 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSANA-Streaming: Real-time Streaming Video Editing with Hybrid Diffusion Transformer
May 28, 2026Real-time streaming video-to-video editing (V2V) is critical for interactive applications such as live broadcasting and gaming, yet it remains a formidable challenge due to the stringent requirements for temporal consistency and inference throughput. In this paper, we present SANA-Streaming, a system-algorithm co-designed framework for high-resolution, real-time streaming video editing on consumer GPUs, with the following three core designs: (1) Hybrid Diffusion Transformer architecture introduces softmax attention in part of the blocks to improve local modeling capabilities while preserving the efficiency of linear layers. (2) Cycle-Reverse Regularization is a novel training strategy that enforces semantic consistency by predicting source frames from generated content via flow matching, improving temporal consistency without requiring paired long edited videos. (3) Efficient System Co-design combines fused GDN kernels and Mixed-Precision Quantization (MPQ) optimized for the NVIDIA Blackwell (RTX 5090) architecture. By profiling real-world throughput, our MPQ maximizes Tensor Core utilization while maintaining generation quality. The resulting system achieves real-time 1280 x 704 resolution editing at 24 end-to-end FPS on a single RTX 5090 GPU, with the DiT core running at 58 FPS. Experimental results demonstrate that our co-design approach significantly outperforms existing SOTA methods in both temporal coherence and system throughput.
LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation
May 19, 2026We present LongLive-2.0, an NVFP4-based parallel infrastructure throughout the full training and inference workflow of long video generation, addressing speed and memory bottlenecks. For training, we introduce sequence-parallel autoregressive (AR) training, instantiated as Balanced SP, which co-designs the efficient teacher-forcing layout with SP execution by pairing clean-history and noisy-target temporal chunks on each rank, enabling a natural teacher-forcing mask with SP-aware chunked VAE encoding. Combined with NVFP4 precision, it reduces GPU memory cost and accelerates GEMM computation during training, the proportion of which increases as video length grows. Moreover, we show that a high-quality infrastructure and dataset enable a remarkably clean training pipeline. Unlike existing Self-Forcing series methods that rely on ODE initialization and subsequent distribution matching distillation (DMD), LongLive-2.0 directly tunes a diffusion model into a long, multi-shot, interactive auto-regressive (AR) diffusion model. It can be further converted to real-time generation (4 to 2 denoising steps) with standalone LoRA weights. For inference on Blackwell GPUs, we enable W4A4 NVFP4 inference, quantize KV cache into NVFP4 for memory savings, and boost end-to-end throughput with asynchronous streaming VAE decoding. On non-Blackwell GPU architectures, we deploy SP inference to match the speed on Blackwell GPUs, while the quantized KV cache can lower inter-GPU communication of SP. Experiments show up to 2.15x speedup in training, and 1.84x in inference. LongLive-2.0-5B achieves 45.7 FPS inference while attaining strong performance on benchmarks. To our knowledge, LongLive-2.0 is the first NVFP4 training and inference system for long video generation.
SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
May 14, 2026We introduce SANA-WM, an efficient 2.6B-parameter open-source world model natively trained for one-minute generation, synthesizing high-fidelity, 720p, minute-scale videos with precise camera control. SANA-WM achieves visual quality comparable to large-scale industrial baselines such as LingBot-World and HY-WorldPlay, while significantly improving efficiency. Four core designs drive our architecture: (1) Hybrid Linear Attention combines frame-wise Gated DeltaNet (GDN) with softmax attention for memory-efficient long-context modeling. (2) Dual-Branch Camera Control ensures precise 6-DoF trajectory adherence. (3) Two-Stage Generation Pipeline applies a long-video refiner to stage-1 outputs, improving quality and consistency across sequences. (4) Robust Annotation Pipeline extracts accurate metric-scale 6-DoF camera poses from public videos to yield high-quality, spatiotemporally consistent action labels. Driven by these designs, SANA-WMdemonstrates remarkable efficiency across data, training compute, and inference hardware: it uses only $\sim$213K public video clips with metric-scale pose supervision, completes training in 15 days on 64 H100s, and generates each 60s clip on a single GPU; its distilled variant can be deployed on a single RTX 5090 with NVFP4 quantization to denoise a 60s 720p clip in 34s. On our one-minute world-model benchmark, SANA-WM demonstrates stronger action-following accuracy than prior open-source baselines and achieves comparable visual quality at $36\times$ higher throughput for scalable world modeling.
