 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodiedSplat: Online Feed-Forward Semantic 3DGS for Open-Vocabulary 3D Scene Understanding
Mar 04, 2026Understanding a 3D scene immediately with its exploration is essential for embodied tasks, where an agent must construct and comprehend the 3D scene in an online and nearly real-time manner. In this study, we propose EmbodiedSplat, an online feed-forward 3DGS for open-vocabulary scene understanding that enables simultaneous online 3D reconstruction and 3D semantic understanding from the streaming images. Unlike existing open-vocabulary 3DGS methods which are typically restricted to either offline or per-scene optimization setting, our objectives are two-fold: 1) Reconstructs the semantic-embedded 3DGS of the entire scene from over 300 streaming images in an online manner. 2) Highly generalizable to novel scenes with feed-forward design and supports nearly real-time 3D semantic reconstruction when combined with real-time 2D models. To achieve these objectives, we propose an Online Sparse Coefficients Field with a CLIP Global Codebook where it binds the 2D CLIP embeddings to each 3D Gaussian while minimizing memory consumption and preserving the full semantic generalizability of CLIP. Furthermore, we generate 3D geometric-aware CLIP features by aggregating the partial point cloud of 3DGS through 3D U-Net to compensate the 3D geometric prior to 2D-oriented language embeddings. Extensive experiments on diverse indoor datasets, including ScanNet, ScanNet++, and Replica, demonstrate both the effectiveness and efficiency of our method. Check out our project page in https://0nandon.github.io/EmbodiedSplat/.
Segment Any Events with Language
Jan 30, 2026Scene understanding with free-form language has been widely explored within diverse modalities such as images, point clouds, and LiDAR. However, related studies on event sensors are scarce or narrowly centered on semantic-level understanding. We introduce SEAL, the first Semantic-aware Segment Any Events framework that addresses Open-Vocabulary Event Instance Segmentation (OV-EIS). Given the visual prompt, our model presents a unified framework to support both event segmentation and open-vocabulary mask classification at multiple levels of granularity, including instance-level and part-level. To enable thorough evaluation on OV-EIS, we curate four benchmarks that cover label granularity from coarse to fine class configurations and semantic granularity from instance-level to part-level understanding. Extensive experiments show that our SEAL largely outperforms proposed baselines in terms of performance and inference speed with a parameter-efficient architecture. In the Appendix, we further present a simple variant of our SEAL achieving generic spatiotemporal OV-EIS that does not require any visual prompts from users in the inference. Check out our project page in https://0nandon.github.io/SEAL
D3D-VLP: Dynamic 3D Vision-Language-Planning Model for Embodied Grounding and Navigation
Dec 14, 2025Embodied agents face a critical dilemma that end-to-end models lack interpretability and explicit 3D reasoning, while modular systems ignore cross-component interdependencies and synergies. To bridge this gap, we propose the Dynamic 3D Vision-Language-Planning Model (D3D-VLP). Our model introduces two key innovations: 1) A Dynamic 3D Chain-of-Thought (3D CoT) that unifies planning, grounding, navigation, and question answering within a single 3D-VLM and CoT pipeline; 2) A Synergistic Learning from Fragmented Supervision (SLFS) strategy, which uses a masked autoregressive loss to learn from massive and partially-annotated hybrid data. This allows different CoT components to mutually reinforce and implicitly supervise each other. To this end, we construct a large-scale dataset with 10M hybrid samples from 5K real scans and 20K synthetic scenes that are compatible with online learning methods such as RL and DAgger. Our D3D-VLP achieves state-of-the-art results on multiple benchmarks, including Vision-and-Language Navigation (R2R-CE, REVERIE-CE, NavRAG-CE), Object-goal Navigation (HM3D-OVON), and Task-oriented Sequential Grounding and Navigation (SG3D). Real-world mobile manipulation experiments further validate the effectiveness.
EarthSight: A Distributed Framework for Low-Latency Satellite Intelligence
Nov 13, 2025Low-latency delivery of satellite imagery is essential for time-critical applications such as disaster response, intelligence, and infrastructure monitoring. However, traditional pipelines rely on downlinking all captured images before analysis, introducing delays of hours to days due to restricted communication bandwidth. To address these bottlenecks, emerging systems perform onboard machine learning to prioritize which images to transmit. However, these solutions typically treat each satellite as an isolated compute node, limiting scalability and efficiency. Redundant inference across satellites and tasks further strains onboard power and compute costs, constraining mission scope and responsiveness. We present EarthSight, a distributed runtime framework that redefines satellite image intelligence as a distributed decision problem between orbit and ground. EarthSight introduces three core innovations: (1) multi-task inference on satellites using shared backbones to amortize computation across multiple vision tasks; (2) a ground-station query scheduler that aggregates user requests, predicts priorities, and assigns compute budgets to incoming imagery; and (3) dynamic filter ordering, which integrates model selectivity, accuracy, and execution cost to reject low-value images early and conserve resources. EarthSight leverages global context from ground stations and resource-aware adaptive decisions in orbit to enable constellations to perform scalable, low-latency image analysis within strict downlink bandwidth and onboard power budgets. Evaluations using a prior established satellite simulator show that EarthSight reduces average compute time per image by 1.9x and lowers 90th percentile end-to-end latency from first contact to delivery from 51 to 21 minutes compared to the state-of-the-art baseline.
