parts, thereby reducing the training difficulty for each part according to the Principle of Occam's Razor. Given that normal maps are strictly consistent with geometry and accurately capture surface variations, we utilize normal maps as exclusive input for the geometry branch to reduce the complexity between the network's input and output. Moreover, we improve the mesh extraction algorithm to introduce 3D ground truth supervision. As for texture branch, we use RGB images as input to obtain the textured mesh. Overall, DiMeR demonstrates robust capabilities across various tasks, including sparse-view reconstruction, single-image-to-3D, and text-to-3D. Numerous experiments show that DiMeR significantly outperforms previous methods, achieving over 30% improvement in Chamfer Distance on the GSO and OmniObject3D dataset.
Uni-Renderer: Unifying Rendering and Inverse Rendering Via Dual Stream Diffusion
Dec 19, 2024



Rendering and inverse rendering are pivotal tasks in both computer vision and graphics. The rendering equation is the core of the two tasks, as an ideal conditional distribution transfer function from intrinsic properties to RGB images. Despite achieving promising results of existing rendering methods, they merely approximate the ideal estimation for a specific scene and come with a high computational cost. Additionally, the inverse conditional distribution transfer is intractable due to the inherent ambiguity. To address these challenges, we propose a data-driven method that jointly models rendering and inverse rendering as two conditional generation tasks within a single diffusion framework. Inspired by UniDiffuser, we utilize two distinct time schedules to model both tasks, and with a tailored dual streaming module, we achieve cross-conditioning of two pre-trained diffusion models. This unified approach, named Uni-Renderer, allows the two processes to facilitate each other through a cycle-consistent constrain, mitigating ambiguity by enforcing consistency between intrinsic properties and rendered images. Combined with a meticulously prepared dataset, our method effectively decomposition of intrinsic properties and demonstrates a strong capability to recognize changes during rendering. We will open-source our training and inference code to the public, fostering further research and development in this area.
GaussianProperty: Integrating Physical Properties to 3D Gaussians with LMMs
Dec 15, 2024Estimating physical properties for visual data is a crucial task in computer vision, graphics, and robotics, underpinning applications such as augmented reality, physical simulation, and robotic grasping. However, this area remains under-explored due to the inherent ambiguities in physical property estimation. To address these challenges, we introduce GaussianProperty, a training-free framework that assigns physical properties of materials to 3D Gaussians. Specifically, we integrate the segmentation capability of SAM with the recognition capability of GPT-4V(ision) to formulate a global-local physical property reasoning module for 2D images. Then we project the physical properties from multi-view 2D images to 3D Gaussians using a voting strategy. We demonstrate that 3D Gaussians with physical property annotations enable applications in physics-based dynamic simulation and robotic grasping. For physics-based dynamic simulation, we leverage the Material Point Method (MPM) for realistic dynamic simulation. For robot grasping, we develop a grasping force prediction strategy that estimates a safe force range required for object grasping based on the estimated physical properties. Extensive experiments on material segmentation, physics-based dynamic simulation, and robotic grasping validate the effectiveness of our proposed method, highlighting its crucial role in understanding physical properties from visual data. Online demo, code, more cases and annotated datasets are available on \href{https://Gaussian-Property.github.io}{this https URL}.
PRM: Photometric Stereo based Large Reconstruction Model
Dec 10, 2024

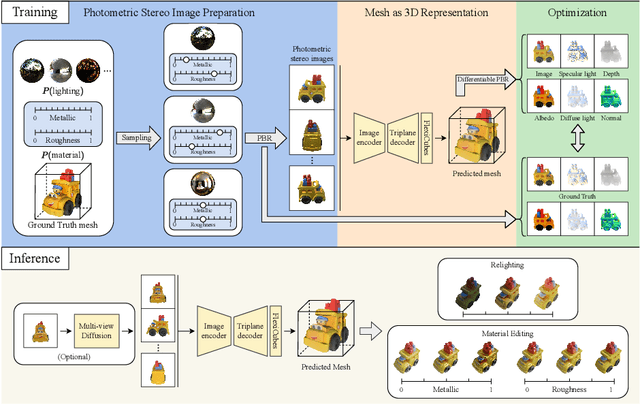

We propose PRM, a novel photometric stereo based large reconstruction model to reconstruct high-quality meshes with fine-grained local details. Unlike previous large reconstruction models that prepare images under fixed and simple lighting as both input and supervision, PRM renders photometric stereo images by varying materials and lighting for the purposes, which not only improves the precise local details by providing rich photometric cues but also increases the model robustness to variations in the appearance of input images. To offer enhanced flexibility of images rendering, we incorporate a real-time physically-based rendering (PBR) method and mesh rasterization for online images rendering. Moreover, in employing an explicit mesh as our 3D representation, PRM ensures the application of differentiable PBR, which supports the utilization of multiple photometric supervisions and better models the specular color for high-quality geometry optimization. Our PRM leverages photometric stereo images to achieve high-quality reconstructions with fine-grained local details, even amidst sophisticated image appearances. Extensive experiments demonstrate that PRM significantly outperforms other models.