AJ-Bench: Benchmarking Agent-as-a-Judge for Environment-Aware Evaluation
Apr 20, 2026As reinforcement learning continues to scale the training of large language model-based agents, reliably verifying agent behaviors in complex environments has become increasingly challenging. Existing approaches rely on rule-based verifiers or LLM-as-a-Judge models, which struggle to generalize beyond narrow domains. Agent-as-a-Judge addresses this limitation by actively interacting with environments and tools to acquire verifiable evidence, yet its capabilities remain underexplored. We introduce a benchmark AJ-Bench to systematically evaluate Agent-as-a-Judge across three domains-search, data systems, and graphical user interfaces-comprising 155 tasks and 516 annotated trajectories. The benchmark comprehensively assesses judge agents' abilities in information acquisition, state verification, and process verification. Experiments demonstrate consistent performance gains over LLM-as-a-Judge baselines, while also revealing substantial open challenges in agent-based verification. Our data and code are available at https://aj-bench.github.io/.
SEE4D: Pose-Free 4D Generation via Auto-Regressive Video Inpainting
Oct 30, 2025Immersive applications call for synthesizing spatiotemporal 4D content from casual videos without costly 3D supervision. Existing video-to-4D methods typically rely on manually annotated camera poses, which are labor-intensive and brittle for in-the-wild footage. Recent warp-then-inpaint approaches mitigate the need for pose labels by warping input frames along a novel camera trajectory and using an inpainting model to fill missing regions, thereby depicting the 4D scene from diverse viewpoints. However, this trajectory-to-trajectory formulation often entangles camera motion with scene dynamics and complicates both modeling and inference. We introduce SEE4D, a pose-free, trajectory-to-camera framework that replaces explicit trajectory prediction with rendering to a bank of fixed virtual cameras, thereby separating camera control from scene modeling. A view-conditional video inpainting model is trained to learn a robust geometry prior by denoising realistically synthesized warped images and to inpaint occluded or missing regions across virtual viewpoints, eliminating the need for explicit 3D annotations. Building on this inpainting core, we design a spatiotemporal autoregressive inference pipeline that traverses virtual-camera splines and extends videos with overlapping windows, enabling coherent generation at bounded per-step complexity. We validate See4D on cross-view video generation and sparse reconstruction benchmarks. Across quantitative metrics and qualitative assessments, our method achieves superior generalization and improved performance relative to pose- or trajectory-conditioned baselines, advancing practical 4D world modeling from casual videos.
LongLive: Real-time Interactive Long Video Generation
Sep 26, 2025We present LongLive, a frame-level autoregressive (AR) framework for real-time and interactive long video generation. Long video generation presents challenges in both efficiency and quality. Diffusion and Diffusion-Forcing models can produce high-quality videos but suffer from low efficiency due to bidirectional attention. Causal attention AR models support KV caching for faster inference, but often degrade in quality on long videos due to memory challenges during long-video training. In addition, beyond static prompt-based generation, interactive capabilities, such as streaming prompt inputs, are critical for dynamic content creation, enabling users to guide narratives in real time. This interactive requirement significantly increases complexity, especially in ensuring visual consistency and semantic coherence during prompt transitions. To address these challenges, LongLive adopts a causal, frame-level AR design that integrates a KV-recache mechanism that refreshes cached states with new prompts for smooth, adherent switches; streaming long tuning to enable long video training and to align training and inference (train-long-test-long); and short window attention paired with a frame-level attention sink, shorten as frame sink, preserving long-range consistency while enabling faster generation. With these key designs, LongLive fine-tunes a 1.3B-parameter short-clip model to minute-long generation in just 32 GPU-days. At inference, LongLive sustains 20.7 FPS on a single NVIDIA H100, achieves strong performance on VBench in both short and long videos. LongLive supports up to 240-second videos on a single H100 GPU. LongLive further supports INT8-quantized inference with only marginal quality loss.