PDEfuncta: Spectrally-Aware Neural Representation for PDE Solution Modeling
Jun 15, 2025Scientific machine learning often involves representing complex solution fields that exhibit high-frequency features such as sharp transitions, fine-scale oscillations, and localized structures. While implicit neural representations (INRs) have shown promise for continuous function modeling, capturing such high-frequency behavior remains a challenge-especially when modeling multiple solution fields with a shared network. Prior work addressing spectral bias in INRs has primarily focused on single-instance settings, limiting scalability and generalization. In this work, we propose Global Fourier Modulation (GFM), a novel modulation technique that injects high-frequency information at each layer of the INR through Fourier-based reparameterization. This enables compact and accurate representation of multiple solution fields using low-dimensional latent vectors. Building upon GFM, we introduce PDEfuncta, a meta-learning framework designed to learn multi-modal solution fields and support generalization to new tasks. Through empirical studies on diverse scientific problems, we demonstrate that our method not only improves representational quality but also shows potential for forward and inverse inference tasks without the need for retraining.
Dynam3D: Dynamic Layered 3D Tokens Empower VLM for Vision-and-Language Navigation
May 16, 2025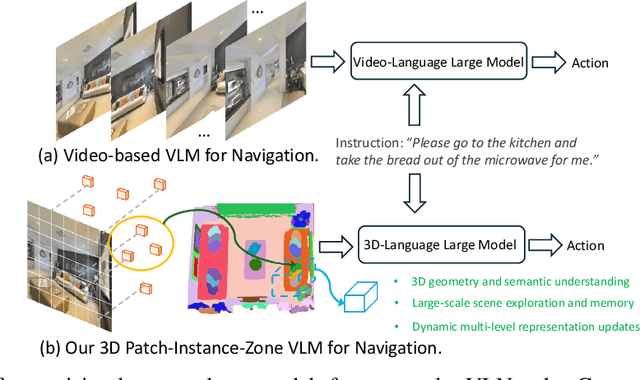
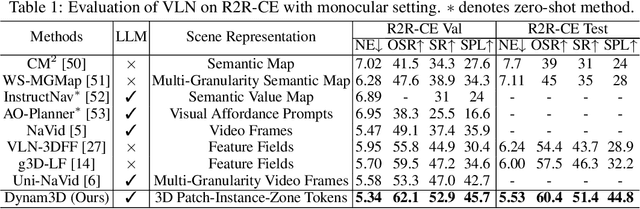
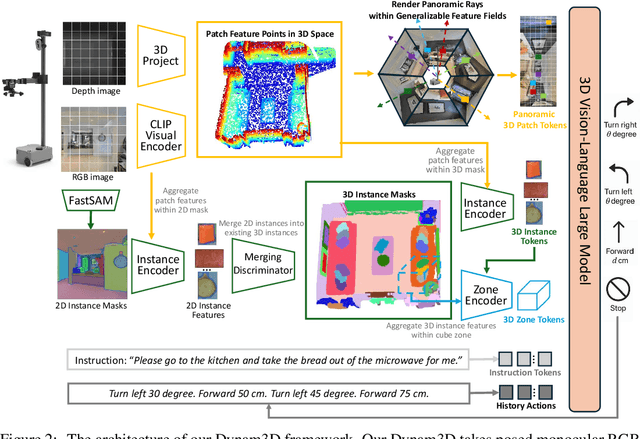

Vision-and-Language Navigation (VLN) is a core task where embodied agents leverage their spatial mobility to navigate in 3D environments toward designated destinations based on natural language instructions. Recently, video-language large models (Video-VLMs) with strong generalization capabilities and rich commonsense knowledge have shown remarkable performance when applied to VLN tasks. However, these models still encounter the following challenges when applied to real-world 3D navigation: 1) Insufficient understanding of 3D geometry and spatial semantics; 2) Limited capacity for large-scale exploration and long-term environmental memory; 3) Poor adaptability to dynamic and changing environments.To address these limitations, we propose Dynam3D, a dynamic layered 3D representation model that leverages language-aligned, generalizable, and hierarchical 3D representations as visual input to train 3D-VLM in navigation action prediction. Given posed RGB-D images, our Dynam3D projects 2D CLIP features into 3D space and constructs multi-level 3D patch-instance-zone representations for 3D geometric and semantic understanding with a dynamic and layer-wise update strategy. Our Dynam3D is capable of online encoding and localization of 3D instances, and dynamically updates them in changing environments to provide large-scale exploration and long-term memory capabilities for navigation. By leveraging large-scale 3D-language pretraining and task-specific adaptation, our Dynam3D sets new state-of-the-art performance on VLN benchmarks including R2R-CE, REVERIE-CE and NavRAG-CE under monocular settings. Furthermore, experiments for pre-exploration, lifelong memory, and real-world robot validate the effectiveness of practical deployment.
