 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Adaptive Multiple Visual Prototype Matching for Video-Text Retrieval
Paper and Code
Sep 27, 2022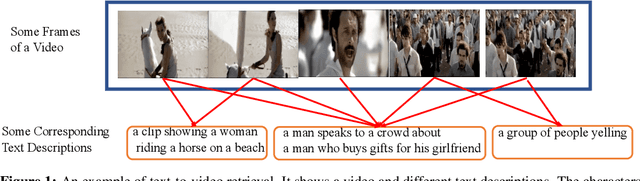
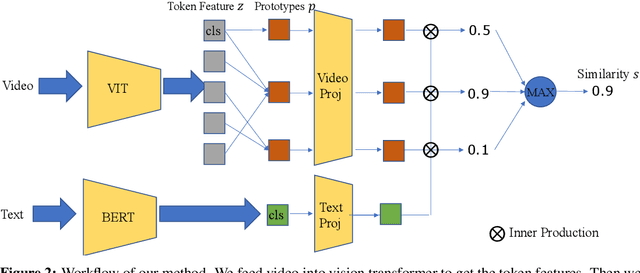
Cross-modal retrieval between videos and texts has gained increasing research interest due to the rapid emergence of videos on the web. Generally, a video contains rich instance and event information and the query text only describes a part of the information. Thus, a video can correspond to multiple different text descriptions and queries. We call this phenomenon the ``Video-Text Correspondence Ambiguity'' problem. Current techniques mostly concentrate on mining local or multi-level alignment between contents of a video and text (\textit{e.g.}, object to entity and action to verb). It is difficult for these methods to alleviate the video-text correspondence ambiguity by describing a video using only one single feature, which is required to be matched with multiple different text features at the same time. To address this problem, we propose a Text-Adaptive Multiple Visual Prototype Matching model, which automatically captures multiple prototypes to describe a video by adaptive aggregation of video token features. Given a query text, the similarity is determined by the most similar prototype to find correspondence in the video, which is termed text-adaptive matching. To learn diverse prototypes for representing the rich information in videos, we propose a variance loss to encourage different prototypes to attend to different contents of the video. Our method outperforms state-of-the-art methods on four public video retrieval datasets.