AppAgent-Pro: A Proactive GUI Agent System for Multidomain Information Integration and User Assistance
Aug 27, 2025
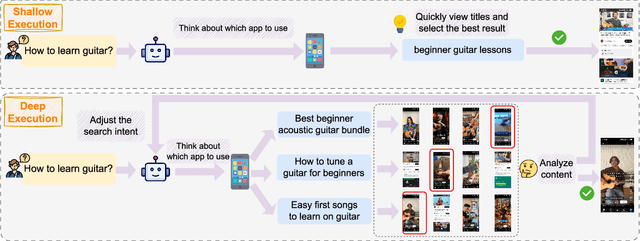


Large language model (LLM)-based agents have demonstrated remarkable capabilities in addressing complex tasks, thereby enabling more advanced information retrieval and supporting deeper, more sophisticated human information-seeking behaviors. However, most existing agents operate in a purely reactive manner, responding passively to user instructions, which significantly constrains their effectiveness and efficiency as general-purpose platforms for information acquisition. To overcome this limitation, this paper proposes AppAgent-Pro, a proactive GUI agent system that actively integrates multi-domain information based on user instructions. This approach enables the system to proactively anticipate users' underlying needs and conduct in-depth multi-domain information mining, thereby facilitating the acquisition of more comprehensive and intelligent information. AppAgent-Pro has the potential to fundamentally redefine information acquisition in daily life, leading to a profound impact on human society. Our code is available at: https://github.com/LaoKuiZe/AppAgent-Pro. The demonstration video could be found at: https://www.dropbox.com/scl/fi/hvzqo5vnusg66srydzixo/AppAgent-Pro-demo-video.mp4?rlkey=o2nlfqgq6ihl125mcqg7bpgqu&st=d29vrzii&dl=0.
SANA 1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformer
Jan 30, 2025



This paper presents SANA-1.5, a linear Diffusion Transformer for efficient scaling in text-to-image generation. Building upon SANA-1.0, we introduce three key innovations: (1) Efficient Training Scaling: A depth-growth paradigm that enables scaling from 1.6B to 4.8B parameters with significantly reduced computational resources, combined with a memory-efficient 8-bit optimizer. (2) Model Depth Pruning: A block importance analysis technique for efficient model compression to arbitrary sizes with minimal quality loss. (3) Inference-time Scaling: A repeated sampling strategy that trades computation for model capacity, enabling smaller models to match larger model quality at inference time. Through these strategies, SANA-1.5 achieves a text-image alignment score of 0.72 on GenEval, which can be further improved to 0.80 through inference scaling, establishing a new SoTA on GenEval benchmark. These innovations enable efficient model scaling across different compute budgets while maintaining high quality, making high-quality image generation more accessible.
GenXD: Generating Any 3D and 4D Scenes
Nov 05, 2024



Recent developments in 2D visual generation have been remarkably successful. However, 3D and 4D generation remain challenging in real-world applications due to the lack of large-scale 4D data and effective model design. In this paper, we propose to jointly investigate general 3D and 4D generation by leveraging camera and object movements commonly observed in daily life. Due to the lack of real-world 4D data in the community, we first propose a data curation pipeline to obtain camera poses and object motion strength from videos. Based on this pipeline, we introduce a large-scale real-world 4D scene dataset: CamVid-30K. By leveraging all the 3D and 4D data, we develop our framework, GenXD, which allows us to produce any 3D or 4D scene. We propose multiview-temporal modules, which disentangle camera and object movements, to seamlessly learn from both 3D and 4D data. Additionally, GenXD employs masked latent conditions to support a variety of conditioning views. GenXD can generate videos that follow the camera trajectory as well as consistent 3D views that can be lifted into 3D representations. We perform extensive evaluations across various real-world and synthetic datasets, demonstrating GenXD's effectiveness and versatility compared to previous methods in 3D and 4D generation.
TreeSBA: Tree-Transformer for Self-Supervised Sequential Brick Assembly
Jul 22, 2024



Inferring step-wise actions to assemble 3D objects with primitive bricks from images is a challenging task due to complex constraints and the vast number of possible combinations. Recent studies have demonstrated promising results on sequential LEGO brick assembly through the utilization of LEGO-Graph modeling to predict sequential actions. However, existing approaches are class-specific and require significant computational and 3D annotation resources. In this work, we first propose a computationally efficient breadth-first search (BFS) LEGO-Tree structure to model the sequential assembly actions by considering connections between consecutive layers. Based on the LEGO-Tree structure, we then design a class-agnostic tree-transformer framework to predict the sequential assembly actions from the input multi-view images. A major challenge of the sequential brick assembly task is that the step-wise action labels are costly and tedious to obtain in practice. We mitigate this problem by leveraging synthetic-to-real transfer learning. Specifically, our model is first pre-trained on synthetic data with full supervision from the available action labels. We then circumvent the requirement for action labels in the real data by proposing an action-to-silhouette projection that replaces action labels with input image silhouettes for self-supervision. Without any annotation on the real data, our model outperforms existing methods with 3D supervision by 7.8% and 11.3% in mIoU on the MNIST and ModelNet Construction datasets, respectively.