MolMole: Molecule Mining from Scientific Literature
May 08, 2025The extraction of molecular structures and reaction data from scientific documents is challenging due to their varied, unstructured chemical formats and complex document layouts. To address this, we introduce MolMole, a vision-based deep learning framework that unifies molecule detection, reaction diagram parsing, and optical chemical structure recognition (OCSR) into a single pipeline for automating the extraction of chemical data directly from page-level documents. Recognizing the lack of a standard page-level benchmark and evaluation metric, we also present a testset of 550 pages annotated with molecule bounding boxes, reaction labels, and MOLfiles, along with a novel evaluation metric. Experimental results demonstrate that MolMole outperforms existing toolkits on both our benchmark and public datasets. The benchmark testset will be publicly available, and the MolMole toolkit will be accessible soon through an interactive demo on the LG AI Research website. For commercial inquiries, please contact us at \href{mailto:contact_ddu@lgresearch.ai}{contact\_ddu@lgresearch.ai}.
SCENT: Robust Spatiotemporal Learning for Continuous Scientific Data via Scalable Conditioned Neural Fields
Apr 16, 2025Spatiotemporal learning is challenging due to the intricate interplay between spatial and temporal dependencies, the high dimensionality of the data, and scalability constraints. These challenges are further amplified in scientific domains, where data is often irregularly distributed (e.g., missing values from sensor failures) and high-volume (e.g., high-fidelity simulations), posing additional computational and modeling difficulties. In this paper, we present SCENT, a novel framework for scalable and continuity-informed spatiotemporal representation learning. SCENT unifies interpolation, reconstruction, and forecasting within a single architecture. Built on a transformer-based encoder-processor-decoder backbone, SCENT introduces learnable queries to enhance generalization and a query-wise cross-attention mechanism to effectively capture multi-scale dependencies. To ensure scalability in both data size and model complexity, we incorporate a sparse attention mechanism, enabling flexible output representations and efficient evaluation at arbitrary resolutions. We validate SCENT through extensive simulations and real-world experiments, demonstrating state-of-the-art performance across multiple challenging tasks while achieving superior scalability.
DiET-GS: Diffusion Prior and Event Stream-Assisted Motion Deblurring 3D Gaussian Splatting
Mar 31, 2025Reconstructing sharp 3D representations from blurry multi-view images are long-standing problem in computer vision. Recent works attempt to enhance high-quality novel view synthesis from the motion blur by leveraging event-based cameras, benefiting from high dynamic range and microsecond temporal resolution. However, they often reach sub-optimal visual quality in either restoring inaccurate color or losing fine-grained details. In this paper, we present DiET-GS, a diffusion prior and event stream-assisted motion deblurring 3DGS. Our framework effectively leverages both blur-free event streams and diffusion prior in a two-stage training strategy. Specifically, we introduce the novel framework to constraint 3DGS with event double integral, achieving both accurate color and well-defined details. Additionally, we propose a simple technique to leverage diffusion prior to further enhance the edge details. Qualitative and quantitative results on both synthetic and real-world data demonstrate that our DiET-GS is capable of producing significantly better quality of novel views compared to the existing baselines. Our project page is https://diet-gs.github.io
ImagePiece: Content-aware Re-tokenization for Efficient Image Recognition
Dec 21, 2024



Vision Transformers (ViTs) have achieved remarkable success in various computer vision tasks. However, ViTs have a huge computational cost due to their inherent reliance on multi-head self-attention (MHSA), prompting efforts to accelerate ViTs for practical applications. To this end, recent works aim to reduce the number of tokens, mainly focusing on how to effectively prune or merge them. Nevertheless, since ViT tokens are generated from non-overlapping grid patches, they usually do not convey sufficient semantics, making it incompatible with efficient ViTs. To address this, we propose ImagePiece, a novel re-tokenization strategy for Vision Transformers. Following the MaxMatch strategy of NLP tokenization, ImagePiece groups semantically insufficient yet locally coherent tokens until they convey meaning. This simple retokenization is highly compatible with previous token reduction methods, being able to drastically narrow down relevant tokens, enhancing the inference speed of DeiT-S by 54% (nearly 1.5$\times$ faster) while achieving a 0.39% improvement in ImageNet classification accuracy. For hyper-speed inference scenarios (with 251% acceleration), our approach surpasses other baselines by an accuracy over 8%.